标签:
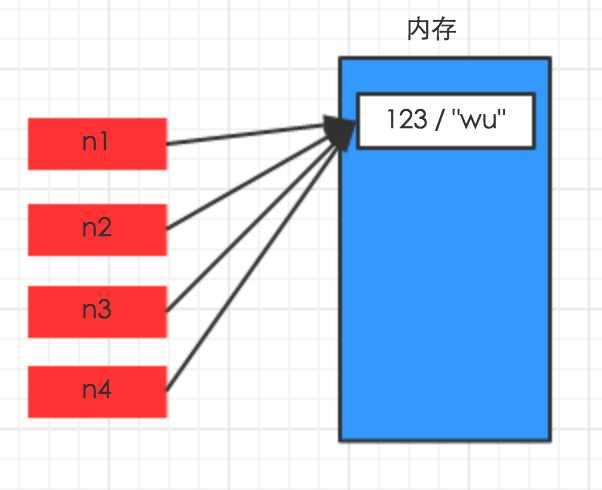
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import copy# ######### 数字、字符串 #########n1 = 123# n1 = "i am alex age 10"print(id(n1))# ## 赋值 ##n2 = n1print(id(n2))# ## 浅拷贝 ##n2 = copy.copy(n1)print(id(n2))# ## 深拷贝 ##n3 = copy.deepcopy(n1)print(id(n3)) |
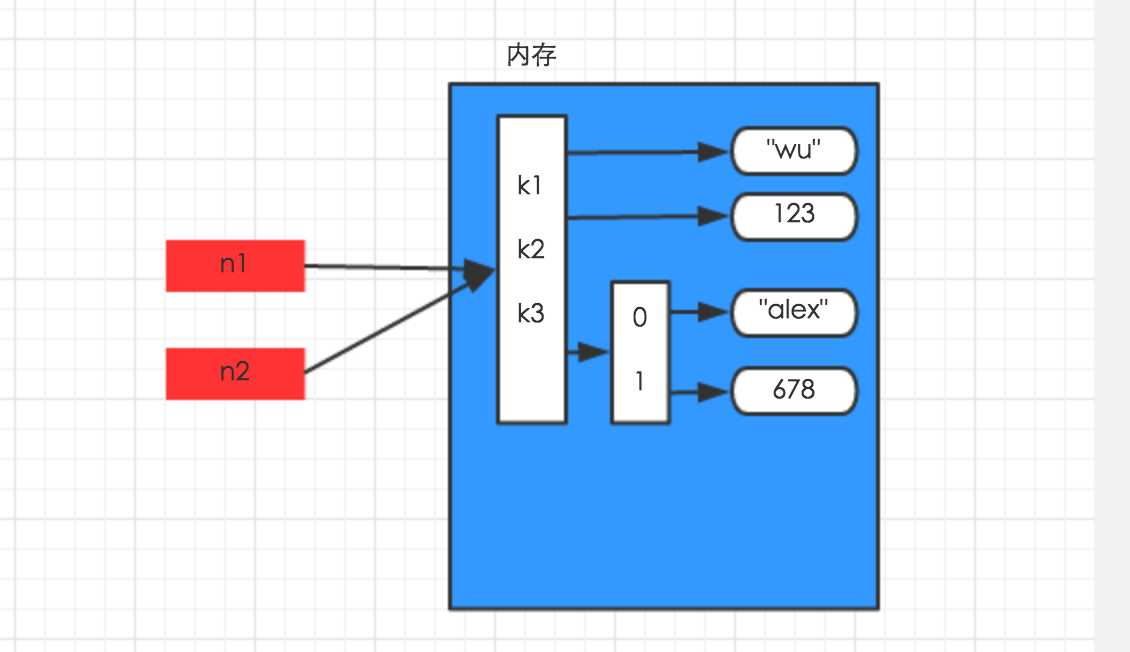
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
赋值,只是创建一个变量,该变量指向原来内存地址,如:
|
1
2
3
|
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}n2 = n1 |
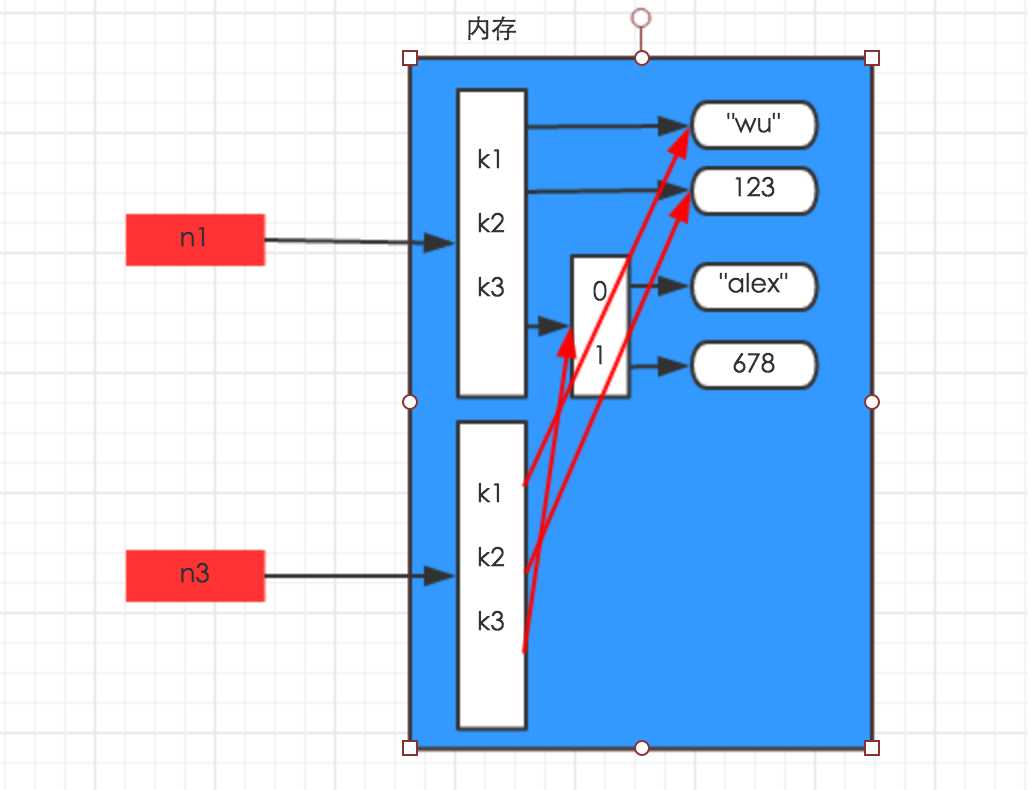
浅拷贝,在内存中只额外创建第一层数据
|
1
2
3
4
5
|
import copyn1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}n3 = copy.copy(n1) |
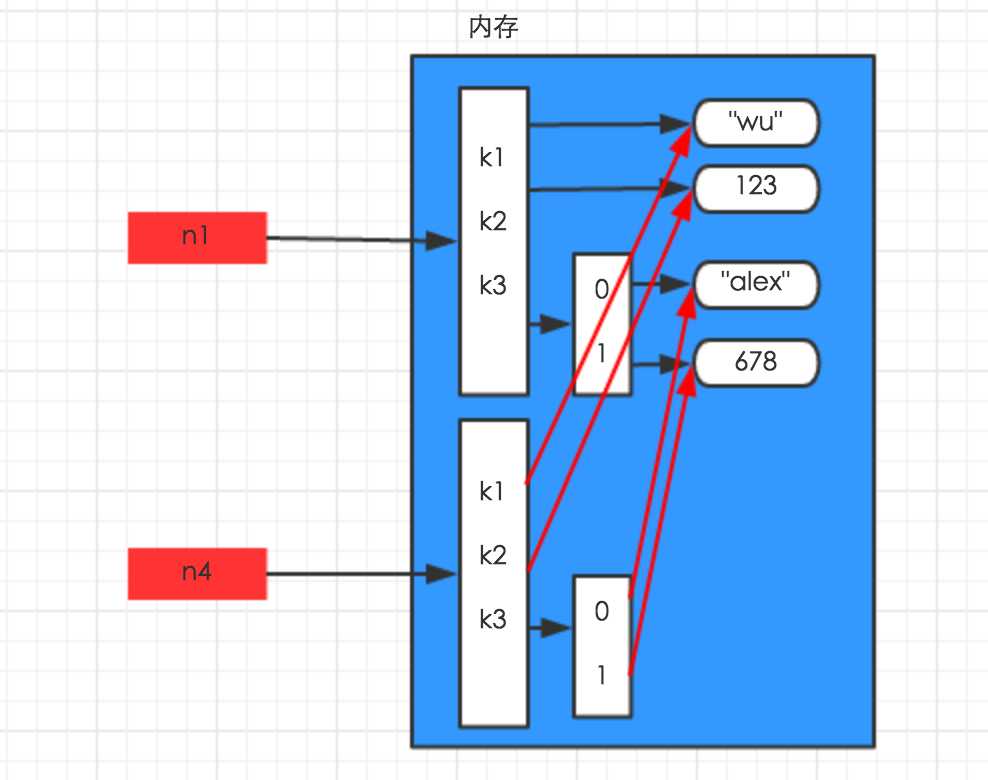
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
|
1
2
3
4
5
|
import copyn1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}n4 = copy.deepcopy(n1) |
一、背景
在学习函数之前,一直遵循:面向过程编程,即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处,如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
while True: if cpu利用率 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 硬盘使用空间 > 90%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 if 内存占用 > 80%: #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 |
腚眼一看上述代码,if条件语句下的内容可以被提取出来公用,如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def 发送邮件(内容) #发送邮件提醒 连接邮箱服务器 发送邮件 关闭连接 while True: if cpu利用率 > 90%: 发送邮件(‘CPU报警‘) if 硬盘使用空间 > 90%: 发送邮件(‘硬盘报警‘) if 内存占用 > 80%: |
对于上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
函数式编程最重要的是增强代码的重用性和可读性
二、定义和使用
|
1
2
3
4
5
|
def 函数名(参数): ... 函数体 ... |
函数的定义主要有如下要点:
以上要点中,比较重要有参数和返回值:
1、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def 发送短信(): 发送短信的代码... if 发送成功: return True else: return False while True: # 每次执行发送短信函数,都会将返回值自动赋值给result # 之后,可以根据result来写日志,或重发等操作 result = 发送短信() if result == False: 记录日志,短信发送失败... |
2、参数
为什么要有参数?
 无参数实现 有参数实现
无参数实现 有参数实现函数的有三中不同的参数:
普通参数 默认参数 动态参数-序列 动态参数-字典 动态参数-序列和字典扩展:发送邮件实例

注:查看详细猛击这里
open函数,该函数用于文件处理
操作文件时,一般需要经历如下步骤:
一、打开文件
|
1
|
文件句柄 = open(‘文件路径‘, ‘模式‘) |
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
"+" 表示可以同时读写某个文件
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
二、操作
Python 2.x Python 3.x三、管理上下文
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
|
1
2
3
|
with open(‘log‘,‘r‘) as f: ... |
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
|
1
2
|
with open(‘log1‘) as obj1, open(‘log2‘) as obj2: pass |
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
|
1
2
3
4
5
6
7
8
|
# 普通条件语句if 1 == 1: name = ‘wupeiqi‘else: name = ‘alex‘ # 三元运算name = ‘wupeiqi‘ if 1 == 1 else ‘alex‘ |
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# ###################### 普通函数 ####################### 定义函数(普通方式)def func(arg): return arg + 1 # 执行函数result = func(123) # ###################### lambda ###################### # 定义函数(lambda表达式)my_lambda = lambda arg : arg + 1 # 执行函数result = my_lambda(123) |
lambda存在意义就是对简单函数的简洁表示
利用函数编写如下数列:
斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368...
|
1
2
3
4
5
6
7
8
|
def func(arg1,arg2): if arg1 == 0: print arg1, arg2 arg3 = arg1 + arg2 print arg3 func(arg2, arg3)func(0,1) |
装饰器是函数,只不过该函数可以具有特殊的含义,装饰器用来装饰函数或类,使用装饰器可以在函数执行前和执行后添加相应操作。
|
1
2
3
4
5
6
7
8
9
10
|
def wrapper(func): def result(): print ‘before‘ func() print ‘after‘ return result @wrapperdef foo(): print ‘foo‘ |
View Code详细猛击这里
标签:
原文地址:http://www.cnblogs.com/heton/p/5811347.html