标签:
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言。
编译型:在程序执行之前,有一个单独的编译过程,将程序翻译成机器语言,以后执行这个程序的时候,就不用再进行翻译了。简单来说就是先翻译,在执行,比如C/C++这类型语言
两种类型都有翻译的意思,只是翻译的顺序不一样,这就导致了不同类型语言的执行速度不同,适应环境也不一样。编译型语言执行速度快于解释型语言,但是不能跨平台执行。
强类型语言:一旦变量的类型被确定,就不能转化的语言。实际上所谓的貌似转化,都是通过中间变量来达到,原本的变量的类型肯定是没有变化的。
弱类型语言:一个变量的类型是由其应用上下文确定的。比如语言直接支持字符串和整数可以直接用 + 号搞定。当然,在支持运算符重载的强类型语言中也能通过外部实现的方式在形式上做到这一点,不过这个是完全不一样的内涵 。
通常来说python属于强类型语言
在python的交互模式下编译执行
>>> print(‘hello world‘) hello world >>>
python解释器在加载.py的文件中的代码时,会对文件中的内容进行编码。在python3中默认是支持中文,而在python2中使用中文前若不进行字符转换,就会报错。
最早出现的ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。其最多只能表示255个符号,所以并适用于中文。
附ASCII表:
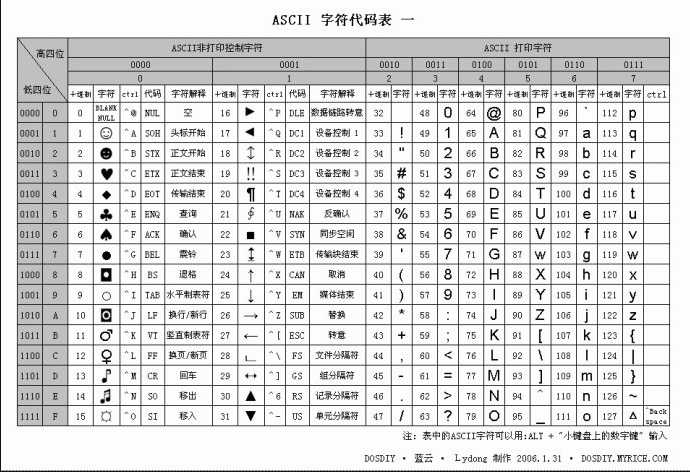
为了解决中文编码问题,1980年,设计了第一张中文字符编码GB2312,共收录了7445个字符,包括6763个汉字和682个其它符号。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在PC机都必须支持GB18030。
由1990年开始研发,1994年正式公布的Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨平台、跨语言进行文本转换、处理的要求。
1992年发布的UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。现在已经标准化为RFC 3629。UTF-8用1到4个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
标签:
原文地址:http://www.cnblogs.com/flash55/p/5790459.html