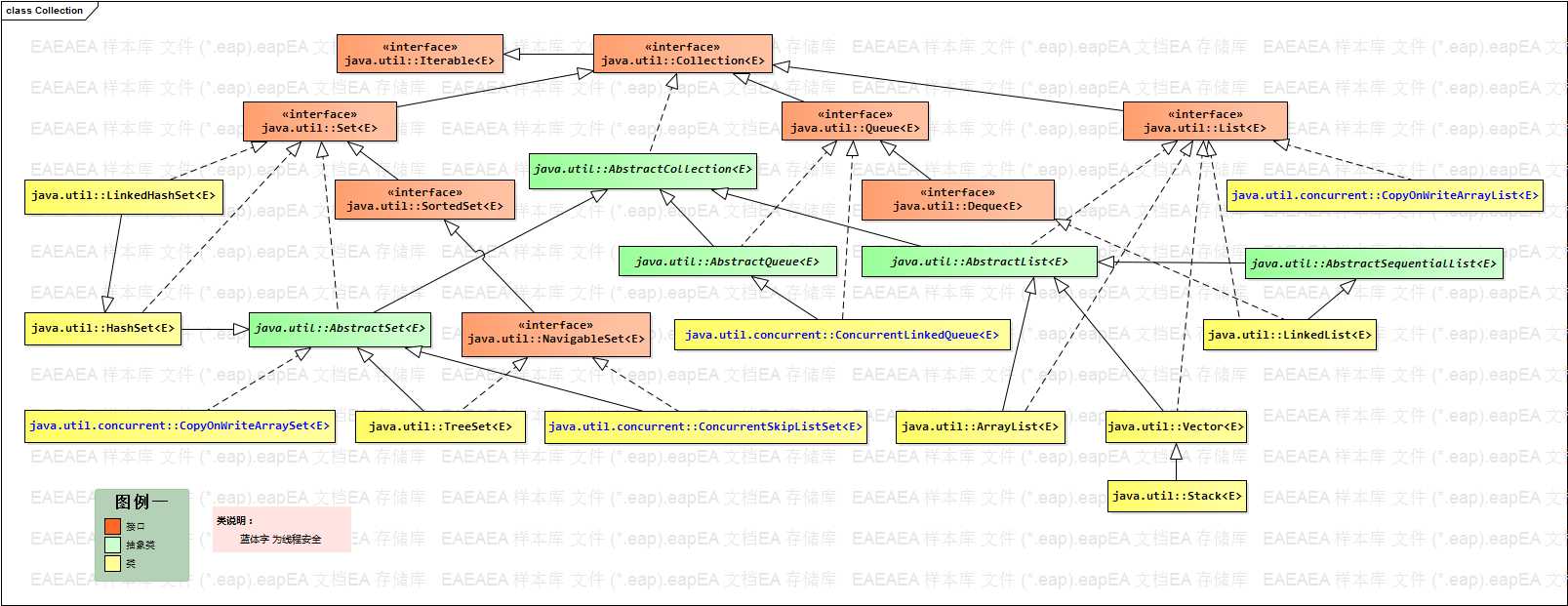
标签:
此图是 java 中 Collection 相关的接口与类的关系的类图。其中,类只是集合框架的一部分,比较常用的一部分。
第一次画类图,着实很费劲,不过收获也不小。
下面是相关接口和类的解释说明。文字来自 JDK API 1.6 中文版。原谅我的懒惰,实在不想自己写,太麻烦。如有错误,还请指正。
如图,Set、Queue、List 接口都继承自 Collection 接口。
AbstractCollection<E>
此类提供 Collection 接口的骨干实现,以最大限度地减少了实现此接口所需的工作。
要实现一个不可修改的 collection,编程人员只需扩展此类,并提供 iterator 和 size 方法的实现。(iterator 方法返回的迭代器必须实现 hasNext 和 next。)
要实现可修改的 collection,编程人员必须另外重写此类的 add 方法(否则,会抛出 UnsupportedOperationException),iterator 方法返回的迭代器还必须另外实现其 remove 方法。
按照 Collection 接口规范中的建议,编程人员通常应提供一个 void (无参数)和 Collection 构造方法。
Set
一个不包含重复元素的 collection。更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。
注:如果将可变对象用作 set 元素,那么必须极其小心。如果对象是 set 中某个元素,以一种影响 equals 比较的方式改变对象的值,那么 set 的行为就是不确定的。此项禁止的一个特殊情况是不允许某个 set 包含其自身作为元素。
HashSet
此类实现 Set 接口,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
此类为基本操作提供了稳定性能,这些基本操作包括 add、remove、contains 和 size,假定哈希函数将这些元素正确地分布在桶中。对此 set 进行迭代所需的时间与 HashSet 实例的大小(元素的数量)和底层 HashMap 实例(桶的数量)的“容量”的和成比例。因此,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
注意,此实现不是同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器在尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测 bug。
具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。此实现与 HashSet 的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。注意,插入顺序不 受在 set 中重新插入的 元素的影响。(如果在 s.contains(e) 返回 true 后立即调用 s.add(e),则元素 e 会被重新插入到 set s 中。)
此类提供所有可选的 Set 操作,并且允许 null 元素。与 HashSet 一样,它可以为基本操作(add、contains 和 remove)提供稳定的性能,假定哈希函数将元素正确地分布到存储段中。由于增加了维护链接列表的开支,其性能很可能会比 HashSet 稍逊一筹,不过,这一点例外:LinkedHashSet 迭代所需时间与 set 的大小 成正比,而与容量无关。HashSet 迭代很可能支出较大,因为它所需迭代时间与其容量 成正比。
链接的哈希 set 有两个影响其性能的参数:初始容量 和加载因子。它们与 HashSet 中的定义极其相同。注意,为初始容量选择非常高的值对此类的影响比对 HashSet 要小,因为此类的迭代时间不受容量的影响。
注意,
此实现不是同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new LinkedHashSet(...));
注意,迭代器的快速失败行为不能得到保证,一般来说,存在不同步的并发修改时,不可能作出任何强有力的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的方式是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。
TreeSet
基于 TreeMap 的 NavigableSet 实现。使用元素的自然顺序对元素进行排序,或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。
此实现为基本操作(add、remove 和 contains)提供受保证的 log(n) 时间开销。
注意,如果要正确实现 Set 接口,则 set 维护的顺序(无论是否提供了显式比较器)必须与 equals 一致。(关于与 equals 一致 的精确定义,请参阅 Comparable 或 Comparator。)这是因为 Set 接口是按照 equals 操作定义的,但 TreeSet 实例使用它的 compareTo(或 compare)方法对所有元素进行比较,因此从 set 的观点来看,此方法认为相等的两个元素就是相等的。即使 set 的顺序与 equals 不一致,其行为也是 定义良好的;它只是违背了 Set 接口的常规协定。
注意,此实现不是同步的。如果多个线程同时访问一个 TreeSet,而其中至少一个线程修改了该 set,那么它必须 外部同步。这一般是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSortedSet 方法来“包装”该 set。此操作最好在创建时进行,以防止对 set 的意外非同步访问:
Set s = Collections.synchronizedSet(new TreeSet(...));
注意,迭代器的快速失败行为无法得到保证,一般来说,存在不同步的并发修改时,不可能作出任何肯定的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测 bug。
CopyOnWriteArraySet
对其所有操作使用内部 CopyOnWriteArrayList 的 Set。因此,它共享以下相同的基本属性:
1、它最适合于具有以下特征的应用程序:set 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2、它是线程安全的。
3、因为通常需要复制整个基础数组,所以可变操作(add、set 和 remove 等等)的开销很大。
4、迭代器不支持可变 remove 操作。
5、使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
一个基于 ConcurrentSkipListMap 的可缩放并发 NavigableSet 实现。set 的元素可以根据它们的自然顺序进行排序,也可以根据创建 set 时所提供的 Comparator 进行排序,具体取决于使用的构造方法。
此实现为 contains、add、remove 操作及其变体提供预期平均 log(n) 时间开销。多个线程可以安全地并发执行插入、移除和访问操作。迭代器是弱一致的,返回的元素将反映迭代器创建时或创建后某一时刻的 set 状态。它们不抛出 ConcurrentModificationException,可以并发处理其他操作。升序排序视图及其迭代器比降序排序视图及其迭代器更快。
请注意,与在大多数 collection 中不同,这里的 size 方法不是一个固定时间 (constant-time) 操作。由于这些 set 的异步特性,确定元素的当前数目需要遍历元素。此外,批量操作 addAll、removeAll、retainAll 和 containsAll 并不 保证能以原子方式 (atomically) 执行。例如,与 addAll 操作一起并发操作的迭代器只能查看某些附加元素。
此类及其迭代器实现 Set 和 Iterator 接口的所有可选方法。与大多数其他并发 collection 实现一样,此类不允许使用 null 元素,因为无法可靠地将 null 参数及返回值与不存在的元素区分开来。
Queue
在处理元素前用于保存元素的 collection。除了基本的 Collection 操作外,队列还提供其他的插入、提取和检查操作。每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。插入操作的后一种形式是用于专门为有容量限制的 Queue 实现设计的;在大多数实现中,插入操作不会失败。
队列通常(但并非一定)以 FIFO(先进先出)的方式排序各个元素。不过优先级队列和 LIFO 队列(或堆栈)例外,前者根据提供的比较器或元素的自然顺序对元素进行排序,后者按 LIFO(后进先出)的方式对元素进行排序。无论使用哪种排序方式,队列的头 都是调用 remove() 或 poll() 所移除的元素。在 FIFO 队列中,所有的新元素都插入队列的末尾。其他种类的队列可能使用不同的元素放置规则。每个 Queue 实现必须指定其顺序属性。
Queue 实现通常不允许插入 null 元素,尽管某些实现(如 LinkedList)并不禁止插入 null。即使在允许 null 的实现中,也不应该将 null 插入到 Queue 中,因为 null 也用作 poll 方法的一个特殊返回值,表明队列不包含元素。
Queue 实现通常未定义 equals 和 hashCode 方法的基于元素的版本,而是从 Object 类继承了基于身份的版本,因为对于具有相同元素但有不同排序属性的队列而言,基于元素的相等性并非总是定义良好的。
ConcurrentLinkedQueue
一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素。
内存一致性效果:当存在其他并发 collection 时,将对象放入 ConcurrentLinkedQueue 之前的线程中的操作 happen-before 随后通过另一线程从 ConcurrentLinkedQueue 访问或移除该元素的操作。
List
有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
与 set 不同,列表通常允许重复的元素。更确切地讲,列表通常允许满足 e1.equals(e2) 的元素对 e1 和 e2,并且如果列表本身允许 null 元素的话,通常它们允许多个 null 元素。难免有人希望通过在用户尝试插入重复元素时抛出运行时异常的方法来禁止重复的列表,但我们希望这种用法越少越好。
注意:尽管列表允许把自身作为元素包含在内,但建议要特别小心:在这样的列表上,equals 和 hashCode 方法不再是定义良好的。
ArrayList
List 接口的大小可变数组的实现。实现了所有可选列表操作,并允许包括 null 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。(此类大致上等同于 Vector 类,除了此类是不同步的。)
size、isEmpty、get、set、iterator 和 listIterator 操作都以固定时间运行。add 操作以分摊的固定时间 运行,也就是说,添加 n 个元素需要 O(n) 时间。其他所有操作都以线性时间运行(大体上讲)。与用于 LinkedList 实现的常数因子相比,此实现的常数因子较低。
每个 ArrayList 实例都有一个容量。该容量是指用来存储列表元素的数组的大小。它总是至少等于列表的大小。随着向 ArrayList 中不断添加元素,其容量也自动增长。并未指定增长策略的细节,因为这不只是添加元素会带来分摊固定时间开销那样简单。
在添加大量元素前,应用程序可以使用 ensureCapacity 操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。
注意,此实现不是同步的。
LinkedList
List 接口的链接列表实现。实现所有可选的列表操作,并且允许所有元素(包括 null)。除了实现 List 接口外,LinkedList 类还为在列表的开头及结尾 get、remove 和 insert 元素提供了统一的命名方法。这些操作允许将链接列表用作堆栈、队列或双端队列。
此类实现 Deque 接口,为 add、poll 提供先进先出队列操作,以及其他堆栈和双端队列操作。
所有操作都是按照双重链接列表的需要执行的。在列表中编索引的操作将从开头或结尾遍历列表(从靠近指定索引的一端)。
注意,此实现不是同步的。
CopyOnWriteArrayList
ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。
这一般需要很大的开销,但是当遍历操作的数量大大超过可变操作的数量时,这种方法可能比其他替代方法更有效。在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时,它也很有用。“快照”风格的迭代器方法在创建迭代器时使用了对数组状态的引用。此数组在迭代器的生存期内不会更改,因此不可能发生冲突,并且迭代器保证不会抛出 ConcurrentModificationException。创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改。在迭代器上进行的元素更改操作(remove、set 和 add)不受支持。这些方法将抛出 UnsupportedOperationException。
允许使用所有元素,包括 null。
内存一致性效果:当存在其他并发 collection 时,将对象放入 CopyOnWriteArrayList 之前的线程中的操作 happen-before 随后通过另一线程从 CopyOnWriteArrayList 中访问或移除该元素的操作。
Vector
Vector 类可以实现可增长的对象数组。与数组一样,它包含可以使用整数索引进行访问的组件。但是,Vector 的大小可以根据需要增大或缩小,以适应创建 Vector 后进行添加或移除项的操作。
每个向量会试图通过维护 capacity 和 capacityIncrement 来优化存储管理。capacity 始终至少应与向量的大小相等;这个值通常比后者大些,因为随着将组件添加到向量中,其存储将按 capacityIncrement 的大小增加存储块。应用程序可以在插入大量组件前增加向量的容量;这样就减少了增加的重分配的量。
Stack
Stack 类表示后进先出(LIFO)的对象堆栈。它通过五个操作对类 Vector 进行了扩展 ,允许将向量视为堆栈。它提供了通常的 push 和 pop 操作,以及取堆栈顶点的 peek 方法、测试堆栈是否为空的 empty 方法、在堆栈中查找项并确定到堆栈顶距离的 search 方法。
首次创建堆栈时,它不包含项。
Deque 接口及其实现提供了 LIFO 堆栈操作的更完整和更一致的 set,应该优先使用此 set,而非此类。例如:
Deque<Integer> stack = new ArrayDeque<Integer>();
Java 集合框架之Collection
标签:
原文地址:http://www.cnblogs.com/LeslieXia/p/5770330.html