标签:
Memcache是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它基于一个存储key/value对的hashmap,通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。
它的工作机制是在内存中开辟一块空间,然后建立一个HashTable并自己管理,使用非阻塞的网络IO。
更多详细的信息参阅Memcache官方网站:http://www.danga.com/memcached
MemCache的数据存放在内存中,这就意味着需要考虑以下问题:
对于缓存数据库来说,最重要的莫过于内存分配了,MemCache采用的内存分配方式是固定空间分配。
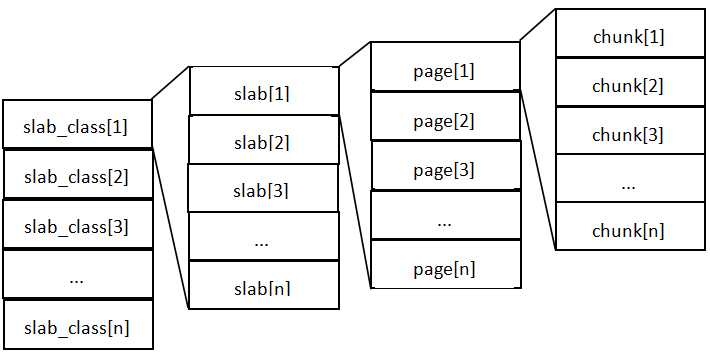
这张图片里面涉及了slab_class、slab、page、chunk四个概念,它们之间的关系是:
MemCache内存分配的方式称为allocator,slab的数量是有限的,几个、十几个或者几十个,这个和启动参数的配置相关。
MemCache中的value存放的地方是由value的大小决定的,value总是会被存放到与chunk大小最接近的一个slab中。比如slab[1]的chunk大小为80字节、slab[2]的chunk大小为100字节、slab[3]的chunk大小为128字节(相邻slab内的chunk基本以1.25为比例进行增长,MemCache启动时可以用-f指定这个比例),那么过来一个88字节的value,这个value将被放到2号slab中。
放入slab时,首先为slab申请内存,申请内存是以page为单位的,所以在放入第一个数据的时候,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk数组,最后从这个chunk数组中选择一个用于存储数据。
如果这个slab中没有chunk可以分配了怎么办,如果MemCache启动没有追加-M(禁止LRU,这种情况下内存不够会报Out Of Memory错误),那么MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据。针对MemCache的内存分配及回收算法,总结三点:
上文已经提到了一些,此处再做总结:
Memcached相互不通信的分布式: Memcached 服务器之间不会进行通信,数据都是通过客户端的分布式算法存储到各个服务器。
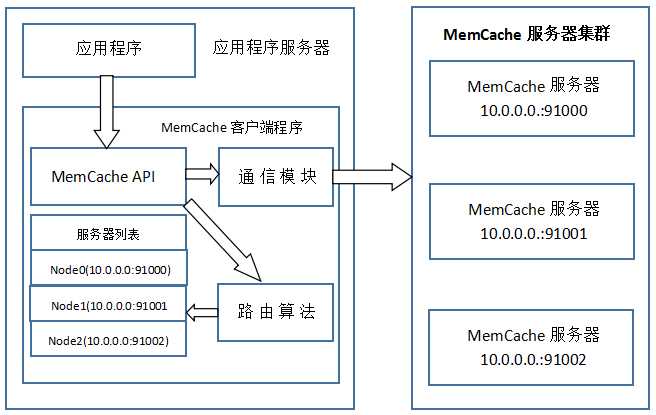
MemCache虽然被称为"分布式缓存",但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信(与之形成对比的,比如JBoss Cache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据),所谓的"分布式",完全依赖于客户端程序的实现,就像上面这张图的流程一样。
MemCache一次写缓存的流程:
读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,且应用程序查询的是相同的Key,MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中。
这种MemCache集群的方式也是从分区容错性的方面考虑的,假如Node2宕机了,那么Node2上面存储的数据都不可用了,此时由于集群中Node0和Node1还存在,下一次请求Node2中存储的Key值的时候,肯定是没有命中的,这时先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值在Node0和Node1中选取一个节点,把对应的数据放进去,这样下一次就又可以走缓存了,这种集群的做法很好,但是缺点是成本比较大。
还需要注意的是,Memcache设置添加某个key值的时候,指定expiry为0表示这个key/value永久有效,但这个key/value也会在30天后失效,见memcache.c源代码:

#define REALTIME_MAXDELTA 60*60*24*30 static rel_time_t realtime(const time_t exptime) { if (exptime == 0) return 0; if (exptime > REALTIME_MAXDELTA) { if (exptime <= process_started) return (rel_time_t)1; return (rel_time_t)(exptime - process_started); } else { return (rel_time_t)(exptime + current_time); } }
这个失效的时间是memcache源码里面写死的,开发者没有办法改变。
标签:
原文地址:http://www.cnblogs.com/crazyacking/p/5788834.html
