标签:
在讲述文件操作之前,我们首先要知道什么是文件。看到这个问题你可能会感觉到可笑,因为对于用过计算机的人来说,文件是最简单不过的概念了,例如一个文本是一个文件,一个work文档是一个文件等。但是在Linux中,文件的概念还远不止于这些,在Linux中,一切(或几乎一切)都是文件。文件包括很多的内容,例如:大家知道的普通文件是文件,目录也是一个文件,设备也是一个文件,管道也是一个文件等等。对于目录、设备这些的操作也可以完全等同于对纯文本文件的操作,这也是Linux非常成功的特性之一吧。
1、文件描述符
文件描述符是一些小数值,你可以通过它们访问的打开的文件设备,而有多少文件描述符可用取决于系统的配置情况。但是当一个程序开始运行时,它一般会有3个已经打开的文件描述符,就是
0:标准输入
1:标准输出
2:标准错误
那些数学(即0、1、2)就是文件描述符,因为在Linux上一切都是文件,所以标准输入(stdin),标准输出(stdout)和标准错误(stderr)也可看作文件来对待。
2、系统调用常用函数
A、open系统调用
open函数的原型为:
int open(const char *path, int oflags);
int open(const char *path, int oflags, mode_t mode);
path,是包括路径的完整文件名,oflags是文件访问模式(即是什么方式打开文件,只读、只写还是可读并可写等),mode用于设定文件的访问权限。具体的可选参数,可以自己查看手册页,这里不一一详述。
open建立了一条到文件或设备的访问路径,如果调用成功,返回一个可以被read、write等其他系统调用的函数使用的文件描述符,而且这个文件描述是唯一的,不与任何其他运行中的进程共享,在失败时返回-1,并设置全局变量errno来指明失明的原因。
B、write系统调用
write函数的原型为:
size_t write(int fildes, const void *buf, size_t nbytes);
write的作用是把缓冲区buf的前nbytes个字节写入到文件描述符fildes关联的文件中,返回实际写入的字节数。返回0表示没有写入任何数据,返回-1表示调用中出现了错误,错误代码保存在errno中。
注:fildes一定要是在open调用中返回的创建的文件描述符,或者是0、1、2等标准输入、输出或标准错误。
C、read系统调用
read函数的原型为:
size_t read(int fildes, void *buf, size_t nbytes);
read系统调用的作用是从与文件描述符相关的文件里读入nbytes个字节的数据,并把它们放到数据区buf中,返回读入的字节数,失败时返回-1。
D、close系统调用
close调用的函数原型为:
int close(int fildes);
close函数的作用是终于文件描述符fildes一其对应的文件之间的关联。
E、例子
说了这么多,我就给出一个完整的例子吧,就是从一个数据文件(里面有1M个‘0’字符)逐个复制到别一个文件。文件名为copy_system.c,代码如下:
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
char c = ‘\0‘;
int in = -1, out = -1;
// 以只读方式打开数据文件
in = open("Data.txt", O_RDONLY);
// 以只写方式创建文件,如果文件不存在就创建一个新的文件
// 文件属主具有读和写的权限
out = open("copy_system.out.txt", O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR);
// 读一个字节的数据
while (read(in, &c, 1) == 1)
{
// 写一个字节的数据
write(out, &c, 1);
}
// 关闭文件描述符
close(in);
close(out);
return 0;
}
三、标准I/O库
有过C编程经历的人都会知道stdio头文件,它就是C语言的标准IO库,在标准IO库中,与底层文件描述符相对应的是流,它被实现为指向结构FILE的指针。IO库的函数有很多,为了与前面的内容对应,这里还是只讲与前面四个函数相对应的函数,其他的函数,你可以查一查手册页。
A、fopen库函数
fopen库函数的原型为:
FILE* fopen(const char *filename, const char *mode);
它与底层系统调用open类似,成功时返回一个非空指针。失败时返回NULL。
B、fread库函数
fread库函数的原型为:
size_t fread(void *ptr, size_t size, size_t nitems, FILE *stream);
它与底层调用read相似,其作用是从stream读取nitems个长度为size的数据到ptr所指向的缓冲区中。返回值是成功读到缓冲区中的记录个数。
注:stream为用fopen函数返回的文件结构指针。
C、fwrite库函数
fwrite库函数的原型:
size_t fwrite(const void *ptr, size_t size, size_t nitems, FILE *stream);
它与底层调用write相似,其作用是从ptr指向的缓冲区中读取nitems个长度为size到数据,并把它们写到stream所对应的文件中。
D、fclose库函数
fclose库函数的原型为:
int fclose(FILE *stream);
它与系统调用close相似,其作用是关闭指定的文件流stream。
例子
同样地,下面是前一个例子的另一个实现版本,它实现的功能与先前的例子一样,不过使用的是标准I/O库,而不是系统调用,文件名为copy_stdio.c代码如下:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int c = 0;
FILE *pfin = NULL;
FILE *pfout = NULL;
// 以只读方式打开数据文件
pfin = fopen("Data.txt", "r");
// 以只写方式打开复制的新文件
pfout = fopen("copy_stdio.out.txt", "w");
// 读数据
while (fread(&c, sizeof(char), 1, pfin))
{
//写数据
fwrite(&c, sizeof(char), 1, pfout);
}
// 关闭文件流
fclose(pfin);
fclose(pfout);
return 0;
}
当然这里你也可以用其他的库函数来完成工作,如:用fgetc代替fread,用fputc代替fwrite等。
每个文件流都对应一个底层文件描述符,你可以把底层输入输出操作与高层文件流操作混合使用,但是一般不要这样做,因为数据缓冲的后果难以预料。我们可以通过调用fileno函数(原型为:int fileno(FILE *stream))来确定文件流使用的底层文件描述符,它返回指向文件流的文件描述符。相反地,你可以通过调用函数fdopen(原型为FILE* fdopen(int fildes, const char* mode))来在一个已经打开的文件描述符上创建一个新的文件流,mode参数与fopen函数的完全一样,同时它必须符合该文件在最初打开时所设定的访问模式。
但是在Linux下的编程,系统调用用得比较多一些,因为很多时候系统调用能提供更多的灵活性和更加强大的功能,有些操作是一定要使用系统调用,例如,创建文件读写锁时就一定要使用系统调用。
就拿本例子中的代码来比较,两个例子编译后生成的可执行文件的文件名分别为:copy_system.exe和copy_stdio.exe,在Linux下用time命令来测试其运行时间如下:
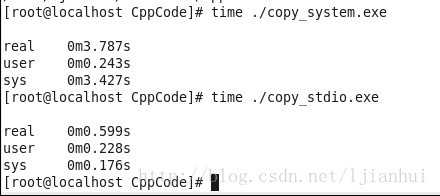
 从测试结果可以看出,系统调用的效率比库函数要低很多。为什么呢?
从测试结果可以看出,系统调用的效率比库函数要低很多。为什么呢?
因为使用系统调用会影响系统的性能。与函数调用相比,系统调用时,Linux必须从运行用户代码切换到执行内核代码,然后再返回用户代码,所以系统调用的开销要比普通函数调用大一些。然而也是有办法减少这种开销的,就是在程序中尽量减少系统调用的的次数,并且让每次系统调用完成尽量多的工作。
而库函数为什么做同样的事情效率却会高这么多呢?这是因为库函数在数据满足数据块长度(或buffer长度)要求时才安排执行底层系统调用,从而减少了系统调用的次数,也让每次的系统调用做了尽量多的事情,所以效率就比较高。
用回每一个例子(coy_system.c)的代码,略加修改就能提高我们的效率,例如一次读1024个字节,修改后保存文件名为copy_system2.c,代码如下:
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
char buff[1024];
int in = -1, out = -1;
int nread = 0;
in = open("Data.txt", O_RDONLY);
out = open("copy_system2.out.txt", O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR);
// 一次读写1024个字节
while ((nread = read(in, buff, sizeof(buff))) > 0)
{
write(out, buff, nread);
}
close(in);
close(out);
return 0;
}
生成的可执行文件为copy_system2.exe,使用time命令查看其执行时间,如下:
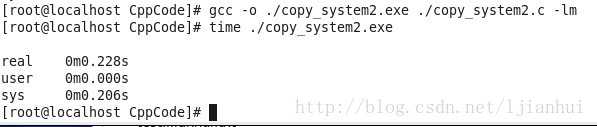
比较下可以看出,其性能改善了一个数量级,其效率甚至比用库函数一个一个字符复制来来得高效,至少在我的机子上是这样。
参考:
http://blog.csdn.net/ljianhui/article/details/10055665
Linux C 文件操作 -- 系统调用(open(),read()...) 和 标准I/O库(fopen(),fread()...)
标签:
原文地址:http://www.cnblogs.com/52php/p/5801275.html