标签:
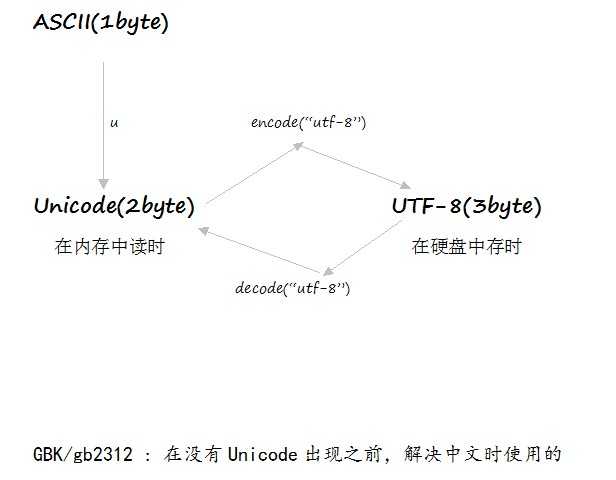
获取一个字符的ASCII码值,使用内置函数 ord(),ASCII码占一个字节 ascii不能存中文
>>> # A 和 a 分别的对应的ASCII码值是 >>> ord(‘A‘) 65 >>> ord(‘a‘) 97 >>>
Unicode占2个字节,它是可以存中文的,不管是英文还是中文均存储为2个字节
# Python3.5 >>> name = u‘范特西‘ >>> name ‘范特西‘ >>> type(name) <class ‘str‘> >>>
# Python2.7 >>> name = u‘范特西‘ >>> name u‘\u8303\u7279\u897f‘ >>> type(name) <type ‘unicode‘> >>>
Utf-8占3个字节, 如果是英文就占1个字节,如果是中文就占3个字节,utf-8是解决Unicode存储英文占容量大的问题
>>> name = name.encode(‘utf-8‘) >>> len(name) 9 >>> name b‘\xe8\x8c\x83\xe7\x89\xb9\xe8\xa5\xbf‘ >>>
>>> name = u‘博尔特‘ >>> name = name.encode(‘utf-8‘) >>> name b‘\xe5\x8d\x9a\xe5\xb0\x94\xe7\x89\xb9‘ >>> name.decode(‘utf-8‘) ‘博尔特‘ >>>
告诉Python以Utf-8的形式去解析你的代码,在*.py文件最上面一行加上 #_*_ coding:utf-8 _*_ 即可.
标签:
原文地址:http://www.cnblogs.com/yangw/p/5770953.html