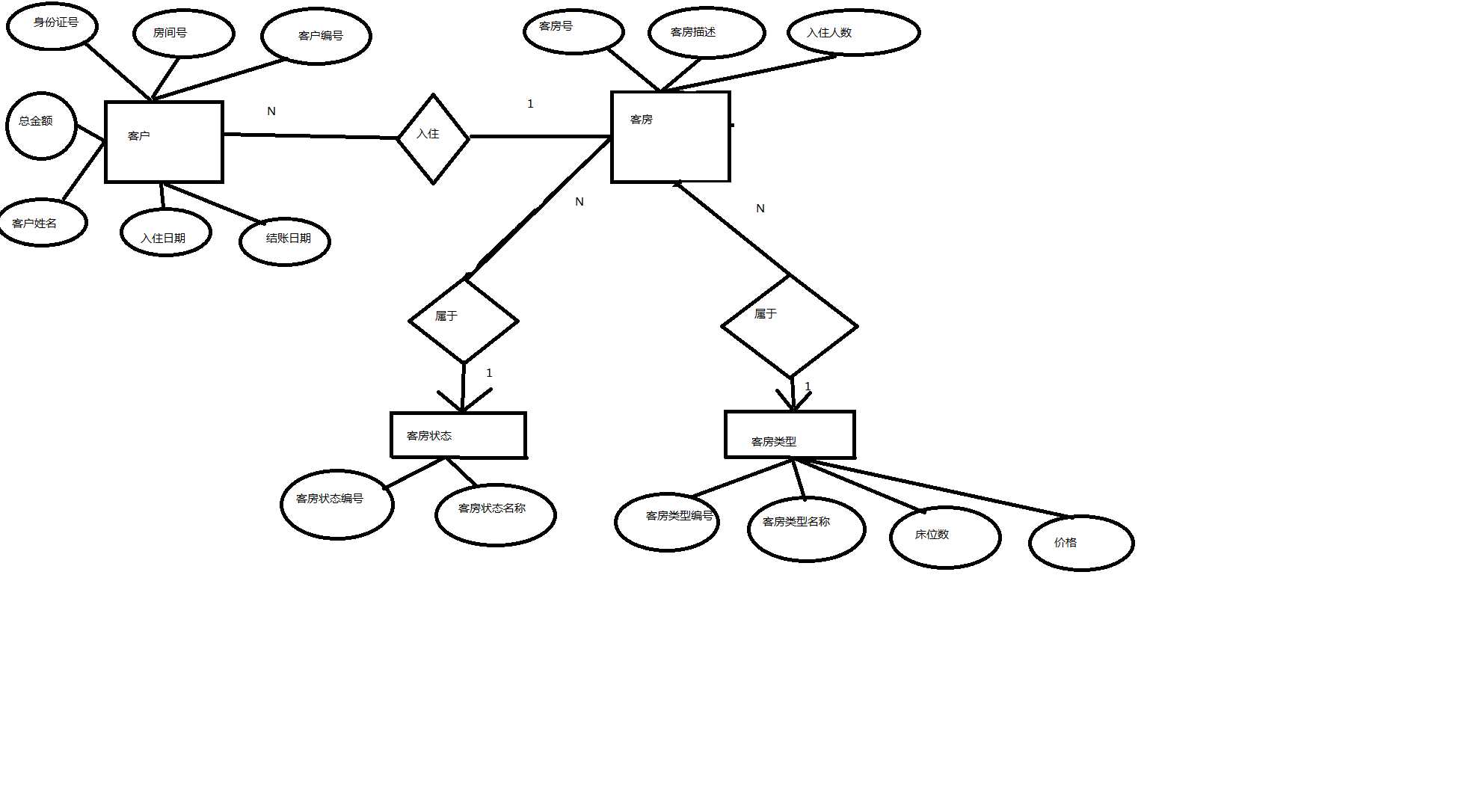
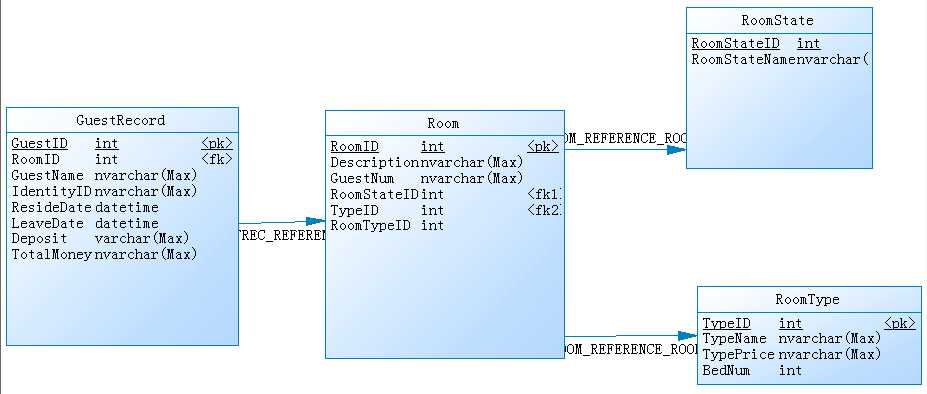
一.事务
1.什么是事务:事务是一种机制,一个操作序列,它包含一组数据库的操作命令。并把所有命令作为一个整体一起向系统提交或撤销操作请求
,要么这些数据库操作都执行,要不都不执行。同生共死同进退,事务是一个不可分割的整体。
2:事务的四种特性:原子性、一致性、隔离性、持久性
3:如何执行事务操作:1.开始事务:begin transaction
2.提交事务:commit transaction
3.回滚事务:rollback transaction
例如:转账问题假定张三的账户直接转账1000元到李四的账户上:
1 use mybank 2 create table bank 3 ( 4 cardId int primary key identity(1,1) not null, 5 cardowner nvarchar(10) not null, 6 moneyNum money 7 ) 8 go 9 alter table bank 10 add constraint CK_moneyNum check(moneyNum>=1) 11 go 12 insert into bank 13 values(‘张三‘,1000) 14 insert into bank 15 values(‘李四‘,1) 16 set nocount on 17 print ‘查看转账前的余额‘ 18 select * from bank 19 go 20 begin transaction 21 --定义变量,用于累加事务执行中出现的错误 22 declare @errorSum int 23 set @errorSum=0 24 update bank set moneyNum-=1000 where cardId=1 25 set @errorSum+=@@error 26 update bank set moneyNum+=1000 where cardId=2 27 set @errorSum+=@@ERROR 28 print ‘查看转账中的余额‘ 29 select * from bank 30 if(@errorSum<>0) 31 begin 32 print ‘交易失败,回滚事务‘ 33 rollback transaction 34 end 35 else 36 begin 37 print ‘交易成功,提交事务‘ 38 commit transaction 39 end 40 go 41 print ‘查询账户余额‘ 42 select * from bank 43 go
消息为: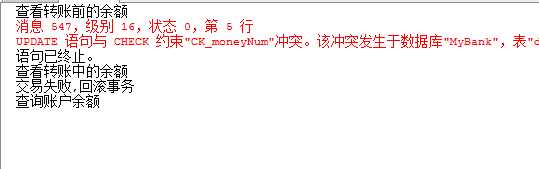 结果为:
结果为: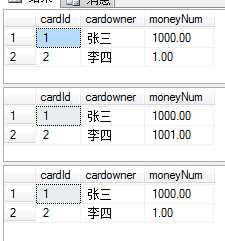
4:事物的分类:
1:显式事务:用begin transaction明确指定事物的开始(自己动手写的)
2:隐式事务:通过设置set implicit_transaction on 语句将隐式事务模式设置打开.当隐式事务操作时,SQL Server将在提交或回滚后自动启动新事务.不许描述开始,记得提交和回滚
3:自定义事务:将单独的T-SQL语句默认为一个事物.
二.视图
视图本质:视图是一张虚拟表,真正保存的是一堆SQL语句
创建视图的语法:
create view view_name
as
<SQL语句>
删除视图的语法:
drop view view_name
查看视图数据的语法:
select col_name1,col_name2,col_name3..........from view_name
例:使用T-SQL语句为教员创建查看‘oop‘课程最近一次考试成绩的视图,并通过视图查询结果
1 use MySchool 2 go 3 if exists(select * from sysobjects where name=‘vw_studentresult‘) 4 drop view vw_studentresult 5 go 6 create view vw_studentresult 7 as 8 select 姓名=Studentname,学号=student.studentNo,成绩=studentresult, 9 课程名称=subjectname,考试日期=examdate 10 from student,Result,Subject 11 where subject.SubjectId=(select SubjectId from Subject where SubjectName=‘oop‘) 12 and examdate=(select max(ExamDate) from Result where SubjectId=(select SubjectId from Subject where SubjectName=‘oop‘)) 13 go 14 select * from vw_studentresult
查询结果如图所示:
问题:能不能对视图进行增删改操作:(考试可以,面试不行)
视图可以嵌套
视图中的select后不能跟(
Order by ,除非有top关键字
不能有into
引用临时表或者是变量).
三.什么是索引:
1.索引:是SQL Server编排数据的内部方法。它为SQL Server提供一种方法来编排查询数据
2.索引分类:唯一索引、主键索引、聚集索引、非聚集索引、复合索引、全文索引
3.使用T-SQL语句创建索引:
create unique clustered|nonclustered index indexname
on table (column_name[,column_name]...)
[with fillfactor=x]
4.删除索引:drop index table_name.index_name
例:为学生姓名创建非聚集索引
--创建索引 2 if exists(select name from sysindexes where name=‘IX_studentname‘) 3 drop index.student.IX_studentname 4 create nonclustered index IX_studentname 5 on student(studentname) 6 with fillfactor=30 7 go 8 --查看数据 9 select * from Student 10 with (index=IX_studentname) 11 where StudentName like ‘张%‘
如图结果为:

查看索引:
用系统储存过程sp_helpindex查看
sp_helpindex table_name
用视图sys.indexes查看
select * from sys.indexes
一.存储过程定义:
接收在数据库服务器上存储的预先编译好的一堆SQL语句
二.存储过程的优点:
1.执行速度快(预编译:可以看成编译后的中间代码,存储过程将会在SQL SERVER服务器上进行预编译)
2.允许模式化程序设计
3.安全性更高
4.减少网络流量
三.存储过程的分类:
1.系统存储过程:一般以sp开头(stored Procedure),由sql server 创建.管理和使用,存放在resource数据库中,类似于C#中的方法.
2.扩展存储过程:一般以xp开头,使用编辑语言(如C#)创建的外部存储过程,以DELL的形式单独存在.
3.用户自定义存储过程:一般以usp开头,由用户在自己的数据库中创建的存储过程(类似于C#中自定义的方法).
四.常用的系统存储过程:
sp_databases 列出服务器上的所有数据库
exec sp_databases
sp_helpdb 报告有关指定数据库或所有数据库的信息
sp_renamedb 更改数据库的名称
sp_tables 返回当前环境下可查询的对象的列表
sp_columns 返回某个表列的信息
sp_help 查看某个表的所有信息
sp_helpconstraint 查看某个表的约束
sp_helpindex 查看某个表的索引
sp_stored_procedures 列出当前环境中的所有存储过程
sp_password 添加或修改登录帐户的密码
sp_helptext 显示默认值、未加密的存储过程、用户定义的存储过程、触发器或视图的实际文本
五.用户自定义的存储过程
语法:
Create Procedure usp_info
as
select
注意:1.参数置于as前,且不用declare关键字
2.as后的变量需要declare关键字
六.带参数的存储过程
1 alter procedure usp_GetStuResult 2 @PassScore int=90, 3 @name nvarchar(20) 4 --as之前给参数 5 as 6 if(@PassScore>=0 and @PassScore<=100) 7 begin 8 select studentname,studentresult 9 from student,result 10 where student.studentno=result.studentno 11 and 12 studentresult>@PassScore 13 end 14 else 15 begin 16 raiserror(‘及格线输入有误‘,16,1) 17 end 18 19 --开始测试存储过程书写是否存在问题 20 exec usp_GetStuResult @name=‘张三‘
raiserror用法:
raiserror返回用户定义的错误信息时,可指定严重级别.设置系统变量记录所发生的错误
七.带output参数的存储过程:
1 alter proc usp_getpaglist 2 @pageindex, int--当前是第几页 3 @pagesize,--每页的记录数 4 @totalpages int output--总页数 5 as 6 select * from 7 ( 8 select * ,row_number()over(order by studentno)as myid 9 from student 10 )as tmp 11 where myid between(@pageindex-1)*@pagesize+1 and@ pageindex * @pagesize 12 --总记录数=总记录数/@pagesize 13 declare @totalrecord int 14 select @totalrecord =count(1) from student 15 set @totalpages =ceiling( @totalrecord *1.0/@pagesize) 16 --调用 17 declare @pages int 18 set @pages=0 19 exec usp_getpagelist 1,3@pages output 20 print @pages