标签:
实验架构图
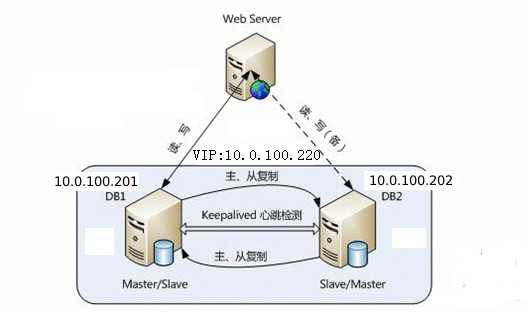
实验环境
| 主机名 | 操作系统 | Mysql版本 | keepalived版本 | 主机IP | VIP |
| lyj1(Master/Slave) | Red Hat release 6.5 | Mysql5.6.31 | keepalived-1.2.12 | 10.0.100.201 | 10.0.100.220 |
| lyj2(Slave/Master) | Red Hat release 6.5 | Mysql5.6.31 | keepalived-1.2.12 | 10.0.100.202 |
构建双主互备
1. 分别修改DB1和DB2的Mysql配置文件的一下内容,并重启Mysql服务
DB1_10.0.100.201 # vim /etc/my.cnf server_id = 705 #replicate-do-db = posp #replicate-ignore-db = mysql #log-slave-updates = 1 event_scheduler=1 # /etc/init.d/mysqld restart DB2_10.0.100.202 # vim /etc/my.cnf server_id = 706 #replicate-do-db = posp #replicate-ignore-db = mysql #log-slave-updates = 1 event_scheduler=1 # /etc/init.d/mysqld restart
2. 首先实现从DB1到DB2的Mysql主从复制(基于binlog)
DB1_Master_10.0.100.201 ->grant replication slave on *.* to ‘admin‘@‘10.0.100.202‘ identified by ‘123456‘; ->flush tables with read lock; ->show master status\G; *************************** 1. row *************************** File: mysql-bin.000001 Position: 330 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: ->unlock tables; DB2_Slave_10.0.100.202 ->stop slave; ->change master to master_host=‘10.0.100.201‘, master_user=‘admin‘, master_password=‘123456‘, master_log_file=‘mysql-bin.000001‘, master_log_pos=330; ->start slave; ->show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 10.0.100.201 Master_User: admin Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 330 Relay_Log_File: relay-bin.000002 Relay_Log_Pos: 283 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 330 Relay_Log_Space: 450 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 705 Master_UUID: c27f3c19-55ae-11e6-8194-000c290fbf4a Master_Info_File: /data/mysqldb/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 记录一个 ->start slave 时的报错 ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository 解决方法:reset slave; 再重复回以上步骤
3. 然后实现从DB2到DB1的Mysql主从复制
DB2_Master_10.0.100.202 ->grant replication slave on *.* to ‘admin‘@‘10.0.100.201‘ identified by ‘123456‘; ->flush tables with read lock; ->show master status\G; *************************** 1. row *************************** File: mysql-bin.000001 Position: 330 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: ->uplock tables; DB1_Slave_10.0.100.201 ->stop slave; ->change master to master_host=‘10.0.100.202‘, master_user=‘admin‘, master_password=‘123456‘, master_log_file=‘mysql-bin.000001‘, master_log_pos=330; ->start slave; ->show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 10.0.100.202 Master_User: admin Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 330 Relay_Log_File: relay-bin.000002 Relay_Log_Pos: 283 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 330 Relay_Log_Space: 450 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 706 Master_UUID: aba0f65c-5fff-11e6-84d9-000c293954d7 Master_Info_File: /data/mysqldb/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0
可验证,至此双主互备完成
keepalived的安装与配置
1. 在DB1和DB2上都安装keepalived
# tar zxvf keepalived-1.2.12.tar.gz
# cd keepalived-1.2.12
# ./configure --sysconf=/etc --with-kernel-dir=/usr/src/kernels/2.6.32-431.el6.i686
# make ; make install
# ln -s /usr/localsbin/keepalived /sbin
# chkconfig --add keepalived
# chkconfig --level 35 keepalived on
2. 在DB1和DB2上修改keepalived配置文件

! Configuration File for keepalived global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id LVS_DEVEL } #函数check_mysqld用于调用监控脚本 vrrp_script check_mysqld { script "/etc/keepalived/Check_Mysql.sh" #检测Mysql主从状态的脚本路径 interval 2 weight 2 } vrrp_instance VI_1 { state BACKUP #在DB1与DB2均配置为BACKUP interface eth0 #VIP配置在哪张网卡 virtual_router_id 90 #这个标识号要2个DB统一用一个 priority 100 #优先级(DB2的优先级设置得稍微小一些,本实验中设为90) advert_int 1 nopreempt #在优先级较高的DB1上要加上这条,表示不抢占模式 #在keepalived开始运行时,Master是优先级较高的DB1, #若DB1故障,则DB2成为Master #但是若DB1故障解除,是不是要重新切换使得DB1重新成为Master呢? #因为切换是很耗资源的,所以不要这样,所以设置其为不抢占模式 authentication { auth_type PASS auth_pass 1111 } track_script { check_mysqld #表示调用check_mysqld函数 } virtual_ipaddress { 10.0.100.220/32 dev eth0 } } //后面这部分可以省略 virtual_server 10.0.100.220 3306 { delay_loop 2 lb_algo wrr lb_kind DR nat_mask 255.255.255.0 persistence_timeout 60 protocol TCP real_server 10.0.100.201 3306 { weight 1 SSL_GET { connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 3306 } } }
3. 因为keepalived并没有监控Mysql的M-S是否运行正常的功能,所以监控脚本要自己写咯
#!/bin/bash #title: Check_Mysql.sh #desc: Check Mysql Slave IO running and SQL running,In keepalived #author: Jelly_lyj #date: 2016-08-17 #version: v0.01 #===================== #Set global variable #==================== #说明:每个机器改成自己的IP地址和远程授权的用户 Host_IP="10.0.100.201" User="admintest" Passw="123456" Port=3306 #============================ #Function-->Check IO and SQL #============================ Check_IO_SQL() { Check_IO=`/usr/local/mysql/bin/mysql -u $User -p$Passw -h $Host_IP -e "show slave status\G" 2>/dev/null|egrep "Slave_IO_Run"|awk ‘{print $2}‘` Check_SQL=`/usr/local/mysql/bin/mysql -u $User -p$Passw -h $Host_IP -e "show slave status\G" 2>/dev/null|egrep "Slave_SQL_Running:"|awk ‘{print $2}‘` if [ $Check_IO != ‘Yes‘ -o $Check_SQL != ‘Yes‘ ] then #只要有一个状态不是Yes,就停掉keepalived /etc/init.d/keepalived stop else #两个状态都正常,则检查keepalived状态 /etc/init.d/keepalived status if [ $? -eq 0 ] then echo "keepalived is ok" exit 0 else /etc/init.d/keepalived start if [ $? -eq 0 ] then echo "keepalived start ok" >/tmp/keepalived.log exit 0 else echo "keepalived start fail" >/tmp/keepalived.log return 1 fi fi fi } #============================ #Function-->Main #============================ Main() { Check_IO_SQL if [ $? -ne 0 ] then echo "IO or SQL error" |mail -s "Mysql Error" xxxxxxxxx@qq.com exit 1 fi } #脚本入口 Main
至此,keepalived的安装与配置完成
验证
1. 在DB1和DB2都开启keepalived,此时VIP应该在DB1上
DB1_10.0.100.201、DB2_10.0.100.202 # /etc/init.d/keepalived start 正在启动 keepalived: [确定] DB1_10.0.100.201 # ip add show 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000 link/ether 00:0c:29:0f:bf:4a brd ff:ff:ff:ff:ff:ff inet 10.0.100.201/16 brd 10.0.255.255 scope global eth0 inet 10.0.100.220/32 scope global eth0 inet6 fe80::20c:29ff:fe0f:bf4a/64 scope link valid_lft forever preferred_lft forever
2. 登陆DB1,关掉slave,模拟故障
DB1_10.0.100.201
# mysql -uroot -p ->stop slave;
3. 可以再次查看下DB1的IP和keepalived状态,看看VIP是不是如约漂移到了DB2上去了?
DB1_10.0.100.201 # ip add show 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000 link/ether 00:0c:29:0f:bf:4a brd ff:ff:ff:ff:ff:ff inet 10.0.100.201/16 brd 10.0.255.255 scope global eth0 inet6 fe80::20c:29ff:fe0f:bf4a/64 scope link valid_lft forever preferred_lft forever # /etc/init.d/keepalived status keepalived 已停 DB2_10.0.100.202 # ip add show 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000 link/ether 00:0c:29:39:54:d7 brd ff:ff:ff:ff:ff:ff inet 10.0.100.202/16 brd 10.0.255.255 scope global eth0 inet 10.0.100.220/32 scope global eth0 #VIP到DB2上了,实现了故障转移 inet6 fe80::20c:29ff:fe39:54d7/64 scope link valid_lft forever preferred_lft forever
4. 同时我们也可以验证看看当DB1故障解除,VIP会不会又漂移回来?(因为设置了不抢占模式所以当然是不会的)
5. 还有一个问题是,如果DB1的keepalived一直都关闭(即使故障已经解决),那么当DB2出了故障就没办法使得DB1起作用了(因为keepalived不开就没法通信找到DB1),所以还应该有一个监控DB1状态的脚本,当检测到其故障解除之后,开启keepalived。
标签:
原文地址:http://www.cnblogs.com/snsdzjlz320/p/5785242.html
