标签:
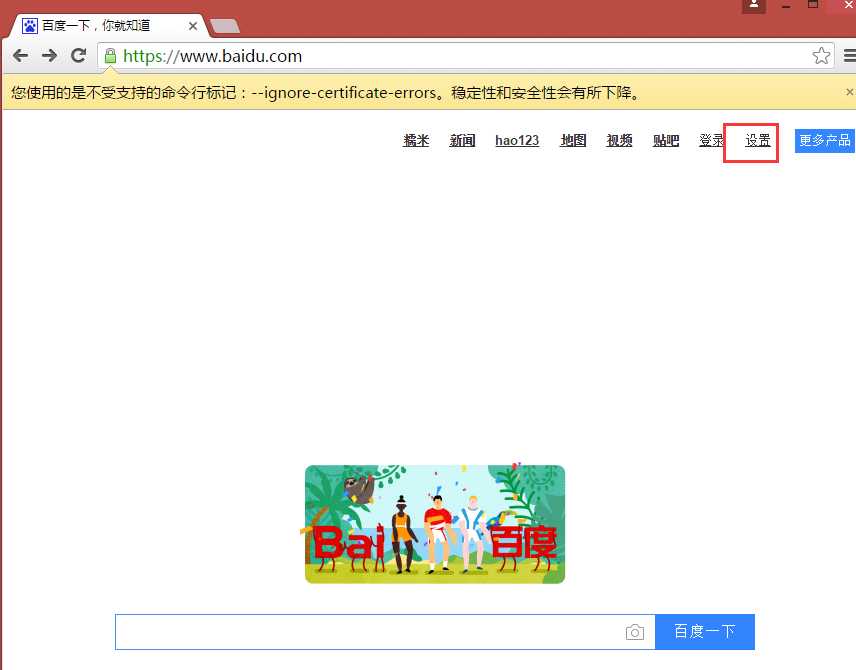
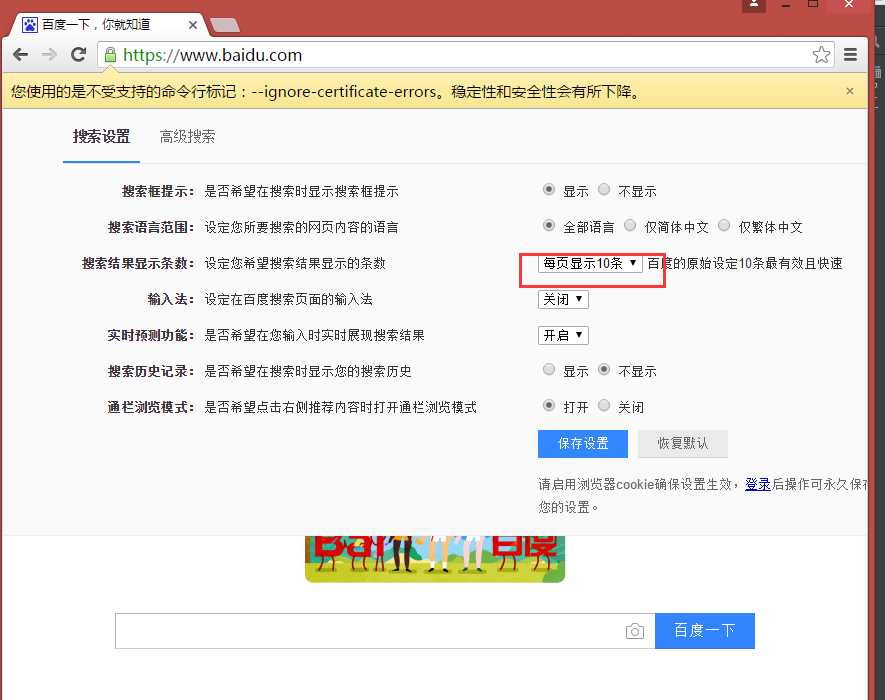
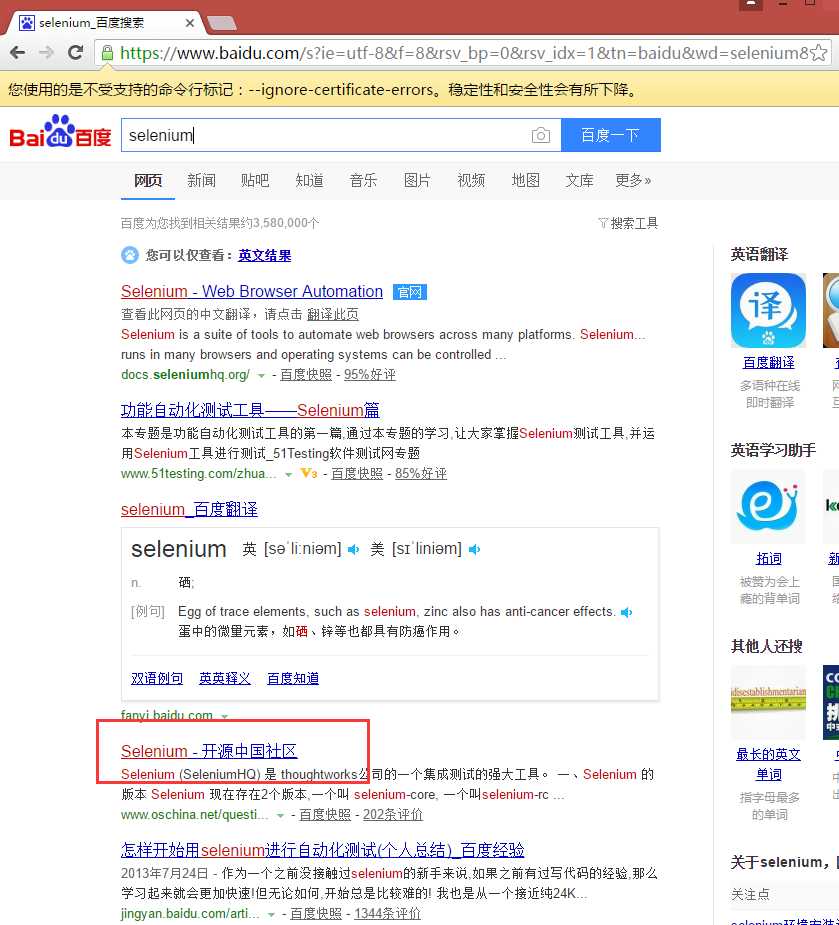
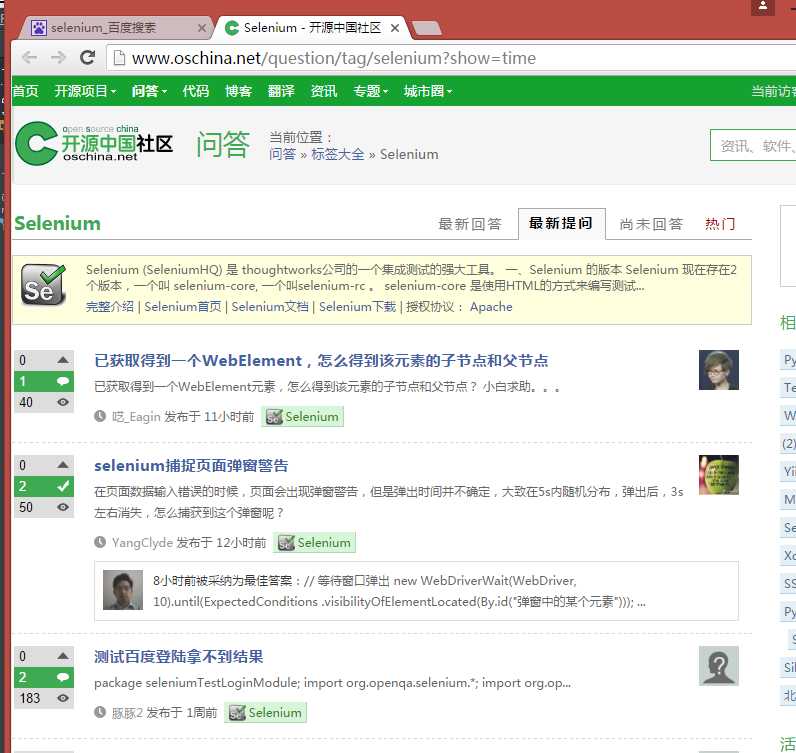
from selenium import webdriver from time import sleep # 后面是你的浏览器驱动位置,记得前面加r‘‘,‘r‘是防止字符转义的 driver = webdriver.Chrome(r‘C:\Python34\chromedriver_x64.exe‘) # 用get打开百度页面 driver.get("http://www.baidu.com") # 查找页面的“设置”选项,并进行点击 driver.find_elements_by_link_text(‘设置‘)[0].click() # 打开设置后找到“搜索设置”选项,设置为每页显示50条 driver.find_elements_by_link_text(‘搜索设置‘)[0].click() sleep(2) m = driver.find_element_by_id(‘nr‘) sleep(2) m.find_element_by_xpath(‘//*[@id="nr"]/option[3]‘).click() sleep(2) # 处理弹出的警告页面 driver.find_element_by_class_name("prefpanelgo").click() sleep(2) driver.switch_to_alert().accept() sleep(2) # 找到百度的输入框,并输入“selenium” driver.find_element_by_id(‘kw‘).send_keys(‘selenium‘) sleep(2) # 点击搜索按钮 driver.find_element_by_id(‘su‘).click() sleep(2) # 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面 driver.find_elements_by_link_text(‘Selenium - 开源中国社区‘)[0].click()
4.以下页面操作都是自动完成
【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览
标签:
原文地址:http://www.cnblogs.com/liangxuehui/p/5797185.html