标签:
简单理解就是:
正则表达式就是一套处理字符串的规则和方法,以行为单位对字符串进行处理,通过特殊的符号的辅助,我们可以快速的过滤,替换某些特定字符。
例如:grep(egrep),sed,awk命令都需要正则表达式的配合。提高效率。
运维工作中,会有大量访问日志,错误日志,大数据。都需要正则表达式。(快速过滤需要的内容)
正则表达式一些字符,赋予了它特定的含义:
基础正则表达式:BRE
1)^can 表示该行以can开头。
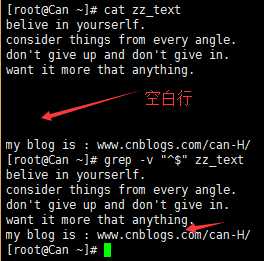
2)can$ 表示该行以can结尾。 “^$”表示空行,例如:grep -v “^$”去除空行。
3)。 表示任意一个字符(仅一个)。

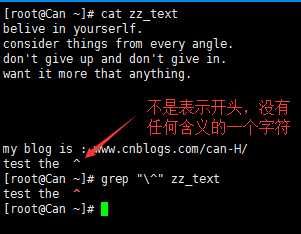
4)\ 转义符号,让有特殊身份的字符,无效。例如
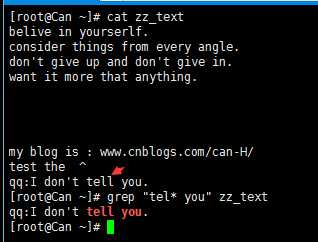
5)* 重复0个或多个前面的一个字符
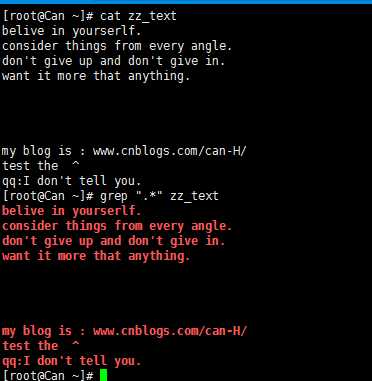
".*"匹配所有字符
6)[] 表示字符集合的重复特殊字符的符号
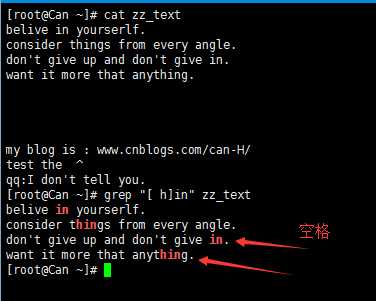
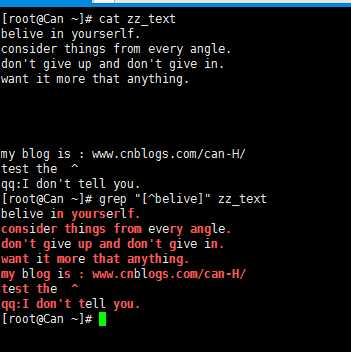
7) [^] 表示非 [^can] 表示非c或a或n的内容 [^0-9]匹配非数字
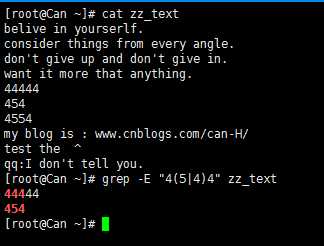
9){n,m} 重复n到m次前一个重复的字符 a{n,m} 一般大括号需要转义 a\{n,m\} 用egrep可以去掉斜线
{n,} 重复最少n次前一个重复的字符
{n} 重复n次 前一个重复的字符
扩展的正则表达式:ERE
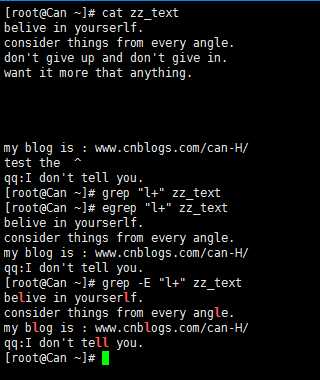
1) + 表示重复一个或一个以上前面的字符
2) ? 零个或一个字符(待检测)
3) | 用或的方式查找多个符合的字符串 chkconfig --list | grep -E "network|sshd"
4) () 找出“用户组”字符串
以上是以grep来举例。大部分可用 awk,sed,grep,egrep
在linux查找正则表达式 man grep 搜索REGULAR
标签:
原文地址:http://www.cnblogs.com/can-H/p/5801092.html