标签:
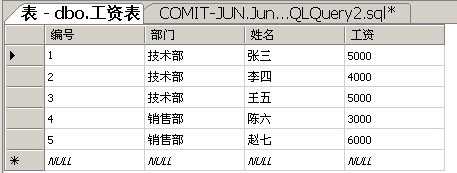
规则1:单值规则,跟在SELECT后面的列表,对于每个分组来说,必须返回且仅仅返回一个值。
在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
因此,我们希望查询出每个部门,最高工资的那个人的姓名,部门,工资。我们要另寻解决方案。
解决方案1:关联子查询
SELECT 姓名,部门,工资 FROM 工资表 AS T1 WHERE NOT EXISTS (SELECT NULL FROM 工资表 AS T2 WHERE T1.部门 = T2.部门 AND T2.工资 > T1.工资)
输出如下:
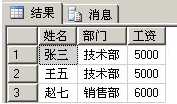
完全符合要求。对于上面的关联子查询,可以理解为:
遍历工资表的所有记录,查找不存在比当前记录部门相同且工资还大的记录。
虽然,关联子查询的语法非常简单,但是性能并不好。因为对于每一条记录,都要执行一次子查询。
解决方案2:衍生表
使用衍生表的思路是,先执行一个子查询,得到一个临时结果集,然后用临时结果集和原表进行INNER JOIN操作。就能得到最高工资的人的信息。
SELECT 姓名,T1.部门,工资 FROM 工资表 AS T1 INNER JOIN
(
SELECT 部门,MAX(工资) AS 最高 FROM 工资表 --执行查询,先记录两个字段 部门-最高工资
GROUP BY 部门
) AS T2 --衍生表T2
ON T1.部门 = T2.部门 AND 工资 = 最高
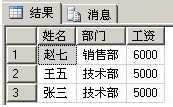
衍生表的方式性能优于关联子查询,因为衍生表的方式只执行了一次子查询。但是它需要一张临时表来存储临时记录。因此,这个方案也并不是最佳的解决方案。
解决方案3:使用JOIN + IS NULL
这是一个更妙的解决方案,当我们用一个外联结去匹配记录时,当匹配的记录不存在,就会用NULL来代替相应的列。
我们先来看一条非常简答的SQL语句:
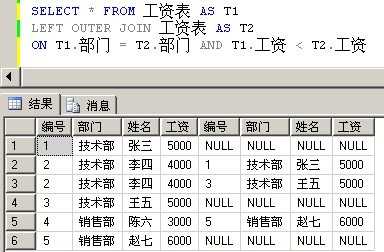
从中你看到了什么?当T2表中,不存在比T1表中工资高的记录时就返回NULL。
那么,那么,那么一个IS NULL是不是就解决问题了呢?
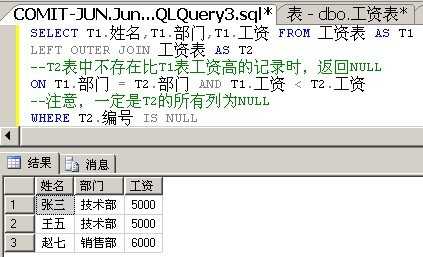
好妙,好妙的方法,让人拍案叫绝的使用了OUTER JOIN。
JOIN解决方案适用于针对大量数据查询并且可伸缩比较时。它总是能比基于子查询的解决方案更好地适应数据量的变量。
解决方案4:对额外的列使用聚合函数
我们知道,GROUP BY时,SELECT列表必须返回的是单值,那么我们可不可以通过使用聚合函数,让这个列返回单值呢?答案是可以的。
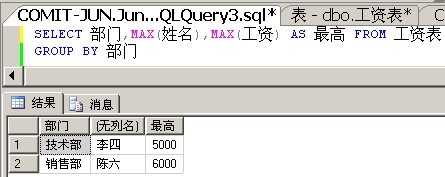
其实,返回的数据是有问题的,当工资相同时,它就返回按姓名从大到小排列的第一个姓名。也就是说,当工资相同时,它只能够返回一条记录。
我们将聚合函数换成MIN看看。
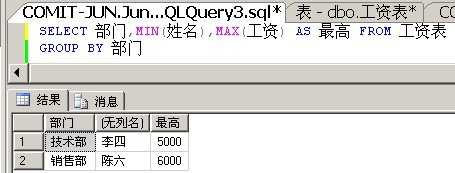
解决方案5:Row_Number() + OVER
WITH B AS
(
SELECT row_number() OVER(PARTITION BY Name ORDER BY CreateTime) AS part ,Score, Name, CreateTime
FROM xxx
)
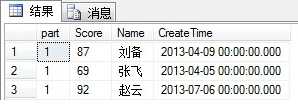
SELECT * FROM B WHERE Part = 1
输出如下:
GROUP BY子句有个缺点,就是返回的结果集中只有合计数据,而没有原始的详细记录。如果想在SQL SERVER中完成这项工作,可以使用COMPUTE BY子句。COMPTE生成合计作为附加的汇总列出现在结果集的最后。当与BY一起使用时,COMPUTE 子句在结果集内生成控制中断和分类汇总。
下列 SELECT 语句使用简单 COMPUTE 子句生成 titles 表中 price 及 advance 的求和总计:
下列查询在 COMPUTE 子句中加入可选的 BY 关键字,以生成每个组的小计:
USE pubs
此 SELECT 语句的结果用12 个结果集返回,六个组中的每个组都有两个结果集。每个组的第一个结果集是一个行集,其中包含选择列表中所请求的信息。每个组的第二个结果集包含 COMPUTE 子句中两个 SUM 函数的小计。
compute by 子句的规则:
(1)不能将distinct与行统计函数一起使用
(2)compute ??? by 子句中 ???出的列必须出现在选择列表中
(3)不能在含有compute by 子句的语句中使用select into 子句,因为包括compute 子句的语句会产生不规则的行。
(4)如果使用了compute by子句,则必须使用order by 子句, 而且compute by子句中的列必须包含在order by 子句中,并且对列的前后顺序和起始项都要一致(说白了compute by子句中的列必须是order by子句中列表的全部,或者前边的连续几个)。
(5)如果compute 省略了 by ,则order by 也可以省略
(6)如果compute by 子句包含多列时,会将一个组(第一个列分的组)分成若干个子组(利用后面的列),并对每层子组进行统计。
(7)使用多个compute by子句时,会分别按不同的组统计出结果。详细信息还是按照正常的第一个分组方式显示。
(8)compute by 子句中可以使用多个统计函数,他们互不影响
(9)compute by 子句中可以不包含by ,而只用compute 此时不对前面信息分组,而只对全部信息进行统计。
比较 COMPUTE 和 GROUP BY
COMPUTE 和 GROUP BY 之间的区别汇总如下:
GROUP BY 生成单个结果集。每个组都有一个只包含分组依据列和显示该组子聚合的聚合函数的行。选择列表只能包含分组依据列和聚合函数。
COMPUTE 生成多个结果集。一类结果集包含每个组的明细行,其中包含选择列表中的表达式。另一类结果集包含组的子聚合,或 SELECT 语句
的总聚合。选择列表可包含除分组依据列或聚合函数之外的其它表达式。聚合函数在 COMPUTE 子句中指定,而不是在选择列表中。
下列查询使用 GROUP BY 和聚合函数;该查询将返回一个结果集,其中每个组有一行,该行中包含该组的聚合小计:
USE pubs
SELECT type, SUM(price), SUM(advance)
FROM titles
GROUP BY type
说明 在 COMPUTE 或 COMPUTE BY 子句中,不能包含 ntext、text 或 image 数据类型。
select * from A where 数量 > 8
执行结果:
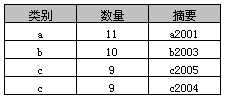
select * from A where 数量>8 compute max(数量),min(数量),avg(数量)
执行结果如下:
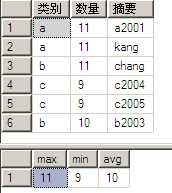
compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
select * from A where 数量>8 order by 类别 compute max(数量),min(数量),avg(数量) by 类别
执行结果如下:
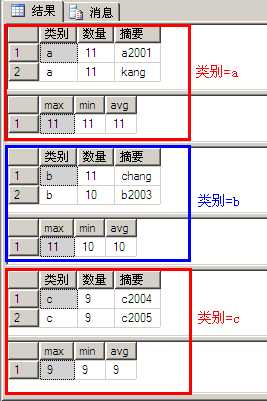
示例11与示例10相比多了“order by 类别”和“... by 类别”,示例10的执行结果实际是按照分组(a、b、c)进行了显示,每组都是由改组数据列表和改组数统计结果组成,另外:
在实际开发中compute与compute by的作用并不是很大,SQL Server支持compute和compute by,而Access并不支持
SQLServer 之 Group By 和 Compute By
标签:
原文地址:http://www.cnblogs.com/xinaixia/p/5803682.html