标签:
问题:
最近在做一个应用的时候碰到了一个问题。客户端需要调用服务器端传回的脚本信息,然后执行。其中脚本类型包括ruby。而java中调用ruby的代码大致如下:

1 String jrubyCode="puts ‘hello world‘"; 2 ScriptEngineManager manager = new ScriptEngineManager(); 3 ScriptEngine engine = manager.getEngineByName("jruby"); 4 engine.eval(jrubyCode);
却发现最后getEngineByName("jruby")老是返回null。网上搜了很多解决办法都没有解决。
原因:
目前jdk里面内嵌的好像只有支持最基本的js调用的引擎,对于其他的脚本语言调用,需要用到对应的脚本引擎jar包。
解决办法:
百度了很多都无果,最终google出了解决办法。
1. 去jruby官网下载最新的jruby工具包:http://jruby.org/download。(Linux直接下载最新的tar.gz包,windows根据系统分别下载64位或者32位包)
2. 安装或者解压对应的jruby到特定的目录,并且模仿java_home设置jruby_home和path。
3. 引入解压或者安装之后程序lib目录下的jruby,jar包到工程中。
知其然还要知其所以然,接下来我们来解析为什么需要上面三个步骤。
其实可以发现此jruby.jar包中有一个org.jruby.embed.jsr223目录,该目录结构大致如下图所示:
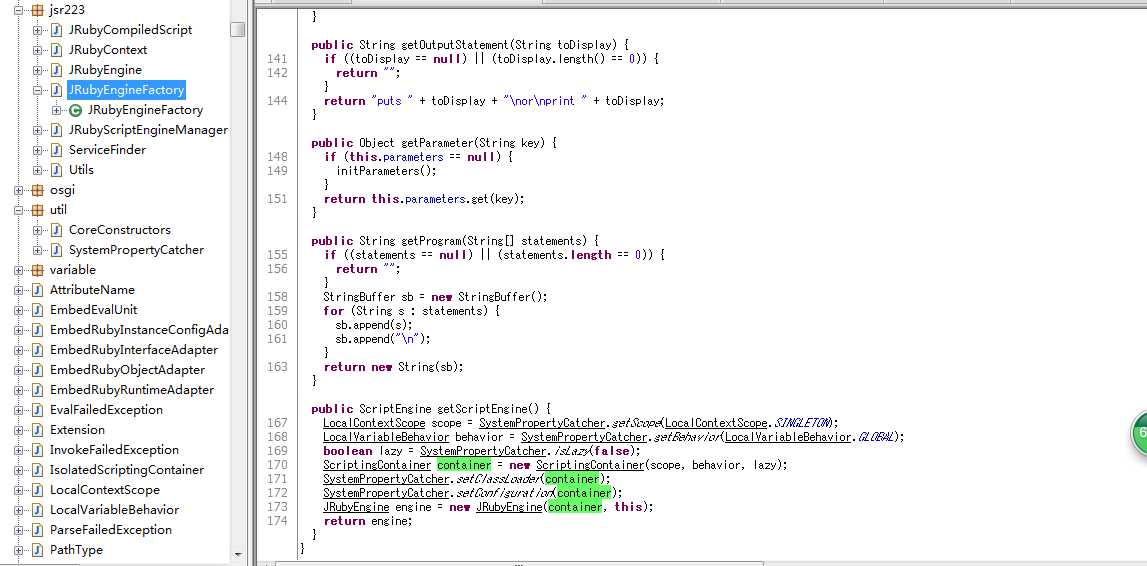
我们可以看到JRubyEngineFactory的实现,注意其getScriptEngine方法,里面有用到ScriptContainer,这表示一个脚本容器。查看该类对应的构造方法:
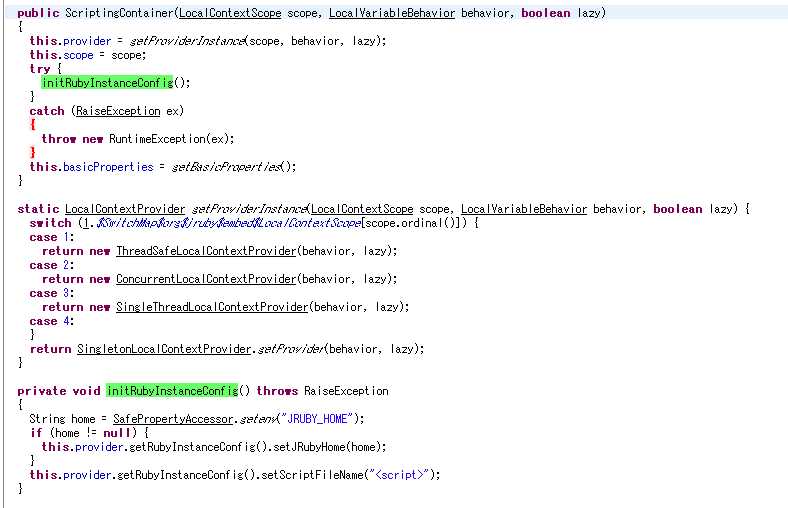
可以看到其构造方法调用了initRubyInstanceConfig方法,该方法根据JRUBY_HOME对应的路径去找对应的jruby实例。这就完美的说明了前面三个步骤的原因。
标签:
原文地址:http://www.cnblogs.com/Kidezyq/p/5794993.html
