标签:des blog http os io strong for 2014
11年的blog.
Facebook Messages seamlessly integrates many communication channels: email, SMS, Facebook Chat, and the existing Facebook Inbox. Combining all this functionality and offering a powerful user experience involved building an entirely new infrastructure stack from the ground up.
To simplify the product and present a powerful user experience, integrating and supporting all the above communication channels requires a number of services to run together and interact. The system needs to:
To overcome all these challenges, we started laying down a new architecture. At the heart of the application back end are the application servers. Application servers are responsible for answering all queries and take all the writes into the system. They also interact with a number of services to achieve this.
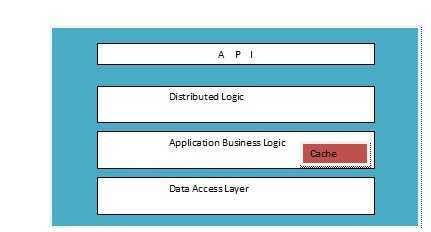
Each application server comprises:
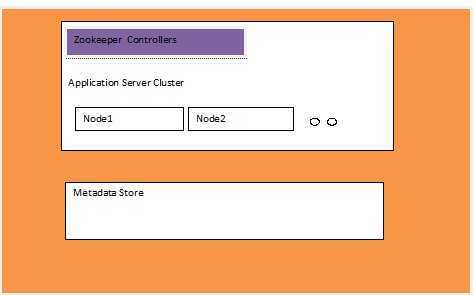
Cells give us many advantages:
Each cell consists of a single cluster of application servers, and each application server cluster is controlled by a set of ZooKeeper machines.
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications.
ZooKeeper is open source software that we use mainly for two purposes: as the controller for implementing sharding and failover of application servers, and as a store for our discovery service. Since ZooKeeper provides us with a highly available repository and notification mechanism, it goes a long way towards helping us build a highly available service.
Each application server registers itself in ZooKeeper by generating N tokens. The server uses these tokens to take N virtual positions on a consistent hash ring. This is used to shard users across these nodes. In case of failures, the neighboring nodes take over the load for those users, hence distributing the load evenly. This also allows for easy addition and removal of nodes into and from the application server cluster.
Finally, the whole system has a number of cells, and looks like this:
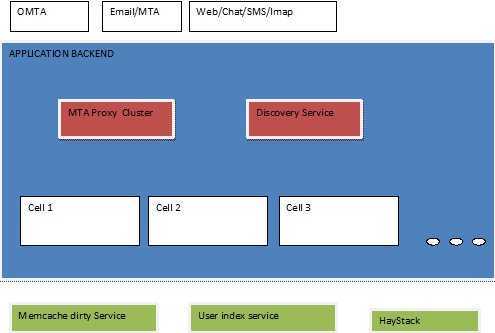
The Messages application back end needs to parse email messages and attachments, and also provide discovery of the right application servers for the given user. This is achieved with the following services:
The Messages application back end also relies on the following services:
The clients of the application back end system include MTAs for email traffic, IMAP, Web servers, SMS client, and Web Chat clients. Apart from the MTAs, which talk to the MTA proxy, all other clients talk directly to the application servers.
Given that we built this services infrastructure from scratch, one of the most important things was to have the appropriate tools and monitoring in place to push this software on almost a daily basis without any service disruption. So we ended up building a number of useful tools that can give us a view of the various cells, enable/disable cells, manage addition and removal of hardware, do rolling deployments without disrupting service, and give us a view of the performance and bottlenecks in various parts of the system.
All these services need to work in tandem and be available and reliable for messaging to work. We are in the process of importing millions of users into this system every day. Very soon every Facebook user will have access to the new Messages product.
At Facebook, taking on big challenges is the norm. Building this infrastructure and getting it up and running is a prime example of this. A lot of sweat has gone into bringing this to production. I would like to thank every individual who has contributed to this effort and are continuing to do so. This effort involved not only the Messages team but also a number of interns and various teams across the company.
We spent a few weeks setting up a test framework to evaluate clusters of MySQL, Apache Cassandra, Apache HBase, and a couple of other systems. We ultimately chose HBase. MySQL proved to not handle the long tail of data well; as indexes and data sets grew large, performance suffered. We found Cassandra‘s eventual consistency model to be a difficult pattern to reconcile for our new Messages infrastructure.
HBase comes with very good scalability and performance for this workload and a simpler consistency model than Cassandra. While we’ve done a lot of work on HBase itself over the past year, when we started we also found it to be the most feature rich in terms of our requirements (auto load balancing and failover, compression support, multiple shards per server, etc.). HDFS, the underlying filesystem used by HBase, provides several nice features such as replication, end-to-end checksums, and automatic rebalancing. Additionally, our technical teams already had a lot of development and operational expertise in HDFS from data processing with Hadoop. Since we started working on HBase, we‘ve been focused on committing our changes back to HBase itself and working closely with the community. The open source release of HBase is what we’re running today.
Scaling the Messages Application Back End 【转】,布布扣,bubuko.com
Scaling the Messages Application Back End 【转】
标签:des blog http os io strong for 2014
原文地址:http://www.cnblogs.com/linyx/p/3899050.html