标签:
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
1991年 发布Python第一个版本。 最新的TIOBE排行榜,Python赶超PHP占据第五, Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。 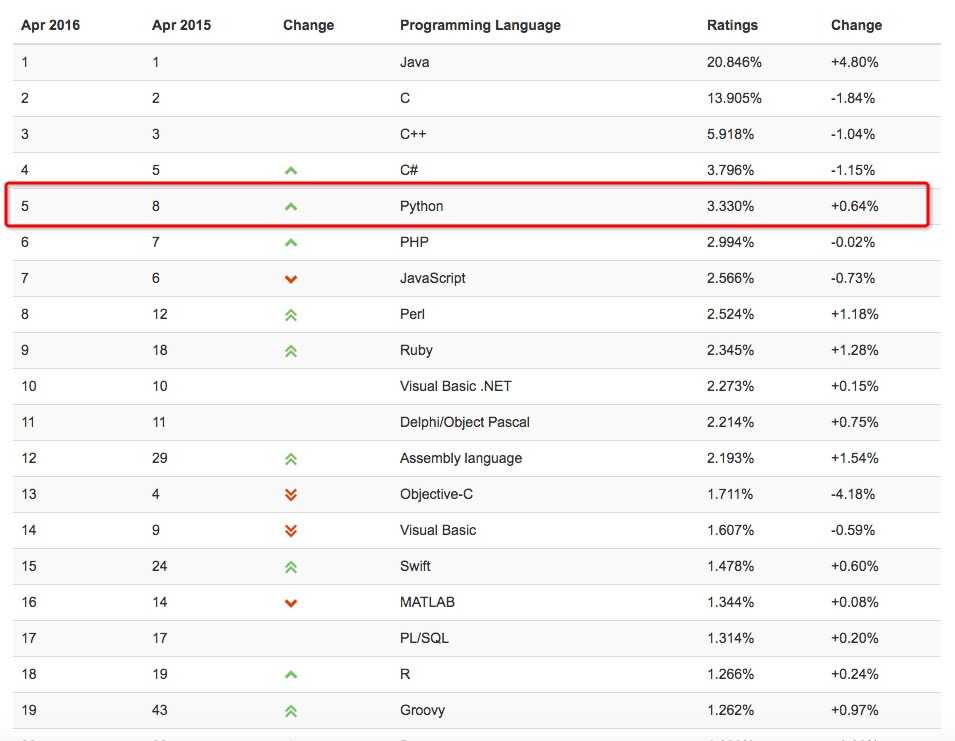 由上图可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到业内的认可!!!
由上图可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到业内的认可!!!
Python被应用在众多领域:
使用Python的企业
除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务。 更多案例:https://www.python.org/about/success/
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言,每个分类代表什么意思呢,我们一起来看一下。
我们先看看编译型,其实它和汇编语言是一样的:也是有一个负责翻译的程序来对我们的源代码进行转换,生成相对应的可执行代码。这个过程说得专业一点,就称为编译(Compile),而负责编译的程序自然就称为编译器(Compiler)。如果我们写的程序代码都包含在一个源文件中,那么通常编译之后就会直接生成一个可执行文件,我们就可以直接运行了。但对于一个比较复杂的项目,为了方便管理,我们通常把代码分散在各个源文件中,作为不同的模块来组织。这时编译各个文件时就会生成目标文件(Object file)而不是前面说的可执行文件。一般一个源文件的编译都会对应一个目标文件。这些目标文件里的内容基本上已经是可执行代码了,但由于只是整个项目的一部分,所以我们还不能直接运行。待所有的源文件的编译都大功告成,我们就可以最后把这些半成品的目标文件“打包”成一个可执行文件了,这个工作由另一个程序负责完成,由于此过程好像是把包含可执行代码的目标文件连接装配起来,所以又称为链接(Link),而负责链接的程序就叫……就叫链接程序(Linker)。链接程序除了链接目标文件外,可能还有各种资源,像图标文件啊、声音文件啊什么的,还要负责去除目标文件之间的冗余重复代码,等等,所以……也是挺累的。链接完成之后,一般就可以得到我们想要的可执行文件了。
上面我们大概地介绍了编译型语言的特点,现在再看看解释型。噢,从字面上看,“编译”和“解释”的确都有“翻译”的意思,它们的区别则在于翻译的时机安排不大一样。打个比方:假如你打算阅读一本外文书,而你不知道这门外语,那么你可以找一名翻译,给他足够的时间让他从头到尾把整本书翻译好,然后把书的母语版交给你阅读;或者,你也立刻让这名翻译辅助你阅读,让他一句一句给你翻译,如果你想往回看某个章节,他也得重新给你翻译。
两种方式,前者就相当于我们刚才所说的编译型:一次把所有的代码转换成机器语言,然后写成可执行文件;而后者就相当于我们要说的解释型:在程序运行的前一刻,还只有源程序而没有可执行程序;而程序每执行到源程序的某一条指令,则会有一个称之为解释程序的外壳程序将源代码转换成二进制代码以供执行,总言之,就是不断地解释、执行、解释、执行……所以,解释型程序是离不开解释程序的。像早期的BASIC就是一门经典的解释型语言,要执行BASIC程序,就得进入BASIC环境,然后才能加载程序源文件、运行。解释型程序中,由于程序总是以源代码的形式出现,因此只要有相应的解释器,移植几乎不成问题。编译型程序虽然源代码也可以移植,但前提是必须针对不同的系统分别进行编译,对于复杂的工程来说,的确是一件不小的时间消耗,况且很可能一些细节的地方还是要修改源代码。而且,解释型程序省却了编译的步骤,修改调试也非常方便,编辑完毕之后即可立即运行,不必像编译型程序一样每次进行小小改动都要耐心等待漫长的Compiling…Linking…这样的编译链接过程。不过凡事有利有弊,由于解释型程序是将编译的过程放到执行过程中,这就决定了解释型程序注定要比编译型慢上一大截,像几百倍的速度差距也是不足为奇的。
编译型与解释型,两者各有利弊。前者由于程序执行速度快,同等条件下对系统要求较低,因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++、Pascal/Object Pascal(Delphi)、VB等基本都可视为编译语言,而一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如Java、JavaScript、VBScript、Perl、Python等等。
但既然编译型与解释型各有优缺点又相互对立,所以一批新兴的语言都有把两者折衷起来的趋势,例如Java语言虽然比较接近解释型语言的特征,但在执行之前已经预先进行一次预编译,生成的代码是介于机器码和Java源代码之间的中介代码,运行的时候则由JVM(Java的虚拟机平台,可视为解释器)解释执行。它既保留了源代码的高抽象、可移植的特点,又已经完成了对源代码的大部分预编译工作,所以执行起来比“纯解释型”程序要快许多。而像VB6(或者以前版本)、C#这样的语言,虽然表面上看生成的是.exe可执行程序文件,但VB6编译之后实际生成的也是一种中介码,只不过编译器在前面安插了一段自动调用某个外部解释器的代码(该解释程序独立于用户编写的程序,存放于系统的某个DLL文件中,所有以VB6编译生成的可执行程序都要用到它),以解释执行实际的程序体。C#(以及其它.net的语言编译器)则是生成.net目标代码,实际执行时则由.net解释系统(就像JVM一样,也是一个虚拟机平台)进行执行。当然.net目标代码已经相当“低级”,比较接近机器语言了,所以仍将其视为编译语言,而且其可移植程度也没有Java号称的这么强大,Java号称是“一次编译,到处执行”,而.net则是“一次编码,到处编译”。呵呵,当然这些都是题外话了。总之,随着设计技术与硬件的不断发展,编译型与解释型两种方式的界限正在不断变得模糊。
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。
(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的! 例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言。那这些基因使成就了Python的哪些优缺点呢?我们继续往下看。
先看优点
再看缺点:
线程不能利用多CPU问题,这是Python被人诟病最多的一个缺点,GIL即全局解释器锁(Global Interpreter Lock),是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻仅有一个线程在执行,Python的线程是操作系统的原生线程。在Linux上为pthread,在Windows上为Win thread,完全由操作系统调度线程的执行。一个python解释器进程内有一条主线程,以及多条用户程序的执行线程。即使在多核CPU平台上,由于GIL的存在,所以禁止多线程的并行执行。关于这个问题的折衷解决方法,我们在以后线程和进程章节里再进行详细探讨。
当然,Python还有一些其它的小缺点,在这就不一一列举了,我想说的是,任何一门语言都不是完美的,都有擅长和不擅长做的事情,建议各位不要拿一个语言的劣势去跟另一个语言的优势来去比较,语言只是一个工具,是实现程序设计师思想的工具,就像我们之前中学学几何时,有的时候需要要圆规,有的时候需要用三角尺一样,拿相应的工具去做它最擅长的事才是正确的选择。之前很多人问我Shell和Python到底哪个好?我回答说Shell是个脚本语言,但Python不只是个脚本语言,能做的事情更多,然后又有钻牛角尖的人说完全没必要学Python, Python能做的事情Shell都可以做,只要你足够牛B,然后又举了用Shell可以写俄罗斯方块这样的游戏,对此我能说表达只能是,不要跟SB理论,SB会把你拉到跟他一样的高度,然后用充分的经验把你打倒。
1989年,为了打发圣诞节假期,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python’s Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。 1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
Python 1.0 - January 1994 增加了 lambda, map, filter and reduce. 1999年 Python的web框架之祖——Zope 1发布 Python 2.0 - 2000/10/16,加入了内存回收机制,构成了现在Python语言框架的基础 Python 2.4 – 2004/11/30, 同年目前最流行的WEB框架Django 诞生 Python 2.5 - 2006/09/19 Python 2.6 - 2008/10/1 Python 2.7 - 2010/07/03
Python 3.0 - 2008/12/03 Python 3.1 - 2009/06/27 Python 3.2 - 2011/02/20 Python 3.3 - 2012/09/29 Python 3.4 - 2014/03/16 Python 3.5 - 2015/09/13
2014年11月,Python2.7将在2020年停止支持的消息被发布,并且不会在发布2.8版本,建议用户尽可能的迁移到3.4+
Python最初发布时,在设计上有一些缺陷,比如Unicode标准晚于Python出现,所以一直以来对Unicode的支持并不完全,而ASCII编码支持的字符有限。例: 对中文支持不好 Python3相对Python早期的版本是一个较大的升级,Py3在设计的时候没有考虑向下兼容,所以很多早期版本的Python的程序无法再Py3上运行。 为了照顾早期的版本,推出过渡版本2.6——基本使用了Python 2.x的语法和库,同时考虑了向Python 3.0的迁移,允许使用部分Python 3.0的语法与函数。 2010年继续推出了兼容版本2.7,大量Python3的特性被反向迁移到了Python2.7 2.7比2.6进步非常多,同时拥有大量3中的特性和库,并且照顾了原有的Python开发人群
所以我们还是推荐大家使用Python3.x。 python2.x和3.x的详细区别如下图: 
当然,每学习一种语言,首先要学习的当然是仪式感超强的hello world了,下面就来看看python3中的hello world该怎么写吧
1 >>> print("hello world!") 2 hello world!
上面就是python中的hello world了,在python2中的写法是print "hello world!"但是在3中print后面必须要跟上()要输出的内容写在()中。
变量: 变量就是用来存储一些信息,供程序以后调用或者操作修改。变量为标记数据提供了一种描述性的名字,以便我们的程序可以被程序的阅读者很清晰的理解。把变量作为一个存储信息的容器会更容易理解变量。它的主要是目的是笔记和存储在内存中的数据,这个数据就可以在你的整个程序中使用。 变量的作用:变量可以用来指定内存中的某一个区域,通过使用该变量,可以在之后访问到之前存贮的内容,也可对该内容进行修改。
常量的作用:python中不像其他语言一样。有常量的概念,但是python中约定俗成的把变量名全部大写的变量看做常量,该常量不能被修改。
变量的命名规则:
表达式和运算符
什么是表达式?
1+23 就是一个表达式,这里的加号和乘号叫做运算符,1、2、3叫做操作数。1+23 经过计算后得到的结果是7,就1+23 = 7。我们可以将计算结果保存在一个变量里,ret = 1-23 。 所以表达式就是由操作数和运算符组成的一句代码或语句,表达式可以求值,可以放在“=”的右边,用来给变量赋值。
算术运算符 : + - * / //(取整除) %(取余) **
1 >>> 2+3 2 5 3 >>> 3-2 4 1 5 >>> 2*3 6 6 7 >>> 5/2 8 2.5 9 >>> 5//2 10 2 11 >>> 5%2 12 1 13 >>> 2**3 14 8
赋值运算符: = 、+= -= *= /= %= //= **=
1 >>> num = 2 2 >>> num += 1 # 等价于 num = num + 1 3 >>> num -= 1 # 等价于 num = num - 1 4 >>> num *= 1 # 等价于 num = num * 1 5 >>> num /= 1 # 等价于 num = num / 1 6 >>> num //= 1 # 等价于 num = num // 1 7 >>> num %= 1 # 等价于 num = num % 1 8 >>> num **= 2 # 等价于 num = num ** 2
比较运算符:>、 <、 >=、 <=、 ==、!= True False简单讲一下
顾名思义,比较运算符是用来做比较的,比较的结果会有两种,分别是成立和不成立,成立的时候,结果是 True,不成立的时候结果是False。 True和False 用来表示比较后的结果。
1 >>> a = 5 2 >>> b = 3 3 >>> a > b # 检查左操作数的值是否大于右操作数的值,如果是,则条件成立。 4 True 5 >>> a < b # 检查左操作数的值是否小于右操作数的值,如果是,则条件成立。 6 False 7 >>> a <= b # 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立。 8 False 9 >>> a >= b # 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立。 10 True 11 >>> a == b # 检查,两个操作数的值是否相等,如果是则条件变为真。 12 False 13 >>> a != b # 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 14 True
逻辑运算符: not 、and、 or
逻辑运算符是用来做逻辑计算的。像我们上面用到的比较运算符,每一次比较其实就是一次条件判断,都会相应的得到一个为True或False的值。而逻辑运算符的的操作数就是一个用来做条件判断的表达式或者变量。
1 >>> a > b and a < b # 如果两个操作数都是True,那么结果为True,否则结果为False。 2 False 3 >>> a > b or a < b # 如果有两个操作数至少有一个为True, 那么条件变为True,否则为False。 4 True 5 >>> not a > b # 反转操作的状态,操作数为True,则结果为False,反之则为True 6 False
成员运算符: not in 、in (判断某个单词里是不是有某个字母)
成员运算符用来判断一个元素是否是另一个元素的成员。 比如说我们可以判断 “hello” 中是否有 “h”, 得到的结果也是True 或者 False。
1 >>> "h" in "hello" # 这里的意思是 “h” 在“Hello” 中,判断后结果为True 2 True 3 >>> "h" not in "hello" # 这里的意思是 “h” 不在“Hello” 中,判断后结果为False 4 False
身份运算符: is、is not(讲数据类型时讲解,一般用来判断变量的数据类型)
用来判断身份。
1 >>> a = 123456 2 >>> b = a 3 >>> b is a #判断 a 和 b 是不是同一个 123456 4 True 5 >>> c = 123456 6 >>> c is a #判断 c 和 a 是不是同一个 123456 7 False 8 >>> c is not a #判断 c 和 a 是不是不是同一个 123456 9 True
这里我们首先将123456赋值给a,后有将a赋值给b, 这样其实是 a和b 的值都是123456, 但是后面c的值也是123456,为什么 第一次a is b 的结果为True ,c和 a 的结果为False 呢?
原因是这样的: 我们知道程序是运行在内存里的,第一次 我们将123456赋值给a的时候,其实是在内存里开辟了一块空间,将123456放在这块空间里,为了找到这里的123456, 会有一个指向这块空间的地址,这个地址叫做内存地址,是123456存储在内存中的地址。a其实指向的就是存储123456的内存空间的地址。执行了b=a,就是让b指向的地址和a一样。之后我们执行了 c = 123456 ,这里就会再开辟一块内存空间,并将指向该空间的内存地址赋值给c ,这样的话 ,a和b 指向的是同一个123456, c 指向的是另外一个123456 。
在python2中获取用户输入数据使用raw_input("xxx:"),而在python3中只能使用input("xxx:")来获取用户输入。 有了获取用户输入之后就可以实现程序和用户的交互运行了。
python和其他语言一样,也是用if else来实现判断逻辑的。语法如下所示:
if 条件: 判断体内语句 elif 条件: 判断体内语句 else: 判断体内语句
缩进——推荐四个空格 (使用2个、3个空格或者tab都是可以得)
不要tab与空格混用 不同软件对空格的显示逻辑总是一样的,但是对于tab却五花八门。 有的软件把Tab展开成空格,有的不会展开。有的Tab宽度是4,有的宽度是8, 这些不一致会使得代码混乱,尤其是靠缩进表示块结构的Python。
下面是一个使用判断语句实现的猜年龄游戏: ageofprincal=56 guessage=int(input(">>:")) if ageofprincal==guessage: print("yes,you got it!") else: print("no,you are wrong!")
下面是一段使用判断实现获取三个值的最大值和最小值的小代码:
1 num1=int(input("num1:")) 2 num2=int(input("num2:")) 3 num3=int(input("num3:")) 4 if num1<num2: 5 num1,num2=num2,num1 6 if num1<num3: 7 num1,num3=num3,num1 8 if num2<num3: 9 num2,num3=num3,num2 10 print("max:",num1) 11 print("min:",num3)
python中循环控制主要有如下两种:
for循环语句,结构如下所示:
for 变量 in 可遍历对象: 循环体内语句 else: 循环体后语句
其中需要注意的是for循环后面还跟了else语句,这个方式我只在python中见到过,目前我知道的一种用法就是当for循环正常执行结束后就会执行else中的语句,但是,当在循环体中使用break或者循环体异常结束时,else中的语句将不会被执行。
while循环语句,结构如下所示:
while 条件表达式: 循环体内语句 else: 循环体后语句
while循环中也存在else语句,和for循环中的else语句作用一样,当while之后的条件表达式为真时,才会进入循环体内部执行,注意while循环语句可以一次都不被执行。
break和continue语句都可以用于循环体内部,break的作用是跳出当前循环,而continue的作用是从当前位置结束当前循环,进入下次循环。 这个没什么解释的。。。试试就能理解了。。。
对上面的猜年龄游戏的改进,这个更具有可玩性,ps,开发者也不知道答案是多少,哈哈哈:
1 import random 2 age=random.randint(0,100) 3 flag=True 4 while flag: 5 user_input_age=int(input("age is: ")) 6 if user_input_age > age: 7 print("bigger!") 8 elif user_input_age < age: 9 print("small!") 10 else: 11 print("good!") 12 flag=False 13 print("THE END!")
下面是两种利用循环嵌套实现9*9口诀表的代码块:
1 for i in range(1,10): 2 for j in range(1,i+1): 3 print("%s*%s=%s\t"%(j,i,i*j),end="") 4 print() 5 6 i=1 7 while i<=9: 8 j=1 9 while j<=i: 10 print("%s*%s=%s\t"%(j,i,i*j),end="") 11 j+=1 12 i+=1 13 print()
利用循环嵌套实现等腰三角形的输出:
1 row=int(input("pls input rows:")) 2 star=row 3 for i in range(row,0,-1): 4 for j in range(i-1,0,-1): 5 print(" ",end="") 6 print("*"*((star-i)*2+1))
标签:
原文地址:http://www.cnblogs.com/huxianglin/p/python_basic.html