标签:
package com.coca.android_unity_lab.joke;
import com.coca.unity_dev_utils.android.log.UtilsLog;
import com.coca.unity_dev_utils.android.log.UtilsLogFactory;
import com.coca.unity_dev_utils.java.UtilsCollections;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.List;
/**
* Created by Administrator on 2016/6/16.
*/
public abstract class JsoupHelper {
private static final UtilsLog lg = UtilsLogFactory.getLogger(JsoupHelper.class);
private Document document;
public JsoupHelper setDocument(Document document) {
this.document = document;
return this;
}
public void startAnaylizeByJsoup() {
Elements rootElements = getRootElements(document);
lg.e("开始使用Jsoup分析数据:analizeJsoup,共有数据量:" + rootElements.size());
for (Element rootElement : rootElements) {
anaylizeRootElement(rootElement);
}
}
/**
* 获取解析的根目录集合
*
* @param document
* @return
*/
public abstract Elements getRootElements(Document document);
/**
* 根据每个根布局生成对应的java对象
*
* @param rootElement
* @return
*/
public abstract void anaylizeRootElement(Element rootElement);
}
jsoupHelper = new JsoupHelper() {
@Override
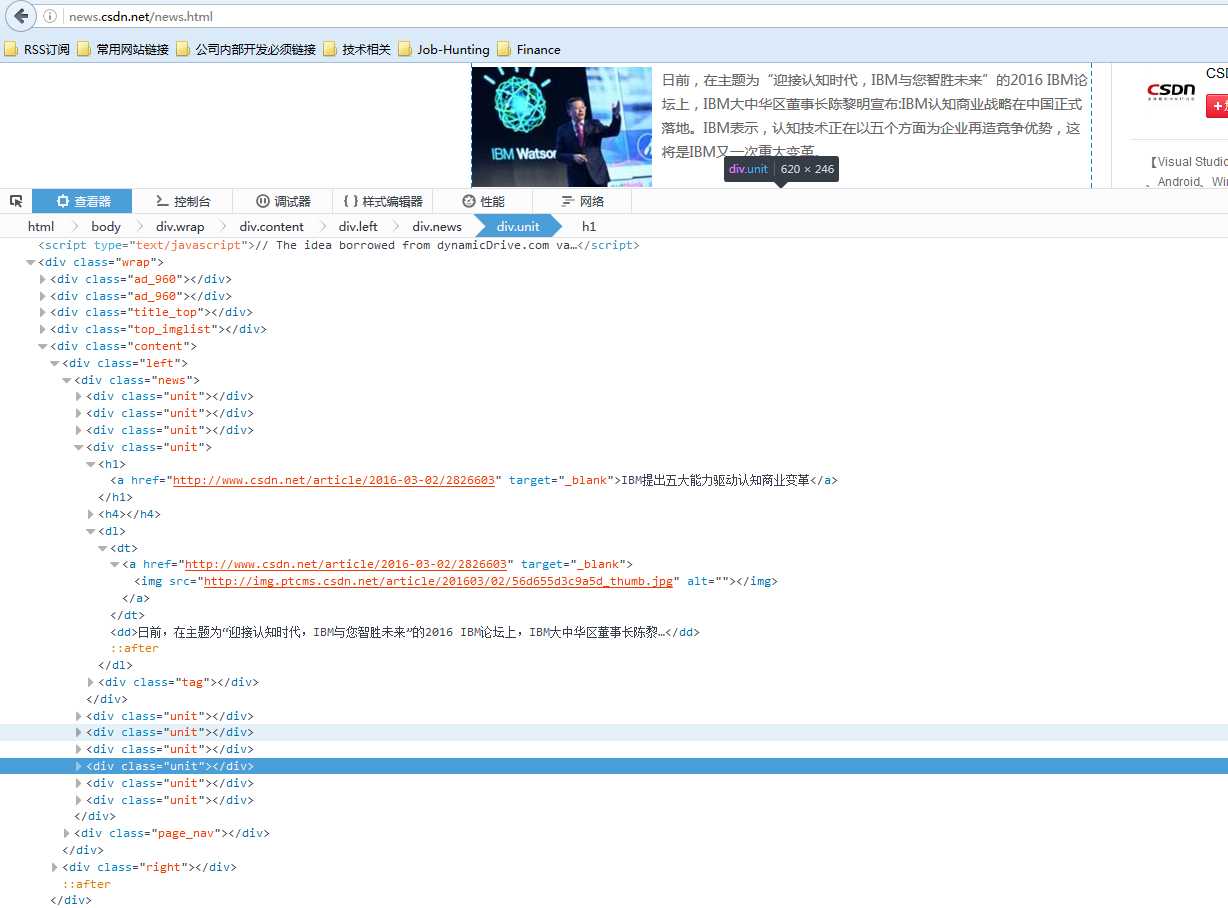
public Elements getRootElements(Document document) {
return document.getElementsByClass("unit");
}
@Override
public void anaylizeRootElement(Element rootElement) {
JokeAdapterEntity entity = new JokeAdapterEntity();
Element contentElement = JsoupHelper.paraseElement(rootElement, UtilsCollections.createListThroughMulitParamters("h1", "a"));
entity.setContent(contentElement.text());
Element imageElement = JsoupHelper.paraseElement(rootElement, UtilsCollections.createListThroughMulitParamters("dl", "dt", "a", "img"));
if (imageElement != null) {
lg.e("捕获到的数据:" + imageElement.attr("src"));
entity.setImgUrl(imageElement.attr("src"));
}
adapter.addDataResource(0, entity);
}
};
jsoupHelper.setDocument(Jsoup.parse(response)).startAnaylizeByJsoup();
/**
* 递归解析标签
* @param element
* @param tags 标签的依次搜索规则
* @return
*/
public static Element paraseElement(Element element, List<String> tags) {
if (UtilsCollections.isCollectionNotEmpty(tags)) {
String parseTag = tags.get(0);
Elements elements = element.getElementsByTag(parseTag);
boolean isElementsNotEmpty = elements != null && elements.size() > 0;
lg.e("解析标签:" + parseTag + ",Size is " + (isElementsNotEmpty ? elements.size() : 0));
if (isElementsNotEmpty) {
return paraseElement(elements.first(), tags.subList(1, tags.size()));
} else {
lg.e("该标签下的Element集合为空,return null");
return null;
}
} else {
lg.e("找到指定元素");
return element;
}
}
标签:
原文地址:http://www.cnblogs.com/linux007/p/5782720.html