标签:
装饰器(decorator)是一种高级Python语法。装饰器可以对一个函数、方法或者类进行加工。
在Python中,我们有多种方法对函数和类进行加工,比如在Python闭包中,我们见到函数对象作为某一个函数的返回结果。
相对于其它方式,装饰器语法简单,代码可读性高。因此,装饰器在Python项目中有广泛的应用。
装饰器的应用场景:饰器是一个很著名的设计模式,经常被用于有切面需求的场景,较为经典的有插入日志、性能测试、事务处理等。装
饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量函数中与函数功能本身无关的雷同代码并继续重用。
概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
装饰器的规则:
1 def derector(function): 2 def wrapper(*args,**kwargs): 3 function(*args,**kwargs) 4 return wrapper
装饰器可以用def的形式定义,如上面代码中的decorator。装饰器接收一个可调用对象作为输入参数,并返回一个新的可调用对象。
装饰器新建了一个可调用对象,也就是上面的wrapper。
1.装饰器中如何传递参数?
def outter1(Func): def wrapper(args): print("Before") Func(args) print("After") return wrapper @outter1 def Function1(agrs): print("in the Function1:%s" %agrs) Function1("nihao")
2.要修饰的函数中有返回值如何处理?
1 def outter2(Func): 2 def wrapper(): 3 res = Func() 4 return res 5 return wrapper 6 @outter2 7 def Function2(): 8 print("in the Function2") 9 return "Function2" 10 print(Function2())
3.带有参数的装饰器
1 import time 2 user,passwd = "alex","abc123" 3 def derector(auth_type): 4 print("auth_type:%s" %auth_type) 5 def outwrapper(function): 6 def wrapper(*args,**kwargs): 7 print(*args,**kwargs) 8 if auth_type =="local": 9 username = input("input your username:") 10 password = input("input the password:") 11 if username == user and password == passwd: 12 print(‘\033[32;1mUser has passed authentication!\033[0m‘) 13 res = function(*args, **kwargs) 14 print("===========After Authtication=============") 15 return res 16 else: 17 print("\033[32;1mInvalid User or Password\033[0m") 18 elif auth_type == "ldap": 19 print("gaomaoxian!") 20 return wrapper 21 return outwrapper 22 23 @derector(auth_type="ldap") 24 def bine(): 25 print("in the bin!") 26 @derector(auth_type="local") 27 def home(): 28 print("in the home!") 29 return "from home!" 30 def index(): 31 print("in the index") 32 33 bine() 34 home() 35 index()
1 #!/usr/bin/env python 2 # _*_ encoding:utf-8 _*_ 3 # author:snate 4 def Before(*agrs,**kwargs): 5 print("before") 6 def After(*args,**kwargs): 7 print("after") 8 def derector(before_Fuc,after_Fuc): 9 def out_wrapper(main_fuc): 10 def wrapper(*agrs,**kwargs): 11 before_result = before_Fuc(*agrs,*kwargs) 12 if before_result != None: 13 return before_result 14 index_result = main_fuc(*agrs, **kwargs) 15 if index_result != None: 16 return index_result 17 after_result = after_Fuc(*agrs,**kwargs) 18 if after_result != None: 19 return after_result 20 return wrapper 21 return out_wrapper 22 23 @derector(Before,After) 24 def index(*agrs,**kwagrs): 25 print("index") 26 27 index(1,2)
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。
而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
list = [x*x for x in range(10)]
print(list) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
list1 = (x*x for x in range(10))
print(list1)# <generator object <genexpr> at 0x0000000000B130F8>
只要把一个列表生成式的[]改成(),就创建了一个generator。
list = [x*x for x in range(10)] print(list) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] list1 = (x*x for x in range(10)) print(list1)# <generator object <genexpr> at 0x0000000000B130F8>
只要把一个列表生成式的[]改成(),就创建了一个generator。
print(list1.__next__()) # 0 print(list1.__next__()) # 1 print(list1.__next__()) # 4 print(list1.__next__()) # 9 print(list1.__next__()) # 16 print(list1.__next__()) # 25 print(list1.__next__()) # 36 print(list1.__next__()) # 49 print(list1.__next__()) # 64 print(list1.__next__()) # 81 print(list1.__next__()) # StopIteration,
generator保存的是算法,每次调用next(g),或者是g的__next__()私有方法,就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误
著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
1 def fib(max): 2 n,a,b = 0,0,1 3 while n<max: 4 yield b # 此处yield的作用是保存函数的执行状态,释放cpu等待状态,利用next唤醒程序。 5 a,b = b,a+b 6 n += 1 7 return "nihao" 8 9 g = fib(10) 10 # for i in g: 11 # print(i) 12 while True: 13 try: 14 x = next(g) 15 print("g:",x) 16 except StopIteration as e: 17 print("e.value:%s"%e.value) 18 break
一个函数中如果有yield关键字,那个这个函数就不在是普通的函数,而是成了生成器。
生产者消费者模型:
#!/usr/bin/env python # _*_ encoding:utf-8 _*_ # author:snate import time def consumer(name): print("%s准备吃包子了!"%name) while True: baozi = yield print("%s吃了第%s个包子" %(name ,baozi)) def producer(name): c1 = consumer("A") c2 = consumer("B") c1.__next__() c2.__next__() for i in range(10): print("%s 生产了两个包子" %name) time.sleep(1) c1.send(i) c2.send(i) producer("alex")
有yield函数式生成器,c1.__next__()是执行到yield的地方,然后跳出函数,然后执行for循环,当执行到c1.send(i),将函数从yield处唤醒,并且将i值传递给yield。
们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
isinstance({},Iterable}
isinstance((),Iterable}
isinstance([],Iterable}
列表,元组、字典、生成器都是可迭代对象
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数
你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。
可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,
只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现.

1 print(abs(-10.1)) #绝对值函数abs 2 list=[1,21,None] 3 print(all(list)) # 全为真,才为真 False 4 print(any(list)) # 只用有一个为真,就全为真 True 5 print(bool(1)) # 非零即为真 6 print(bin(5)) # 转化成二进制 ob 7 print(oct(9)) # 转化成八进制0o 8 print(hex(10)) # 转化成十六进制0x 9 bytes() # 将字符串转化成字节类型,例如: 10 print(len(bytes("李杰",encoding="utf-8"))) 11 print(len(bytes("汉字",encoding="gbk"))) 12 # 一个汉字在utf-8中占用三个字节。 13 # 一个汉字在gbk中占用两个字节。 14 print(chr(98)) # 将对应的十进制数转化转化成ascii中对应的字母 15 print(ord(‘a‘)) # 将字符转成ASCII码中对应的十进制数字。
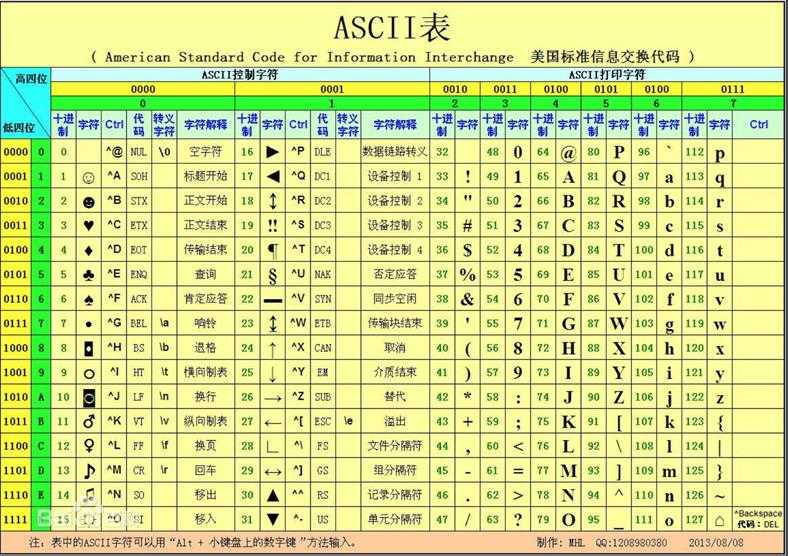
1 result = eval("8*8") # 64 eval():格式:eval( obj[, globals=globals(), locals=locals()] ), 运算符,表达式:只能执行运算符,表达式, 并且eval() 有返回值 2 result = exec("8*8") # none 格式:exec(obj),执行代码或者字符串,没有返回值,执行代码时,接收代码或者字符串 3 dir(list) # 快速查看对象有哪些功能 4 print(divmod(10,2)) #(5,0)divmod() :求商和余数,返回数据类型是元组,常用于页面分页计算 5 6 s = "alex" 7 print(isinstance(s,str)) # 判断对象是否为某一个类的实例 isinstance 8 #filter(func,obj):过滤,其中obj为可迭代的对象, 循环第二个参数,将每一个循环元素,去执行第一个参数(函数),如果函数的返回值为True,即合法 9 #filter()用来筛选,函数返回True,将元素添加到结果中。 10 li=[1,23,11,34] 11 result = filter(lambda x:x>11,li) # 数组,返回的是一个生成器。 12 #print(type(result)) 13 print(result.__next__()) 14 print(result.__next__()) 15 #print(result.__next__()) 16 #print(result) 17 #filter()是使用函数对可迭代对象进行筛选,如果函数返回为True,将对象添加到结果中 18 #map()是使用函数对可迭代对象进行处理,批量操作,将函数返回值添加到结果中 19 result = map(lambda x:x+100,li) 20 print(result) # 返回一个内存地址 21 #print(list(result)) #101 123 111 134 22 s=hash("nihao") # 生成hash值, 23 #min() 求最小 24 #max() 求最大 25 #sum() 求和 26 print(round(1.4)) #round 四舍五入 27 print(pow(10,3)) # 求幂 10*10*10 28 list1=[1,2,3,4] 29 list2=[5,6,6,8] 30 print(zip(list1,list2)) # 返回一个内存地址 31 print(list(zip(list1,list2))) # 返回一个元组(1,4),(2,6)(3,6),(4,8)
pickle和json
用于序列化的两个模块
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、loads、dump、load
pickle模块提供了四个功能:dumps、loads、dump、load
dumps和loads
1 import pickle,json 2 data = {‘k1‘:123, ‘k2‘:123} 3 #dumps可以将数据类型转换成只有python才认识的字符串 4 p_str = pickle.dumps(data) 5 print(p_str) # ‘\x80\x03}q\x00(X\x02\x00\x00\x00k2q\x01K{X\x02\x00\x00\x00k1q\x02K{u.‘ 6 # 将数据转化成python认识的字符串,并写入到文件 7 data = {‘k1‘:123, ‘k2‘:123} 8 #打开文件,然后将data写入 9 with open(‘data.pkl‘, ‘wb‘) as f: 10 pickle.dump(data, f) 11 #同样读取的时候也需要打开文件 12 with open(‘data.pkl‘, ‘rb‘) as f: 13 data_1 = pickle.load(f) 14 print(data_1,type(data_1)) 15 16 import json 17 data = {‘k1‘:123, ‘k2‘:123} 18 p_str = json.dumps(data) 19 print(p_str, type(p_str)) # {"k2": 123, "k1": 123} <class ‘str‘> 20 data = {‘k1‘:123, ‘k2‘:123} 21 22 #打开文件,然后将data写入 23 with open(‘data.pkl‘, ‘w‘) as f: 24 json.dump(data, f) 25 #同样读取的时候也需要打开文件 26 with open(‘data.pkl‘, ‘r‘) as f: 27 data_1 = json.load(f) 28 print(data_1, type(data_1))
pickle和json的区别?
在上面两段代码中,pickle写入和读取文件时,用的是 ‘b’模式,而json没有。json是可以在不同语言之间交换数据的,而pickle只在python之间使用。
json只能序列化最基本的数据类型,而pickle可以序列化所有的数据类型,包括类,函数都可以序列化。pickle转成成的字符串时字节数组,json转换的字符串是str类型。
标签:
原文地址:http://www.cnblogs.com/itlinux/p/5782543.html