标签:
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值,字符串,布尔型)。DateFrame既有行索引也有列索引,可以被看作为由Series组成的字典。
构建DataFrame:
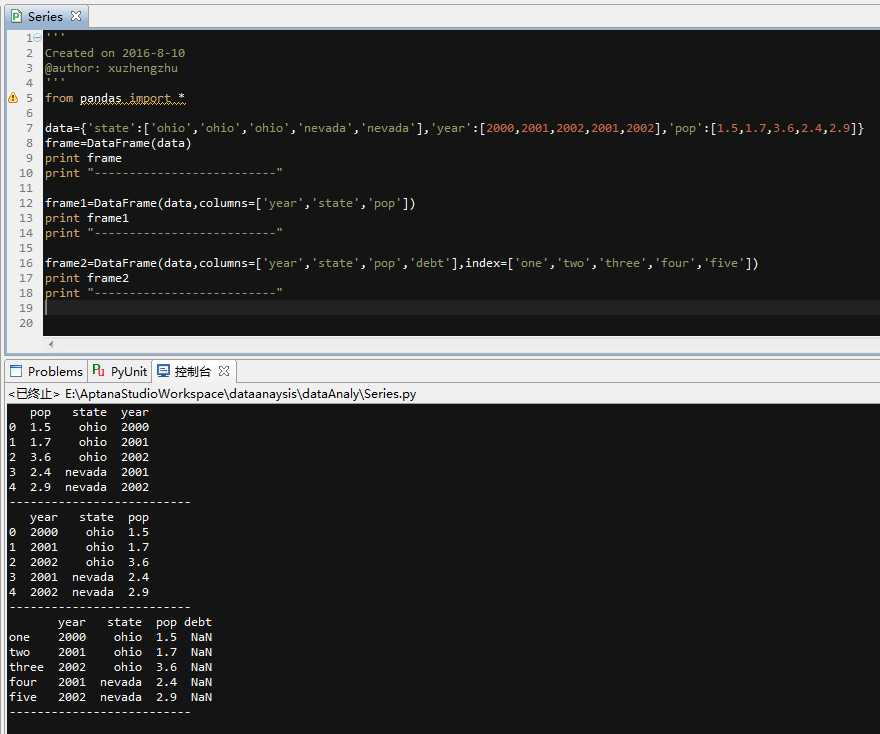
1.1、直接传入一个由等长列表或numpy数组组成的字典

‘‘‘ Created on 2016-8-10 @author: xuzhengzhu ‘‘‘ from pandas import * data={‘state‘:[‘ohio‘,‘ohio‘,‘ohio‘,‘nevada‘,‘nevada‘],‘year‘:[2000,2001,2002,2001,2002],‘pop‘:[1.5,1.7,3.6,2.4,2.9]} frame=DataFrame(data) print frame print "--------------------------" #可指定序列,DataFrame的列会按照指定的顺序进行排列 frame1=DataFrame(data,columns=[‘year‘,‘state‘,‘pop‘]) print frame1 print "--------------------------" #如果传入的数据找不到,就会NA值 frame2=DataFrame(data,columns=[‘year‘,‘state‘,‘pop‘,‘debt‘],index=[‘one‘,‘two‘,‘three‘,‘four‘,‘five‘]) print frame2 print "--------------------------"
1.2 对属性进行操作
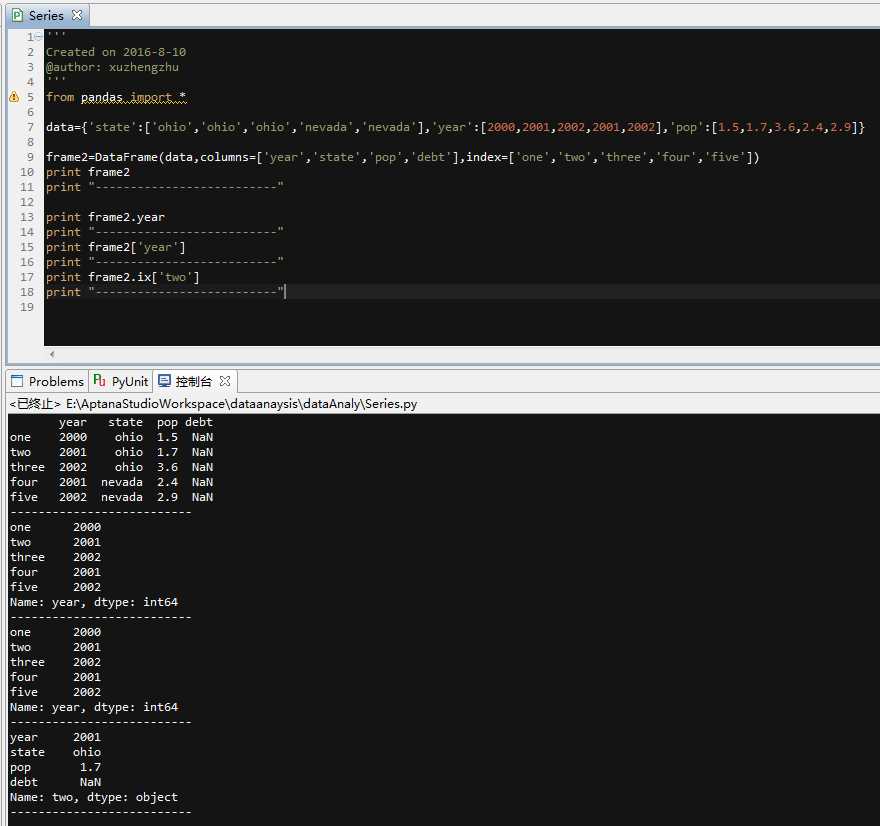
‘‘‘ Created on 2016-8-10 @author: xuzhengzhu ‘‘‘ from pandas import * data={‘state‘:[‘ohio‘,‘ohio‘,‘ohio‘,‘nevada‘,‘nevada‘],‘year‘:[2000,2001,2002,2001,2002],‘pop‘:[1.5,1.7,3.6,2.4,2.9]} frame2=DataFrame(data,columns=[‘year‘,‘state‘,‘pop‘,‘debt‘],index=[‘one‘,‘two‘,‘three‘,‘four‘,‘five‘]) print frame2 print "--------------------------" print frame2.year print "--------------------------" print frame2[‘year‘] print "--------------------------" print frame2.ix[‘two‘] print "--------------------------"
#通过类似字典标记的方式或属性的方式,可,以将DataFrame的列获取为一个Series,返回的Series与原来有相同的索引,且name属性已指定
#行也可以通过位置或名称的方式进行获取比如索引字段ix
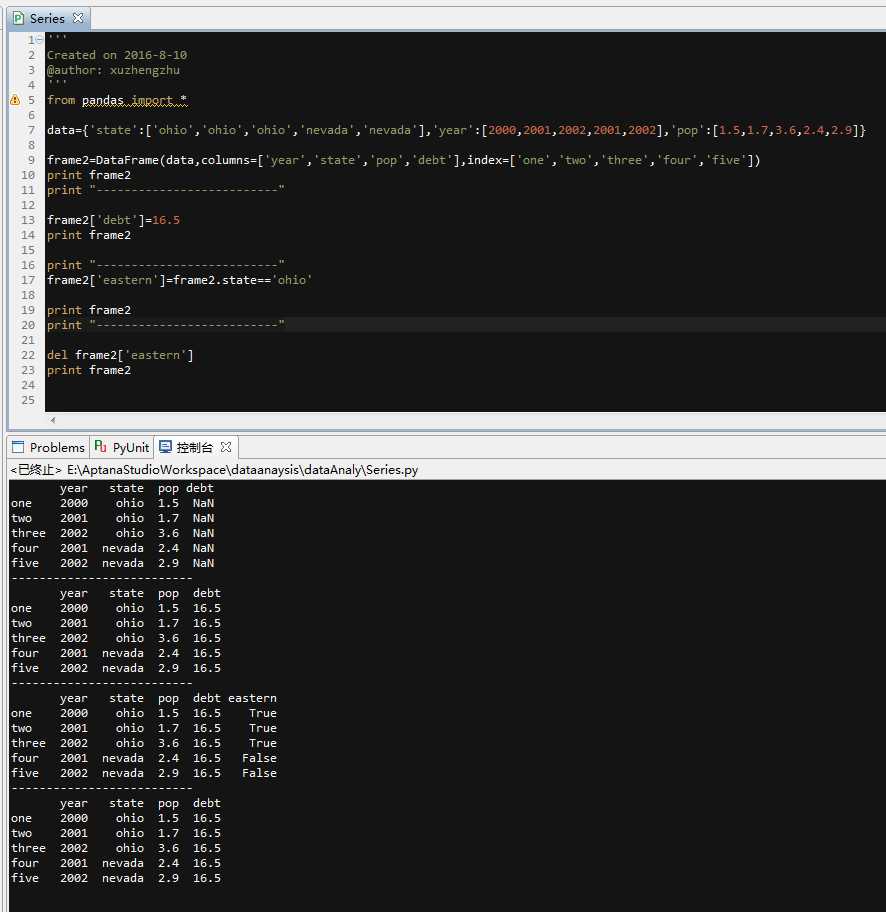
1.3 对DataFrame列进行操作
‘‘‘ Created on 2016-8-10 @author: xuzhengzhu ‘‘‘ from pandas import * data={‘state‘:[‘ohio‘,‘ohio‘,‘ohio‘,‘nevada‘,‘nevada‘],‘year‘:[2000,2001,2002,2001,2002],‘pop‘:[1.5,1.7,3.6,2.4,2.9]} frame2=DataFrame(data,columns=[‘year‘,‘state‘,‘pop‘,‘debt‘],index=[‘one‘,‘two‘,‘three‘,‘four‘,‘five‘]) print frame2 print "--------------------------" #列可以通过赋值的方式进行修改 frame2[‘debt‘]=16.5 print frame2 #为不存在的列赋值会创建出一个新列 print "--------------------------" frame2[‘eastern‘]=frame2.state==‘ohio‘ print frame2 print "--------------------------" #关键词del用于删除列 del frame2[‘eastern‘] print frame2
python数据分析之pandas库的DataFrame应用
标签:
原文地址:http://www.cnblogs.com/HondaHsu/p/5757584.html
