标签:
所谓爬取其实就是获取链接的内容保存到本地。所以爬之前需要先知道要爬的链接是什么。
要爬取的页面是这个:http://findicons.com/pack/2787/beautiful_flat_icons
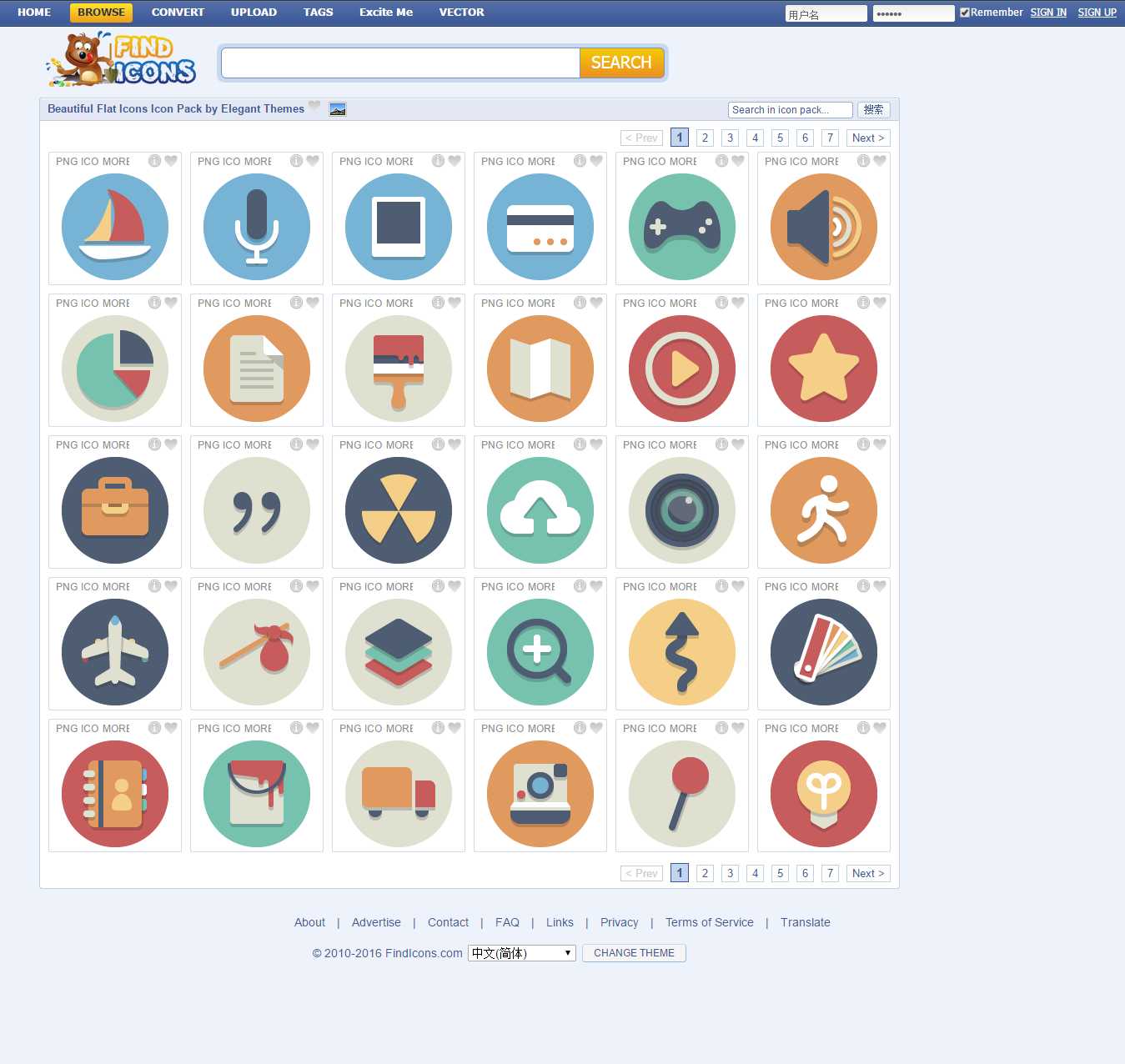
里面有很多不错的图标,目标就是把这些文件图片爬下来,保存成本地图片。
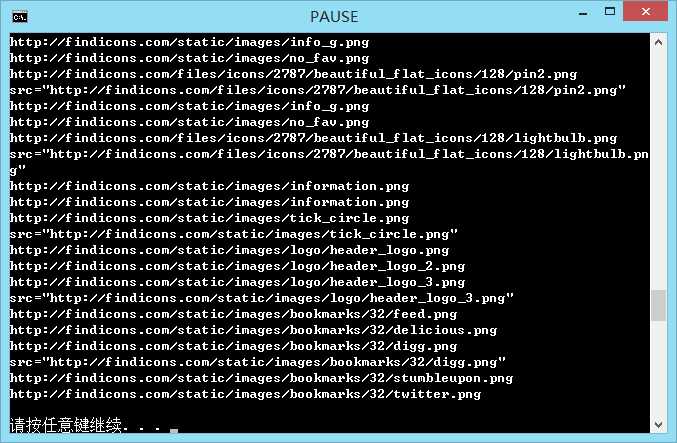
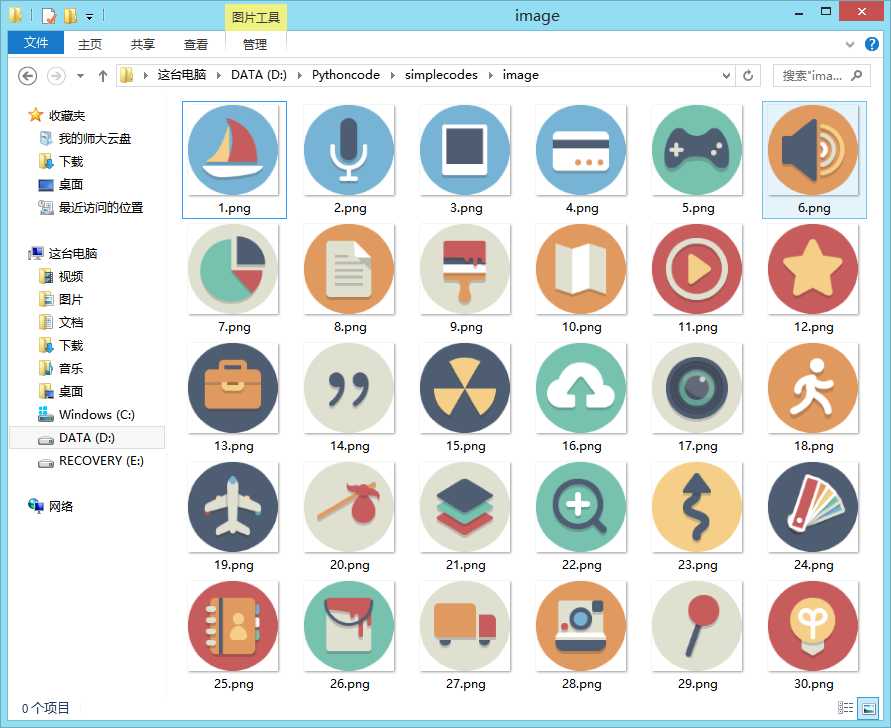
用python3怎么做呢?
第一步:获取要爬取的母网页的内容
import urllib.request import re url = "http://findicons.com/pack/2787/beautiful_flat_icons" webPage=urllib.request.urlopen(url) data = webPage.read() data = data.decode(‘UTF-8‘)
第二步:对母网页内容处理,提取出里面的图片链接
k = re.split(r‘\s+‘,data) s = [] sp = [] si = [] for i in k : if (re.match(r‘src‘,i) or re.match(r‘href‘,i)): if (not re.match(r‘href="#"‘,i)): if (re.match(r‘.*?png"‘,i) or re.match(r‘.*?ico"‘,i)): if (re.match(r‘src‘,i)): s.append(i) for it in s : if (re.match(r‘.*?png"‘,it)): sp.append(it)
第三步:获取这些图片链接的内容,并保存成本地图片
cnt = 0 cou = 1 for it in sp: m = re.search(r‘src="(.*?)"‘,it) iturl = m.group(1) print(iturl) if (iturl[0]==‘/‘): continue; web = urllib.request.urlopen(iturl) itdata = web.read() if (cnt%3==1 and cnt>=4 and cou<=30): f = open(‘d:/pythoncode/simplecodes/image/‘+str(cou)+‘.png‘,"wb") cou = cou+1 f.write(itdata) f.close() print(it) cnt = cnt+1
保存目录可以自行设定。
以下是综合起来的代码:
import urllib.request import re url = "http://findicons.com/pack/2787/beautiful_flat_icons" webPage=urllib.request.urlopen(url) data = webPage.read() data = data.decode(‘UTF-8‘) k = re.split(r‘\s+‘,data) s = [] sp = [] si = [] for i in k : if (re.match(r‘src‘,i) or re.match(r‘href‘,i)): if (not re.match(r‘href="#"‘,i)): if (re.match(r‘.*?png"‘,i) or re.match(r‘.*?ico"‘,i)): if (re.match(r‘src‘,i)): s.append(i) for it in s : if (re.match(r‘.*?png"‘,it)): sp.append(it) cnt = 0 cou = 1 for it in sp: m = re.search(r‘src="(.*?)"‘,it) iturl = m.group(1) print(iturl) if (iturl[0]==‘/‘): continue; web = urllib.request.urlopen(iturl) itdata = web.read() if (cnt%3==1 and cnt>=4 and cou<=30): f = open(‘d:/pythoncode/simplecodes/image/‘+str(cou)+‘.png‘,"wb") cou = cou+1 f.write(itdata) f.close() print(it) cnt = cnt+1
标签:
原文地址:http://www.cnblogs.com/itlqs/p/5767054.html