标签:
HashMap本身没有什么问题,有没有问题取决于你是如何使用它的。比如,你在一个线程里初始化了一个HashMap然后在多个其他线程里对其进行读取,这肯定没有任何问题。有个例子就是使用HashMap来存储系统配置项。当有多于一个线程对HashMap进行修改操作的时候才会真正产生问题,比如增加、删除、更新键值对的时候。因为put()操作可以造成重新分配存储大小(re-sizeing)的动作,因此有可能造成无限循环的发生,所以这时需要使用Hashtable或者ConcurrentHashMap,而后者更优。
这个问题非常好,每个人可能都会有自己的体会。按照我掌握的知识来说,如果一个计算hash的方法写得不好,直接的影响是,当向HashMap中添加元素的时候会更频繁地造成冲突,因此最终增加了耗时。但是自从Java 8开始,这种影响不再像前几个版本那样显著了,因为当冲突的发生超出了一定的限度之后,链表类的实现将会被替换成二叉树(binary tree)实现,这时你仍可以得到O(logN)的开销,优于链表类的O(n)。
不尽然,因为你可以通过将成员声明成非final且private,并且不要在除了构造函数的其他地方来修改它。不要为它们提供setter方法,同时不会通过任何函数泄露出对此成员的引用。需要记住的是,把对象声明成final仅仅保证了它不会被重新赋上另外一个值,你仍然可以通过此引用来修改引用对象的属性。这一点是关键,面试官通常喜欢听到你强调这一点。
又一个Java面试的好问题,你应该答出“substring方法通过原字符串创建了一个新的对象”,否则你的回答肯定是不能令人满意的。这个问题也经常被拿来测试应聘者对于substring()可能带来的内存泄漏风险是否有所了解。直到Java 1.7版本之前,substring会保存一份原字符串的字符数组的引用,这意味着,如果你从1GB大小的字符串里截取了5个字符,而这5个字符也会阻止那1GB内存被回收,因为这个引用是强引用。
到了Java 1.7,这个问题被解决了,原字符串的字符数组已经不再被引用,但是这个改变也使得substring()创建字符串的操作更加耗时,以前的开销是O(1),现在最坏情况是O(n)。

这算是Java一个比较核心的问题了,面试官期望你能知道在写单例模式时应该对实例的初始化与否进行双重检查。记住对实例的声明使用Volatile关键字,以保证单例模式是线程安全的。下面是一段示例,展示了如何用一种线程安全的方式实现了单例模式:
public class Singleton {
private static volatile Singleton _instance;
/**
* Double checked locking code on Singleton
* @return Singelton instance
*/
public static Singleton getInstance() {
if (_instance == null) {
synchronized (Singleton.class) {
if (_instance == null) {
_instance = new Singleton();
}
}
}
return _instance;
}
}
这是个很棘手的Java面试题,答案也并不固定。我的答案是,写存储过程的时候一旦有操作失败,则一定要返回错误码。但是在调用存储过程的时候出错的话捕捉SQLException却是唯一能做的。
此问题来自另外一篇文章,《15个最流行的java多线程面试问题》,现在对熟练掌握并发技能的开发者的需求越来越大,因此这个问题也越来越引起大家的重视。答案是:前者返回一个Future对象,可以通过这个对象来获得工作线程执行的结果。
当我们考察异常处理的时候,又会发现另外一个不同。当你使用execute提交的任务抛出异常时,此异常将会交由未捕捉异常处理过程来处理(uncaught exception handler),当你没有显式指定一个异常处理器的话,默认情况下仅仅会通过System.err打印出错误堆栈。当你用submit来提交一个任务的时候,这个任务一旦抛出异常(无论是否是运行时异常),那这个异常是任务返回对象的一部分。对这样一种情形,当你调用Future.get()方法的时候,这个方法会重新抛出这个异常,并且会使用ExecutionException进行包装。
抽象工厂模式提供了多一级的抽象。不同的工厂类都继承了同一个抽象工厂方法,但是却根据工厂的类别创建不同的对象。例如,AutomobileFactory, UserFactory, RoleFactory都继承了AbstractFactory,但是每个工厂类创建自己对应类型的对象。下面是工厂模式和抽象工厂模式对应的UML图。

在Java中,单例类是指那些在整个Java程序中只存在一份实例的类,例如java.lang.Runtime就是一个单例类。在Java 4版本及以前创建单例会有些麻烦,但是自从Java 5引入了Enum类型之后,事情就变得简单了。可以去看看我的关于如何使用Enum来创建单例类的文章,同时再看看问题五来看看如何在创建单例类的时候进行双重检查。
事实上,用Java可以有四种方式来遍历任何一个Map,一种是使用keySet()方法获取所有的键,然后遍历这些键,再依次通过get()方法来获取对应的值。第二种方法可以使用entrySet()来获取键值对的集合,然后使用for each语句来遍历这个集合,遍历的时候获得的每个键值对已经包含了键和值。这种算是一种更优的方式,因为每轮遍历的时候同时获得了key和value,无需再调用get()方法,get()方法在那种如果bucket位置有一个巨大的链表的时候的性能开销是O(n)。第三种方法是获取entrySet之后用iterator依次获取每个键值对。第四种方法是获得key set之后用iterator依次获取每个key,然后再根据key来调用get方法。
当你需要根据业务逻辑来进行相等性判断、而不是根据对象相等性来判断的时候你就需要重写这两个函数了。例如,两个Employee对象相等的依据是它们拥有相同的emp_id,尽管它们有可能是两个不同的Object对象,并且分别在不同的地方被创建。同时,如果你准备把它们当作HashMap中的key来使用的话,你也必须重写这两个方法。现在,作为Java中equals-hashcode的一个约定,当你重写equals的时候必须也重写hashcode,否则你会打破诸如Set, Map等集合赖以正常工作的约定。你可以看看我的另外一篇博文来理解这两个方法之间的微妙区别与联系。
如果不重写equals方法的话,equals和hashCode之间的约定就会被打破:当通过equals方法返回相等的两个对象,他们的hashCode也必须一样。如果不重写hashCode方法的话,即使是使用equals方法返回值为true的两个对象,当它们插入同一个map的时候,因为hashCode返回不同所以仍然会被插入到两个不同的位置。这样就打破了HashMap的本来目的,因为Map本身不允许存进去两个key相同的值。当使用put方法插入一个的时候,HashMap会先计算对象的hashcode,然后根据它来找到存储位置(bucket),然后遍历此存储位置上所有的Map.Entry对象来查看是否与待插入对象相同。如果没有提供hashCode的话,这些就都做不到了。
答案是:仅仅同步关键部分(Critical Section)。这是因为,如果我们同步整个方法的话,每次有线程调用getInstance()方法的时候都会等待其他线程调用完成才行,即使在此方法中并没有执行对象的创建操作。换句话说,我们只需要同步那些创建对象的代码,而创建对象的代码只会执行一次。一旦对象创建完成之后,根本没有必要再对方法进行同步保护了。事实上,从性能上来说,对方法进行同步保护这种编码方法非常要命,因为它会使性能降低10到20倍。下面是单例模式的UML图。

再补充一下,创建线程安全的单例对象有多种方法,你也可以顺便提一下。
这个问题算是对问题十二的补充,应聘者应该知道的是,一旦你提到了hashCode()方法,人们很可能要问HashMap是如何使用这个函数的。当你向HashMap插入一个key的时候,首先,这个对象的hashCode()方法会被调用,调用结果用来计算将要存储的位置(bucket)。
因为某个位置上可能以链表的方式已经包含了多个Map.Entry对象,所以HashMap会使用equals()方法来将此对象与所有这些Map.Entry所包含的key进行对比,以确定此key对象是否已经存在。
你可以通过打破互相等待的局面来避免死锁。为了达到这一点,你需要在代码中合理地安排获取和释放锁的顺序。如果获得锁的顺序是固定的,并且获得的顺序和释放的顺序刚好相反的话,就不会产生出现死锁的条件了。
当我们使用new String构造器来创建字符串的时候,字符串的值会在堆中创建,而不会加入JVM的字符串池中。相反,使用字面值创建的String对象会被放入堆的PermGen段中。例如:
String str=new String(“Test”);
这句代码创建的对象str不会放入字符串池中,我们需要显式调用String.intern()方法来将它放入字符串池中。仅仅当你使用字面值创建字符串时,Java才会自动将它放入字符串池中,比如:String s=”Test”。顺便提一下,这里有个容易被忽视的地方,当我们将参数“Test”传入构造器的时候,这个参数是个字面值,因此它也会在字符串池中保存另外一份。想了解更多关于字面值字符串和字符串对象之间的差别,请看这篇文章。
下图很好地解释了这种差异。

不可修改对象是那些一旦被创建就不能修改的对象。对这种对象的任何改动的后果都是会创建一个新的对象,而不是在原对象本身做修改。例如Java中的String类就是不可修改的。大多数这样的类通常都是final类型的,因为这样可以避免自己被继承继而被覆盖方法,在覆盖的方法里,不可修改的特性就难以得到保证了。你通常也可以通过将类的成员设置成private但是非final的来获得同样的效果。
另外,你同样要保证你的类不要通过任何方法暴露成员,特别是那些可修改类型的成员。同样地,当你的方法接收客户类传入的可修改对象的话,你应该使用一个复制的对象来防止客户代码来修改这个刚传入的可修改类。比如,传入java.util.Date对象的话,你应该自己使用clone()方法来获得一个副本。
当你通过类函数返回一个可修改对象的时候,你也要采取类似的防护措施,返回一个类成功的副本,防止客户代码通过此引用修改了成员对象的属性。千万不要直接把你的可修改成员直接返回给客户代码。
在执行此方法之前和之后获取一个系统时间,取这两个时间的差值,即可得到此方法所花费的时间。
需要注意的是,如果执行此方法花费的时间非常短,那么得到的时间值有可能是0ms。这时你可以在一个计算量比较大的方法上试一下效果。
long start=System.currentTimeMillis();
method();
long end=System.currentTimeMillis();
System.out.println("Time taken for execution is "+(end-start));
为了使类可以在HashMap或Hashtable中作为key使用,必须要实现这个类自己的equals()和hashCode()方法。具体请参考问题十四。
我把这最后一个问题留给你做练习吧,你可以在我给出答案之前好好思索一下。我确信你能够找到正确的方法的,因为这是将类的实现掌控在自己手中的一个重要的方法,同时也能为以后的维护提供巨大的好处。
除了你看到的惊人的问题数量,我也尽量保证质量。我不止一次分享各个重要主题中的问题,也确保包含所谓的高级话题,这些话题很多程序员不喜欢准备或者直接放弃,因为他们的工作不会涉及到这些。Java NIO 和 JVM 底层就是最好的例子。你也可以将设计模式划分到这一类中,但是越来越多有经验的程序员了解 GOF 设计模式并应用这些模式。我也尽量在这个列表中包含 2015 年最新的面试问题,这些问题可能是来年关注的核心。为了给你一个大致的了解,下面列出这份 Java 面试问题列表包含的主题:
多线程,并发及线程基础
数据类型转换的基本原则
垃圾回收(GC)
Java 集合框架
数组
字符串
GOF 设计模式
SOLID (单一功能、开闭原则、里氏替换、接口隔离以及依赖反转)设计原则
抽象类与接口
Java 基础,如 equals 和 hashcode
泛型与枚举
Java IO 与 NIO
常用网络协议
Java 中的数据结构和算法
正则表达式
JVM 底层
Java 最佳实践
JDBC
Date, Time 与 Calendar
Java 处理 XML
JUnit
编程
现在是时候给你展示我近 5 年从各种面试中收集来的 120 个问题了。我确定你在自己的面试中见过很多这些问题,很多问题你也能正确回答。
1)Java 中能创建 Volatile 数组吗?
能,Java 中可以创建 volatile 类型数组,不过只是一个指向数组的引用,而不是整个数组。我的意思是,如果改变引用指向的数组,将会受到 volatile 的保护,但是如果多个线程同时改变数组的元素,volatile 标示符就不能起到之前的保护作用了。
2)volatile 能使得一个非原子操作变成原子操作吗?
一个典型的例子是在类中有一个 long 类型的成员变量。如果你知道该成员变量会被多个线程访问,如计数器、价格等,你最好是将其设置为 volatile。为什么?因为 Java 中读取 long 类型变量不是原子的,需要分成两步,如果一个线程正在修改该 long 变量的值,另一个线程可能只能看到该值的一半(前 32 位)。但是对一个 volatile 型的 long 或 double 变量的读写是原子。
3)volatile 修饰符的有过什么实践?
一种实践是用 volatile 修饰 long 和 double 变量,使其能按原子类型来读写。double 和 long 都是64位宽,因此对这两种类型的读是分为两部分的,第一次读取第一个 32 位,然后再读剩下的 32 位,这个过程不是原子的,但 Java 中 volatile 型的 long 或 double 变量的读写是原子的。volatile 修复符的另一个作用是提供内存屏障(memory barrier),例如在分布式框架中的应用。简单的说,就是当你写一个 volatile 变量之前,Java 内存模型会插入一个写屏障(write barrier),读一个 volatile 变量之前,会插入一个读屏障(read barrier)。意思就是说,在你写一个 volatile 域时,能保证任何线程都能看到你写的值,同时,在写之前,也能保证任何数值的更新对所有线程是可见的,因为内存屏障会将其他所有写的值更新到缓存。
4)volatile 类型变量提供什么保证?(答案)
volatile 变量提供顺序和可见性保证,例如,JVM 或者 JIT为了获得更好的性能会对语句重排序,但是 volatile 类型变量即使在没有同步块的情况下赋值也不会与其他语句重排序。 volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。某些情况下,volatile 还能提供原子性,如读 64 位数据类型,像 long 和 double 都不是原子的,但 volatile 类型的 double 和 long 就是原子的。
5) 10 个线程和 2 个线程的同步代码,哪个更容易写?
从写代码的角度来说,两者的复杂度是相同的,因为同步代码与线程数量是相互独立的。但是同步策略的选择依赖于线程的数量,因为越多的线程意味着更大的竞争,所以你需要利用同步技术,如锁分离,这要求更复杂的代码和专业知识。
6)你是如何调用 wait()方法的?使用 if 块还是循环?为什么?(答案)
wait() 方法应该在循环调用,因为当线程获取到 CPU 开始执行的时候,其他条件可能还没有满足,所以在处理前,循环检测条件是否满足会更好。下面是一段标准的使用 wait 和 notify 方法的代码:
// The standard idiom for using the wait method
synchronized (obj) {
while (condition does not hold)
obj.wait(); // (Releases lock, and reacquires on wakeup)
... // Perform action appropriate to condition
}
参见 Effective Java 第 69 条,获取更多关于为什么应该在循环中来调用 wait 方法的内容。
7)什么是多线程环境下的伪共享(false sharing)?
伪共享是多线程系统(每个处理器有自己的局部缓存)中一个众所周知的性能问题。伪共享发生在不同处理器的上的线程对变量的修改依赖于相同的缓存行,如下图所示:
伪共享问题很难被发现,因为线程可能访问完全不同的全局变量,内存中却碰巧在很相近的位置上。如其他诸多的并发问题,避免伪共享的最基本方式是仔细审查代码,根据缓存行来调整你的数据结构。
8)什么是 Busy spin?我们为什么要使用它?
Busy spin 是一种在不释放 CPU 的基础上等待事件的技术。它经常用于避免丢失 CPU 缓存中的数据(如果线程先暂停,之后在其他CPU上运行就会丢失)。所以,如果你的工作要求低延迟,并且你的线程目前没有任何顺序,这样你就可以通过循环检测队列中的新消息来代替调用 sleep() 或 wait() 方法。它唯一的好处就是你只需等待很短的时间,如几微秒或几纳秒。LMAX 分布式框架是一个高性能线程间通信的库,该库有一个 BusySpinWaitStrategy 类就是基于这个概念实现的,使用 busy spin 循环 EventProcessors 等待屏障。
9)Java 中怎么获取一份线程 dump 文件?
在 Linux 下,你可以通过命令 kill -3 PID (Java 进程的进程 ID)来获取 Java 应用的 dump 文件。在 Windows 下,你可以按下 Ctrl + Break 来获取。这样 JVM 就会将线程的 dump 文件打印到标准输出或错误文件中,它可能打印在控制台或者日志文件中,具体位置依赖应用的配置。如果你使用Tomcat。
10)Swing 是线程安全的?(答案)
不是,Swing 不是线程安全的。你不能通过任何线程来更新 Swing 组件,如 JTable、JList 或 JPanel,事实上,它们只能通过 GUI 或 AWT 线程来更新。这就是为什么 Swing 提供 invokeAndWait() 和 invokeLater() 方法来获取其他线程的 GUI 更新请求。这些方法将更新请求放入 AWT 的线程队列中,可以一直等待,也可以通过异步更新直接返回结果。你也可以在参考答案中查看和学习到更详细的内容。
11)什么是线程局部变量?(答案)
线程局部变量是局限于线程内部的变量,属于线程自身所有,不在多个线程间共享。Java 提供 ThreadLocal 类来支持线程局部变量,是一种实现线程安全的方式。但是在管理环境下(如 web 服务器)使用线程局部变量的时候要特别小心,在这种情况下,工作线程的生命周期比任何应用变量的生命周期都要长。任何线程局部变量一旦在工作完成后没有释放,Java 应用就存在内存泄露的风险。
12)用 wait-notify 写一段代码来解决生产者-消费者问题?(答案)
请参考答案中的示例代码。只要记住在同步块中调用 wait() 和 notify()方法,如果阻塞,通过循环来测试等待条件。
13) 用 Java 写一个线程安全的单例模式(Singleton)?(答案)
请参考答案中的示例代码,这里面一步一步教你创建一个线程安全的 Java 单例类。当我们说线程安全时,意思是即使初始化是在多线程环境中,仍然能保证单个实例。Java 中,使用枚举作为单例类是最简单的方式来创建线程安全单例模式的方式。
14)Java 中 sleep 方法和 wait 方法的区别?(答案)
虽然两者都是用来暂停当前运行的线程,但是 sleep() 实际上只是短暂停顿,因为它不会释放锁,而 wait() 意味着条件等待,这就是为什么该方法要释放锁,因为只有这样,其他等待的线程才能在满足条件时获取到该锁。
15)什么是不可变对象(immutable object)?Java 中怎么创建一个不可变对象?(答案)
不可变对象指对象一旦被创建,状态就不能再改变。任何修改都会创建一个新的对象,如 String、Integer及其它包装类。详情参见答案,一步一步指导你在 Java 中创建一个不可变的类。
16)我们能创建一个包含可变对象的不可变对象吗?
是的,我们是可以创建一个包含可变对象的不可变对象的,你只需要谨慎一点,不要共享可变对象的引用就可以了,如果需要变化时,就返回原对象的一个拷贝。最常见的例子就是对象中包含一个日期对象的引用。
17)Java 中应该使用什么数据类型来代表价格?(答案)
如果不是特别关心内存和性能的话,使用BigDecimal,否则使用预定义精度的 double 类型。
18)怎么将 byte 转换为 String?(答案)
可以使用 String 接收 byte[] 参数的构造器来进行转换,需要注意的点是要使用的正确的编码,否则会使用平台默认编码,这个编码可能跟原来的编码相同,也可能不同。
19)Java 中怎样将 bytes 转换为 long 类型?
这个问题你来回答![]()
20)我们能将 int 强制转换为 byte 类型的变量吗?如果该值大于 byte 类型的范围,将会出现什么现象?
是的,我们可以做强制转换,但是 Java 中 int 是 32 位的,而 byte 是 8 位的,所以,如果强制转化是,int 类型的高 24 位将会被丢弃,byte 类型的范围是从 -128 到 128。
21)存在两个类,B 继承 A,C 继承 B,我们能将 B 转换为 C 么?如 C = (C) B;(answer答案)
22)哪个类包含 clone 方法?是 Cloneable 还是 Object?(答案)
java.lang.Cloneable 是一个标示性接口,不包含任何方法,clone 方法在 object 类中定义。并且需要知道 clone() 方法是一个本地方法,这意味着它是由 c 或 c++ 或 其他本地语言实现的。
23)Java 中 ++ 操作符是线程安全的吗?(答案)
23)不是线程安全的操作。它涉及到多个指令,如读取变量值,增加,然后存储回内存,这个过程可能会出现多个线程交差。
24)a = a + b 与 a += b 的区别(答案)
+= 隐式的将加操作的结果类型强制转换为持有结果的类型。如果两这个整型相加,如 byte、short 或者 int,首先会将它们提升到 int 类型,然后在执行加法操作。如果加法操作的结果比 a 的最大值要大,则 a+b 会出现编译错误,但是 a += b 没问题,如下:
byte a = 127;
byte b = 127;
b = a + b; // error : cannot convert from int to byte
b += a; // ok
(译者注:这个地方应该表述的有误,其实无论 a+b 的值为多少,编译器都会报错,因为 a+b 操作会将 a、b 提升为 int 类型,所以将 int 类型赋值给 byte 就会编译出错)
25)我能在不进行强制转换的情况下将一个 double 值赋值给 long 类型的变量吗?(答案)
不行,你不能在没有强制类型转换的前提下将一个 double 值赋值给 long 类型的变量,因为 double 类型的范围比 long 类型更广,所以必须要进行强制转换。
26)3*0.1 == 0.3 将会返回什么?true 还是 false?(答案)
false,因为有些浮点数不能完全精确的表示出来。
27)int 和 Integer 哪个会占用更多的内存?(答案)
Integer 对象会占用更多的内存。Integer 是一个对象,需要存储对象的元数据。但是 int 是一个原始类型的数据,所以占用的空间更少。
28)为什么 Java 中的 String 是不可变的(Immutable)?(answer答案)
Java 中的 String 不可变是因为 Java 的设计者认为字符串使用非常频繁,将字符串设置为不可变可以允许多个客户端之间共享相同的字符串。更详细的内容参见答案。
29)我们能在 Switch 中使用 String 吗?(answer答案)
从 Java 7 开始,我们可以在 switch case 中使用字符串,但这仅仅是一个语法糖。内部实现在 switch 中使用字符串的 hash code。
30)Java 中的构造器链是什么?(answer答案)
当你从一个构造器中调用另一个构造器,就是Java 中的构造器链。这种情况只在重载了类的构造器的时候才会出现。
31)64 位 JVM 中,int 的长度是多数?
Java 中,int 类型变量的长度是一个固定值,与平台无关,都是 32 位。意思就是说,在 32 位 和 64 位 的Java 虚拟机中,int 类型的长度是相同的。
32)Serial 与 Parallel GC之间的不同之处?(答案)
Serial 与 Parallel 在GC执行的时候都会引起 stop-the-world。它们之间主要不同 serial 收集器是默认的复制收集器,执行 GC 的时候只有一个线程,而 parallel 收集器使用多个 GC 线程来执行。
33)32 位和 64 位的 JVM,int 类型变量的长度是多数?(答案)
32 位和 64 位的 JVM 中,int 类型变量的长度是相同的,都是 32 位或者 4 个字节。
34)Java 中 WeakReference 与 SoftReference的区别?(答案)
虽然 WeakReference 与 SoftReference 都有利于提高 GC 和 内存的效率,但是 WeakReference ,一旦失去最后一个强引用,就会被 GC 回收,而软引用虽然不能阻止被回收,但是可以延迟到 JVM 内存不足的时候。
35)WeakHashMap 是怎么工作的?(答案)
WeakHashMap 的工作与正常的 HashMap 类似,但是使用弱引用作为 key,意思就是当 key 对象没有任何引用时,key/value 将会被回收。
36)JVM 选项 -XX:+UseCompressedOops 有什么作用?为什么要使用?(答案)
当你将你的应用从 32 位的 JVM 迁移到 64 位的 JVM 时,由于对象的指针从 32 位增加到了 64 位,因此堆内存会突然增加,差不多要翻倍。这也会对 CPU 缓存(容量比内存小很多)的数据产生不利的影响。因为,迁移到 64 位的 JVM 主要动机在于可以指定最大堆大小,通过压缩 OOP 可以节省一定的内存。通过 -XX:+UseCompressedOops 选项,JVM 会使用 32 位的 OOP,而不是 64 位的 OOP。
37)怎样通过 Java 程序来判断 JVM 是 32 位 还是 64 位?(答案)
你可以检查某些系统属性如 sun.arch.data.model 或 os.arch 来获取该信息。
38)32 位 JVM 和 64 位 JVM 的最大堆内存分别是多数?(答案)
理论上说上 32 位的 JVM 堆内存可以到达 2^32,即 4GB,但实际上会比这个小很多。不同操作系统之间不同,如 Windows 系统大约 1.5 GB,Solaris 大约 3GB。64 位 JVM允许指定最大的堆内存,理论上可以达到 2^64,这是一个非常大的数字,实际上你可以指定堆内存大小到 100GB。甚至有的 JVM,如 Azul,堆内存到 1000G 都是可能的。
39)JRE、JDK、JVM 及 JIT 之间有什么不同?(答案)
JRE 代表 Java 运行时(Java run-time),是运行 Java 引用所必须的。JDK 代表 Java 开发工具(Java development kit),是 Java 程序的开发工具,如 Java 编译器,它也包含 JRE。JVM 代表 Java 虚拟机(Java virtual machine),它的责任是运行 Java 应用。JIT 代表即时编译(Just In Time compilation),当代码执行的次数超过一定的阈值时,会将 Java 字节码转换为本地代码,如,主要的热点代码会被准换为本地代码,这样有利大幅度提高 Java 应用的性能。
3 年工作经验的 Java 面试题
40)解释 Java 堆空间及 GC?(答案)
当通过 Java 命令启动 Java 进程的时候,会为它分配内存。内存的一部分用于创建堆空间,当程序中创建对象的时候,就从对空间中分配内存。GC 是 JVM 内部的一个进程,回收无效对象的内存用于将来的分配。
41)你能保证 GC 执行吗?(答案)
不能,虽然你可以调用 System.gc() 或者 Runtime.gc(),但是没有办法保证 GC 的执行。
42)怎么获取 Java 程序使用的内存?堆使用的百分比?
可以通过 java.lang.Runtime 类中与内存相关方法来获取剩余的内存,总内存及最大堆内存。通过这些方法你也可以获取到堆使用的百分比及堆内存的剩余空间。Runtime.freeMemory() 方法返回剩余空间的字节数,Runtime.totalMemory() 方法总内存的字节数,Runtime.maxMemory() 返回最大内存的字节数。
43)Java 中堆和栈有什么区别?(答案)
JVM 中堆和栈属于不同的内存区域,使用目的也不同。栈常用于保存方法帧和局部变量,而对象总是在堆上分配。栈通常都比堆小,也不会在多个线程之间共享,而堆被整个 JVM 的所有线程共享。

44)“a==b”和”a.equals(b)”有什么区别?(答案)
如果 a 和 b 都是对象,则 a==b 是比较两个对象的引用,只有当 a 和 b 指向的是堆中的同一个对象才会返回 true,而 a.equals(b) 是进行逻辑比较,所以通常需要重写该方法来提供逻辑一致性的比较。例如,String 类重写 equals() 方法,所以可以用于两个不同对象,但是包含的字母相同的比较。
45)a.hashCode() 有什么用?与 a.equals(b) 有什么关系?(答案)
hashCode() 方法是相应对象整型的 hash 值。它常用于基于 hash 的集合类,如 Hashtable、HashMap、LinkedHashMap等等。它与 equals() 方法关系特别紧密。根据 Java 规范,两个使用 equal() 方法来判断相等的对象,必须具有相同的 hash code。
46)final、finalize 和 finally 的不同之处?(答案)
final 是一个修饰符,可以修饰变量、方法和类。如果 final 修饰变量,意味着该变量的值在初始化后不能被改变。finalize 方法是在对象被回收之前调用的方法,给对象自己最后一个复活的机会,但是什么时候调用 finalize 没有保证。finally 是一个关键字,与 try 和 catch 一起用于异常的处理。finally 块一定会被执行,无论在 try 块中是否有发生异常。
47)Java 中的编译期常量是什么?使用它又什么风险?
公共静态不可变(public static final )变量也就是我们所说的编译期常量,这里的 public 可选的。实际上这些变量在编译时会被替换掉,因为编译器知道这些变量的值,并且知道这些变量在运行时不能改变。这种方式存在的一个问题是你使用了一个内部的或第三方库中的公有编译时常量,但是这个值后面被其他人改变了,但是你的客户端仍然在使用老的值,甚至你已经部署了一个新的jar。为了避免这种情况,当你在更新依赖 JAR 文件时,确保重新编译你的程序。
这部分也包含数据结构、算法及数组的面试问题
48) List、Set、Map 和 Queue 之间的区别(答案)
List 是一个有序集合,允许元素重复。它的某些实现可以提供基于下标值的常量访问时间,但是这不是 List 接口保证的。Set 是一个无序集合。
49)poll() 方法和 remove() 方法的区别?
poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常。
50)Java 中 LinkedHashMap 和 PriorityQueue 的区别是什么?(答案)
PriorityQueue 保证最高或者最低优先级的的元素总是在队列头部,但是 LinkedHashMap 维持的顺序是元素插入的顺序。当遍历一个 PriorityQueue 时,没有任何顺序保证,但是 LinkedHashMap 课保证遍历顺序是元素插入的顺序。
51)ArrayList 与 LinkedList 的不区别?(答案)
最明显的区别是 ArrrayList 底层的数据结构是数组,支持随机访问,而 LinkedList 的底层数据结构书链表,不支持随机访问。使用下标访问一个元素,ArrayList 的时间复杂度是 O(1),而 LinkedList 是 O(n)。更多细节的讨论参见答案。
52)用哪两种方式来实现集合的排序?(答案)
你可以使用有序集合,如 TreeSet 或 TreeMap,你也可以使用有顺序的的集合,如 list,然后通过 Collections.sort() 来排序。
53)Java 中怎么打印数组?(answer答案)
你可以使用 Arrays.toString() 和 Arrays.deepToString() 方法来打印数组。由于数组没有实现 toString() 方法,所以如果将数组传递给 System.out.println() 方法,将无法打印出数组的内容,但是 Arrays.toString() 可以打印每个元素。
54)Java 中的 LinkedList 是单向链表还是双向链表?(答案)
是双向链表,你可以检查 JDK 的源码。在 Eclipse,你可以使用快捷键 Ctrl + T,直接在编辑器中打开该类。
55)Java 中的 TreeMap 是采用什么树实现的?(答案)
Java 中的 TreeMap 是使用红黑树实现的。
56) Hashtable 与 HashMap 有什么不同之处?(答案)
这两个类有许多不同的地方,下面列出了一部分:
a) Hashtable 是 JDK 1 遗留下来的类,而 HashMap 是后来增加的。
b)Hashtable 是同步的,比较慢,但 HashMap 没有同步策略,所以会更快。
c)Hashtable 不允许有个空的 key,但是 HashMap 允许出现一个 null key。
更多的不同之处参见答案。
57)Java 中的 HashSet,内部是如何工作的?(answer答案)
HashSet 的内部采用 HashMap来实现。由于 Map 需要 key 和 value,所以所有 key 的都有一个默认 value。类似于 HashMap,HashSet 不允许重复的 key,只允许有一个null key,意思就是 HashSet 中只允许存储一个 null 对象。
58)写一段代码在遍历 ArrayList 时移除一个元素?(答案)
该问题的关键在于面试者使用的是 ArrayList 的 remove() 还是 Iterator 的 remove()方法。这有一段示例代码,是使用正确的方式来实现在遍历的过程中移除元素,而不会出现 ConcurrentModificationException 异常的示例代码。
59)我们能自己写一个容器类,然后使用 for-each 循环码?
可以,你可以写一个自己的容器类。如果你想使用 Java 中增强的循环来遍历,你只需要实现 Iterable 接口。如果你实现 Collection 接口,默认就具有该属性。
60)ArrayList 和 HashMap 的默认大小是多数?(答案)
在 Java 7 中,ArrayList 的默认大小是 10 个元素,HashMap 的默认大小是16个元素(必须是2的幂)。这就是 Java 7 中 ArrayList 和 HashMap 类的代码片段:
// from ArrayList.java JDK 1.7
private static final int DEFAULT_CAPACITY = 10;
//from HashMap.java JDK 7
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
61)有没有可能两个不相等的对象有有相同的 hashcode?
有可能,两个不相等的对象可能会有相同的 hashcode 值,这就是为什么在 hashmap 中会有冲突。相等 hashcode 值的规定只是说如果两个对象相等,必须有相同的hashcode 值,但是没有关于不相等对象的任何规定。
62)两个相同的对象会有不同的的 hash code 吗?
不能,根据 hash code 的规定,这是不可能的。
63)我们可以在 hashcode() 中使用随机数字吗?(答案)
不行,因为对象的 hashcode 值必须是相同的。参见答案获取更多关于 Java 中重写 hashCode() 方法的知识。
64)Java 中,Comparator 与 Comparable 有什么不同?(答案)
Comparable 接口用于定义对象的自然顺序,而 comparator 通常用于定义用户定制的顺序。Comparable 总是只有一个,但是可以有多个 comparator 来定义对象的顺序。
65)为什么在重写 equals 方法的时候需要重写 hashCode 方法?(答案)
因为有强制的规范指定需要同时重写 hashcode 与 equal 是方法,许多容器类,如 HashMap、HashSet 都依赖于 hashcode 与 equals 的规定。
IO 是 Java 面试中一个非常重要的点。你应该很好掌握 Java IO,NIO,NIO2 以及与操作系统,磁盘 IO 相关的基础知识。下面是 Java IO 中经常问的问题。
66)在我 Java 程序中,我有三个 socket,我需要多少个线程来处理?
67)Java 中怎么创建 ByteBuffer?
68)Java 中,怎么读写 ByteBuffer ?
69)Java 采用的是大端还是小端?
70)ByteBuffer 中的字节序是什么?
71)Java 中,直接缓冲区与非直接缓冲器有什么区别?(答案)
72)Java 中的内存映射缓存区是什么?(answer答案)
73)socket 选项 TCP NO DELAY 是指什么?
74)TCP 协议与 UDP 协议有什么区别?(answer答案)
75)Java 中,ByteBuffer 与 StringBuffer有什么区别?(答案)
包含 Java 中各个部分的最佳实践,如集合,字符串,IO,多线程,错误和异常处理,设计模式等等。
76)Java 中,编写多线程程序的时候你会遵循哪些最佳实践?(答案)
这是我在写Java 并发程序的时候遵循的一些最佳实践:
a)给线程命名,这样可以帮助调试。
b)最小化同步的范围,而不是将整个方法同步,只对关键部分做同步。
c)如果可以,更偏向于使用 volatile 而不是 synchronized。
d)使用更高层次的并发工具,而不是使用 wait() 和 notify() 来实现线程间通信,如 BlockingQueue,CountDownLatch 及 Semeaphore。
e)优先使用并发集合,而不是对集合进行同步。并发集合提供更好的可扩展性。
77)说出几点 Java 中使用 Collections 的最佳实践(答案)
这是我在使用 Java 中 Collectionc 类的一些最佳实践:
a)使用正确的集合类,例如,如果不需要同步列表,使用 ArrayList 而不是 Vector。
b)优先使用并发集合,而不是对集合进行同步。并发集合提供更好的可扩展性。
c)使用接口代表和访问集合,如使用List存储 ArrayList,使用 Map 存储 HashMap 等等。
d)使用迭代器来循环集合。
e)使用集合的时候使用泛型。
78)说出至少 5 点在 Java 中使用线程的最佳实践。(答案)
这个问题与之前的问题类似,你可以使用上面的答案。对线程来说,你应该:
a)对线程命名
b)将线程和任务分离,使用线程池执行器来执行 Runnable 或 Callable。
c)使用线程池
79)说出 5 条 IO 的最佳实践(答案)
IO 对 Java 应用的性能非常重要。理想情况下,你不应该在你应用的关键路径上避免 IO 操作。下面是一些你应该遵循的 Java IO 最佳实践:
a)使用有缓冲区的 IO 类,而不要单独读取字节或字符。
b)使用 NIO 和 NIO2
c)在 finally 块中关闭流,或者使用 try-with-resource 语句。
d)使用内存映射文件获取更快的 IO。
80)列出 5 个应该遵循的 JDBC 最佳实践(答案)
有很多的最佳实践,你可以根据你的喜好来例举。下面是一些更通用的原则:
a)使用批量的操作来插入和更新数据
b)使用 PreparedStatement 来避免 SQL 异常,并提高性能。
c)使用数据库连接池
d)通过列名来获取结果集,不要使用列的下标来获取。
81)说出几条 Java 中方法重载的最佳实践?(答案)
下面有几条可以遵循的方法重载的最佳实践来避免造成自动装箱的混乱。
a)不要重载这样的方法:一个方法接收 int 参数,而另个方法接收 Integer 参数。
b)不要重载参数数量一致,而只是参数顺序不同的方法。
c)如果重载的方法参数个数多于 5 个,采用可变参数。
82)在多线程环境下,SimpleDateFormat 是线程安全的吗?(答案)
不是,非常不幸,DateFormat 的所有实现,包括 SimpleDateFormat 都不是线程安全的,因此你不应该在多线程序中使用,除非是在对外线程安全的环境中使用,如 将 SimpleDateFormat 限制在 ThreadLocal 中。如果你不这么做,在解析或者格式化日期的时候,可能会获取到一个不正确的结果。因此,从日期、时间处理的所有实践来说,我强力推荐 joda-time 库。
83)Java 中如何格式化一个日期?如格式化为 ddMMyyyy 的形式?(答案)
Java 中,可以使用 SimpleDateFormat 类或者 joda-time 库来格式日期。DateFormat 类允许你使用多种流行的格式来格式化日期。参见答案中的示例代码,代码中演示了将日期格式化成不同的格式,如 dd-MM-yyyy 或 ddMMyyyy。
84)Java 中,怎么在格式化的日期中显示时区?(答案)
85)Java 中 java.util.Date 与 java.sql.Date 有什么区别?(答案)
86)Java 中,如何计算两个日期之间的差距?(程序)
87)Java 中,如何将字符串 YYYYMMDD 转换为日期?(答案)
89)如何测试静态方法?(答案)
可以使用 PowerMock 库来测试静态方法。
90)怎么利用 JUnit 来测试一个方法的异常?(答案)
91)你使用过哪个单元测试库来测试你的 Java 程序?(答案)
92)@Before 和 @BeforeClass 有什么区别?(答案)
93)怎么检查一个字符串只包含数字?(解决方案)
94)Java 中如何利用泛型写一个 LRU 缓存?(答案<)
95)写一段 Java 程序将 byte 转换为 long?(答案)
95)在不使用 StringBuffer 的前提下,怎么反转一个字符串?(解决方案)
97)Java 中,怎么获取一个文件中单词出现的最高频率?(解决方案)
98)如何检查出两个给定的字符串是反序的?(解决方案)
99)Java 中,怎么打印出一个字符串的所有排列?(解决方案)
100)Java 中,怎样才能打印出数组中的重复元素?(解决方案)
101)Java 中如何将字符串转换为整数?(解决方案)
102)在没有使用临时变量的情况如何交换两个整数变量的值?(解决方案)
这部分包含 Java 面试过程中关于 SOLID 的设计原则,OOP 基础,如类,对象,接口,继承,多态,封装,抽象以及更高级的一些概念,如组合、聚合及关联。也包含了 GOF 设计模式的问题。
103)接口是什么?为什么要使用接口而不是直接使用具体类?
接口用于定义 API。它定义了类必须得遵循的规则。同时,它提供了一种抽象,因为客户端只使用接口,这样可以有多重实现,如 List 接口,你可以使用可随机访问的 ArrayList,也可以使用方便插入和删除的 LinkedList。接口中不允许写代码,以此来保证抽象,但是 Java 8 中你可以在接口声明静态的默认方法,这种方法是具体的。
104)Java 中,抽象类与接口之间有什么不同?(答案)
Java 中,抽象类和接口有很多不同之处,但是最重要的一个是 Java 中限制一个类只能继承一个类,但是可以实现多个接口。抽象类可以很好的定义一个家族类的默认行为,而接口能更好的定义类型,有助于后面实现多态机制。关于这个问题的讨论请查看答案。
105)除了单例模式,你在生产环境中还用过什么设计模式?
这需要根据你的经验来回答。一般情况下,你可以说依赖注入,工厂模式,装饰模式或者观察者模式,随意选择你使用过的一种即可。不过你要准备回答接下的基于你选择的模式的问题。
106)你能解释一下里氏替换原则吗?(答案)
107) 什么情况下会违反迪米特法则?为什么会有这个问题?(答案)
迪米特法则建议“只和朋友说话,不要陌生人说话”,以此来减少类之间的耦合。
108)适配器模式是什么?什么时候使用?
适配器模式提供对接口的转换。如果你的客户端使用某些接口,但是你有另外一些接口,你就可以写一个适配去来连接这些接口。
109)什么是“依赖注入”和“控制反转”?为什么有人使用?(答案)
110)抽象类是什么?它与接口有什么区别?你为什么要使用过抽象类?(答案)
111)构造器注入和 setter 依赖注入,那种方式更好?(答案)
每种方式都有它的缺点和优点。构造器注入保证所有的注入都被初始化,但是 setter 注入提供更好的灵活性来设置可选依赖。如果使用 XML 来描述依赖,Setter 注入的可读写会更强。经验法则是强制依赖使用构造器注入,可选依赖使用 setter 注入。
112)依赖注入和工程模式之间有什么不同?(答案)
虽然两种模式都是将对象的创建从应用的逻辑中分离,但是依赖注入比工程模式更清晰。通过依赖注入,你的类就是 POJO,它只知道依赖而不关心它们怎么获取。使用工厂模式,你的类需要通过工厂来获取依赖。因此,使用 DI 会比使用工厂模式更容易测试。关于这个话题的更详细讨论请参见答案。
113)适配器模式和装饰器模式有什么区别?(答案)
虽然适配器模式和装饰器模式的结构类似,但是每种模式的出现意图不同。适配器模式被用于桥接两个接口,而装饰模式的目的是在不修改类的情况下给类增加新的功能。
114)适配器模式和代理模式之前有什么不同?(答案)
这个问题与前面的类似,适配器模式和代理模式的区别在于他们的意图不同。由于适配器模式和代理模式都是封装真正执行动作的类,因此结构是一致的,但是适配器模式用于接口之间的转换,而代理模式则是增加一个额外的中间层,以便支持分配、控制或智能访问。
115)什么是模板方法模式?(答案)
模板方法提供算法的框架,你可以自己去配置或定义步骤。例如,你可以将排序算法看做是一个模板。它定义了排序的步骤,但是具体的比较,可以使用 Comparable 或者其语言中类似东西,具体策略由你去配置。列出算法概要的方法就是众所周知的模板方法。
116)什么时候使用访问者模式?(答案)
访问者模式用于解决在类的继承层次上增加操作,但是不直接与之关联。这种模式采用双派发的形式来增加中间层。
117)什么时候使用组合模式?(答案)
组合模式使用树结构来展示部分与整体继承关系。它允许客户端采用统一的形式来对待单个对象和对象容器。当你想要展示对象这种部分与整体的继承关系时采用组合模式。
118)继承和组合之间有什么不同?(答案)
虽然两种都可以实现代码复用,但是组合比继承共灵活,因为组合允许你在运行时选择不同的实现。用组合实现的代码也比继承测试起来更加简单。
119)描述 Java 中的重载和重写?(答案)
重载和重写都允许你用相同的名称来实现不同的功能,但是重载是编译时活动,而重写是运行时活动。你可以在同一个类中重载方法,但是只能在子类中重写方法。重写必须要有继承。
120)Java 中,嵌套公共静态类与顶级类有什么不同?(答案)
类的内部可以有多个嵌套公共静态类,但是一个 Java 源文件只能有一个顶级公共类,并且顶级公共类的名称与源文件名称必须一致。
121) OOP 中的 组合、聚合和关联有什么区别?(答案)
如果两个对象彼此有关系,就说他们是彼此相关联的。组合和聚合是面向对象中的两种形式的关联。组合是一种比聚合更强力的关联。组合中,一个对象是另一个的拥有者,而聚合则是指一个对象使用另一个对象。如果对象 A 是由对象 B 组合的,则 A 不存在的话,B一定不存在,但是如果 A 对象聚合了一个对象 B,则即使 A 不存在了,B 也可以单独存在。
122)给我一个符合开闭原则的设计模式的例子?(答案)
开闭原则要求你的代码对扩展开放,对修改关闭。这个意思就是说,如果你想增加一个新的功能,你可以很容易的在不改变已测试过的代码的前提下增加新的代码。有好几个设计模式是基于开闭原则的,如策略模式,如果你需要一个新的策略,只需要实现接口,增加配置,不需要改变核心逻辑。一个正在工作的例子是 Collections.sort() 方法,这就是基于策略模式,遵循开闭原则的,你不需为新的对象修改 sort() 方法,你需要做的仅仅是实现你自己的 Comparator 接口。
123)抽象工厂模式和原型模式之间的区别?(答案)
124)什么时候使用享元模式?(答案)
享元模式通过共享对象来避免创建太多的对象。为了使用享元模式,你需要确保你的对象是不可变的,这样你才能安全的共享。JDK 中 String 池、Integer 池以及 Long 池都是很好的使用了享元模式的例子。
这部分包含 Java 中关于 XML 的面试题,JDBC 面试题,正则表达式面试题,Java 错误和异常及序列化面试题
125)嵌套静态类与顶级类有什么区别?(答案)
一个公共的顶级类的源文件名称与类名相同,而嵌套静态类没有这个要求。一个嵌套类位于顶级类内部,需要使用顶级类的名称来引用嵌套静态类,如 HashMap.Entry 是一个嵌套静态类,HashMap 是一个顶级类,Entry是一个嵌套静态类。
126)你能写出一个正则表达式来判断一个字符串是否是一个数字吗?(解决方案)
一个数字字符串,只能包含数字,如 0 到 9 以及 +、- 开头,通过这个信息,你可以下一个如下的正则表达式来判断给定的字符串是不是数字。
127)Java 中,受检查异常 和 不受检查异常的区别?(答案)
受检查异常编译器在编译期间检查。对于这种异常,方法强制处理或者通过 throws 子句声明。其中一种情况是 Exception 的子类但不是 RuntimeException 的子类。非受检查是 RuntimeException 的子类,在编译阶段不受编译器的检查。
128)Java 中,throw 和 throws 有什么区别?(答案)
throw 用于抛出 java.lang.Throwable 类的一个实例化对象,意思是说你可以通过关键字 throw 抛出一个 Error 或者 一个Exception,如:
throw new IllegalArgumentException(“size must be multiple of 2″)
而throws 的作用是作为方法声明和签名的一部分,方法被抛出相应的异常以便调用者能处理。Java 中,任何未处理的受检查异常强制在 throws 子句中声明。
129)Java 中,Serializable 与 Externalizable 的区别?(答案)
Serializable 接口是一个序列化 Java 类的接口,以便于它们可以在网络上传输或者可以将它们的状态保存在磁盘上,是 JVM 内嵌的默认序列化方式,成本高、脆弱而且不安全。Externalizable 允许你控制整个序列化过程,指定特定的二进制格式,增加安全机制。
130)Java 中,DOM 和 SAX 解析器有什么不同?(答案)
DOM 解析器将整个 XML 文档加载到内存来创建一棵 DOM 模型树,这样可以更快的查找节点和修改 XML 结构,而 SAX 解析器是一个基于事件的解析器,不会将整个 XML 文档加载到内存。由于这个原因,DOM 比 SAX 更快,也要求更多的内存,不适合于解析大 XML 文件。
131)说出 JDK 1.7 中的三个新特性?(答案)
虽然 JDK 1.7 不像 JDK 5 和 8 一样的大版本,但是,还是有很多新的特性,如 try-with-resource 语句,这样你在使用流或者资源的时候,就不需要手动关闭,Java 会自动关闭。Fork-Join 池某种程度上实现 Java 版的 Map-reduce。允许 Switch 中有 String 变量和文本。菱形操作符(<>)用于类型推断,不再需要在变量声明的右边申明泛型,因此可以写出可读写更强、更简洁的代码。另一个值得一提的特性是改善异常处理,如允许在同一个 catch 块中捕获多个异常。
132)说出 5 个 JDK 1.8 引入的新特性?(答案)
Java 8 在 Java 历史上是一个开创新的版本,下面 JDK 8 中 5 个主要的特性:
Lambda 表达式,允许像对象一样传递匿名函数
Stream API,充分利用现代多核 CPU,可以写出很简洁的代码
Date 与 Time API,最终,有一个稳定、简单的日期和时间库可供你使用
扩展方法,现在,接口中可以有静态、默认方法。
重复注解,现在你可以将相同的注解在同一类型上使用多次。
133)Java 中,Maven 和 ANT 有什么区别?(答案)
虽然两者都是构建工具,都用于创建 Java 应用,但是 Maven 做的事情更多,在基于“约定优于配置”的概念下,提供标准的Java 项目结构,同时能为应用自动管理依赖(应用中所依赖的 JAR 文件),Maven 与 ANT 工具更多的不同之处请参见答案。
下面的输出会正常吗?
package basic;
public class IntegerTest {
public static void main(String[] args) {
System.out.println(Integer.parseInt("1"));
System.out.println(Integer.parseInt("2"));
}
}
解析:将上面代码复制下(不要自己手敲)在自己的环境里运行看看,是不是输出下面错误来了:
1
Exception in thread “main” java.lang.NumberFormatException: For input string: “2”
at java.lang.NumberFormatException.forInputString(Unknown Source)
at java.lang.Integer.parseInt(Unknown Source)
at java.lang.Integer.parseInt(Unknown Source)
at basic.IntegerTest.main(IntegerTest.java:7)
竟然说第二条语句有问题,表面上完全看不出来任何问题是不是!
实际上这里的错误原因涉及到一个概念 — 零宽度空格,可能有人接触过,但相信更多的人甚至都没听过,什么是零宽度空格?它实际上是一个Unicode字符,是一个空格,关键是它没有宽度,因此我们一般肉眼看不到。但可以在vim下看到,上面的第二条语句中的2前面就有一个零宽度空格,放到vim中打开后你会发现是下面这样的语句:
System.out.println(Integer.parseInt("<feff>2"));
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格“(ZEROWIDTHNO-BREAKSPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。因此下面的语句会输出65279,刚好是FEFF。
System.out.println((int)"2".charAt(0));
下面的程序能编译通过么?如果通过,说结果并解释,不能编译,说错误原因。
class A
{
public static int X;
static { X = B.Y + 1;}
}
public class B
{
public static int Y = A.X + 1;
static {}
public static void main(String[] args) {
System.out.println("X = "+A.X+", Y = "+B.Y);
}
}
解析:这个程序能正确运行,类的运行过程如下:
首先加载主类B,初始化静态成员Y,发现需要类A的信息,于是加载类A,初始化静态成员X,也用到B类信息,由于此时B类的Y还未成功加载因此这里是默认值0,从而得到A类的X为1,然后返回到B类,得到Y为2。
关于自动装箱,相信大部分人都明白是怎么一回事,但真的完全明白了嘛?
先看下面的代码:
Short s1 = 1;
Short s2 = s1;
System.out.println(s1 == s2);
谁都知道当然打印true了。现在加一句试试:
Short s1 = 1;
Short s2 = s1;
s1++;
System.out.println(s1 == s2);
还是true吗?No,这次输出成了false。WHY?难道s1和s2引用的不是同一个对象吗?有这些疑问的说明你对自动装箱拆箱的过程还不是非常清楚,实际上上面的代码可以翻译为下面的代码(实际执行过程,要掌握):
Short s1 = new Short((short)1);
Short s2 = s1;
short tempS1 = s1.shortValue();
tempS1++;
s1 = new Short(tempS1);
System.out.println(s1 == s2);
哦,原来如此,这下明白了,因此我们在使用自动装箱的时候小心点为妙。
先来两句代码:
NullTest myNullTest = null;
System.out.println(myNullTest.getInt());
相信很多人看到这段代码时,都会自以为是的说:NullPointerException。果真如此吗?你还没看到NullTest 这个类是如何定义的呢。现在看看这个类的定义:
class NullTest {
public static int getInt() {
return 1;
}
}
发现getInt()方法体没有任何类变量和类方法的使用,因此这里会正常输出1.
记住:类变量和类方法的使用,仅仅依赖引用的类型。即使引用为null,仍然可以调用。从良好实践的角度来看,明智的做法是使用NullTest.getInt()来代替myNullTest.getInt(),但谁不不能保证不会碰到这样的代码,因此还是小心为妙。
变长参数特性带来了一个强大的概念,可以帮助开发者简化代码。不过变长参数的背后是什么呢?Basically,就是一个数组。
public void calc(int... myInts) {}
calc(1, 2, 3);
编译器会将前面的代码翻译成类似这样:
int[] ints = {1, 2, 3};
calc(ints);
不过这里有两点需要注意:
- 当心空调用语句,这相当于传递了一个null作为参数。
calc();
等价于
int[] ints = null;
calc(ints);
- 当然,下面的代码会导致编译错误,因为两条语句是等价的:
public void m1(int[] myInts) { … }
public void m1(int… myInts) { … }
A start() B run() C exit() D getPriority()
答案:ABD
2. 下面关于java.lang.Exception类的说法正确的是()
A 继承自Throwable B Serialable CD 不记得,反正不正确
答案:A
扩展:错误和异常的区别(Error vs Exception)
1) java.lang.Error: Throwable的子类,用于标记严重错误。合理的应用程序不应该去try/catch这种错误。绝大多数的错误都是非正常的,就根本不该出现的。
java.lang.Exception: Throwable的子类,用于指示一种合理的程序想去catch的条件。即它仅仅是一种程序运行条件,而非严重错误,并且鼓励用户程序去catch它。
2) Error和RuntimeException 及其子类都是未检查的异常(unchecked exceptions),而所有其他的Exception类都是检查了的异常(checked exceptions).
checked exceptions: 通常是从一个可以恢复的程序中抛出来的,并且最好能够从这种异常中使用程序恢复。比如FileNotFoundException, ParseException等。检查了的异常发生在编译阶段,必须要使用try…catch(或者throws)否则编译不通过。
unchecked exceptions: 通常是如果一切正常的话本不该发生的异常,但是的确发生了。发生在运行期,具有不确定性,主要是由于程序的逻辑问题所引起的。比如ArrayIndexOutOfBoundException, ClassCastException等。从语言本身的角度讲,程序不该去catch这类异常,虽然能够从诸如RuntimeException这样的异常中catch并恢复,但是并不鼓励终端程序员这么做,因为完全没要必要。因为这类错误本身就是bug,应该被修复,出现此类错误时程序就应该立即停止执行。 因此,面对Errors和unchecked exceptions应该让程序自动终止执行,程序员不该做诸如try/catch这样的事情,而是应该查明原因,修改代码逻辑。
RuntimeException:RuntimeException体系包括错误的类型转换、数组越界访问和试图访问空指针等等。
处理RuntimeException的原则是:如果出现 RuntimeException,那么一定是程序员的错误。例如,可以通过检查数组下标和数组边界来避免数组越界访问异常。其他(IOException等等)checked异常一般是外部错误,例如试图从文件尾后读取数据等,这并不是程序本身的错误,而是在应用环境中出现的外部错误。
3. 下面程序的运行结果是()
String str1 = "hello";
String str2 = "he" + new String("llo");
System.err.println(str1 == str2);
答案:false
解析:因为str2中的llo是新申请的内存块,而==判断的是对象的地址而非值,所以不一样。如果是String str2 = str1,那么就是true了。
4. 下列说法正确的有()
A. class中的constructor不可省略
B. constructor必须与class同名,但方法不能与class同名
C. constructor在一个对象被new时执行
D.一个class只能定义一个constructor
答案:C
解析:这里可能会有误区,其实普通的类方法是可以和类名同名的,和构造方法唯一的区分就是,构造方法没有返回值。
5. 具体选项不记得,但用到的知识如下:
String []a = new String[10];
则:a[0]~a[9] = null
a.length = 10
如果是int []a = new int[10];
则:a[0]~a[9] = 0
a.length = 10
6. 下面程序的运行结果:()
public static void main(String args[]) {
Thread t = new Thread() {
public void run() {
pong();
}
};
t.run();
System.out.print("ping");
}
static void pong() {
System.out.print("pong");
}
A pingpong B pongping C pingpong和pongping都有可能 D 都不输出
答案:B
解析:这里考的是Thread类中start()和run()方法的区别了。start()用来启动一个线程,当调用start方法后,系统才会开启一个新的线程,进而调用run()方法来执行任务,而单独的调用run()就跟调用普通方法是一样的,已经失去线程的特性了。因此在启动一个线程的时候一定要使用start()而不是run()。
7. 下列属于关系型数据库的是()
A. Oracle B MySql C IMS D MongoDB
答案:AB
解答:IMS(Information Management System )数据库是IBM公司开发的两种数据库类型之一;
一种是关系数据库,典型代表产品:DB2;
另一种则是层次数据库,代表产品:IMS层次数据库。
非关系型数据库有MongoDB、memcachedb、Redis等。
8. GC线程是否为守护线程?()
答案:是
解析:线程分为守护线程和非守护线程(即用户线程)。
9. volatile关键字是否能保证线程安全?()
答案:不能
解析:volatile关键字用在多线程同步中,可保证读取的可见性,JVM只是保证从主内存加载到线程工作内存的值是最新的读取值,而非cache中。但多个线程对
volatile的写操作,无法保证线程安全。例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值,在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6;线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6;导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
10. 下列说法正确的是()
A LinkedList继承自List
B AbstractSet继承自Set
C HashSet继承自AbstractSet
D WeakMap继承自HashMap
答案:AC
解析:下面是一张下载的Java中的集合类型的继承关系图,一目了然。
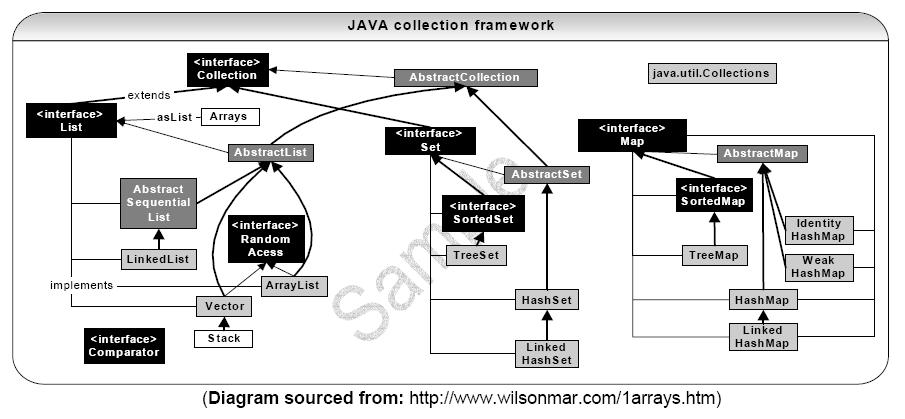
11. 存在使i + 1 < i的数吗()
答案:存在
解析:如果i为int型,那么当i为int能表示的最大整数时,i+1就溢出变成负数了,此时不就<i了吗。
扩展:存在使i > j || i <= j不成立的数吗()
答案:存在
解析:比如Double.NaN或Float.NaN,感谢@BuilderQiu网友指出。
12. 0.6332的数据类型是()
A float B double C Float D Double
答案:B
解析:默认为double型,如果为float型需要加上f显示说明,即0.6332f
13. 下面哪个流类属于面向字符的输入流( )
A BufferedWriter B FileInputStream C ObjectInputStream D InputStreamReader
答案:D
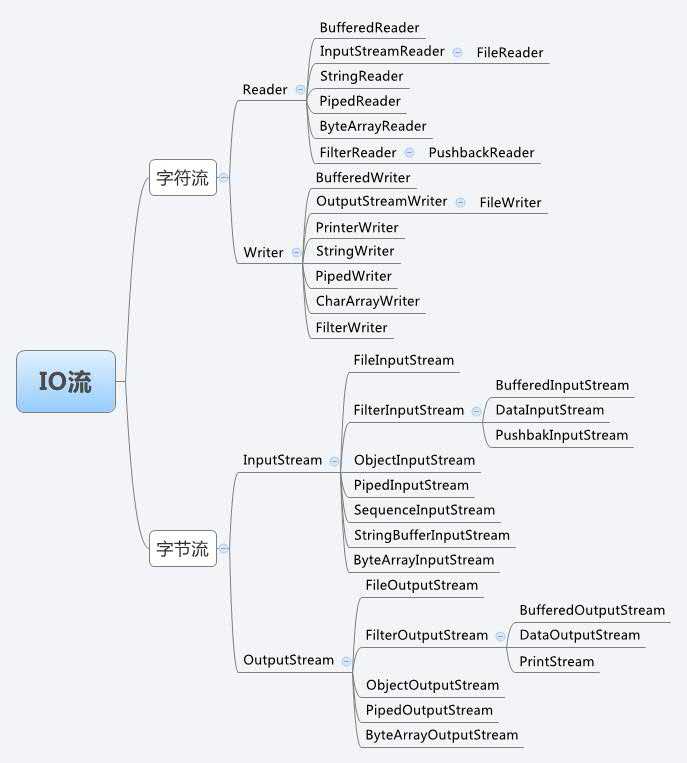
解析:Java的IO操作中有面向字节(Byte)和面向字符(Character)两种方式。
面向字节的操作为以8位为单位对二进制的数据进行操作,对数据不进行转换,这些类都是InputStream和OutputStream的子类。
面向字符的操作为以字符为单位对数据进行操作,在读的时候将二进制数据转为字符,在写的时候将字符转为二进制数据,这些类都是Reader和Writer的子类。
总结:以InputStream(输入)/OutputStream(输出)为后缀的是字节流;
以Reader(输入)/Writer(输出)为后缀的是字符流。
扩展:Java流类图结构,一目了然,解决大部分选择题:
14. Java接口的修饰符可以为()
A private B protected C final D abstract
答案:CD
解析:接口很重要,为了说明情况,这里稍微啰嗦点:
(1)接口用于描述系统对外提供的所有服务,因此接口中的成员常量和方法都必须是公开(public)类型的,确保外部使用者能访问它们;
(2)接口仅仅描述系统能做什么,但不指明如何去做,所以接口中的方法都是抽象(abstract)方法;
(3)接口不涉及和任何具体实例相关的细节,因此接口没有构造方法,不能被实例化,没有实例变量,只有静态(static)变量;
(4)接口的中的变量是所有实现类共有的,既然共有,肯定是不变的东西,因为变化的东西也不能够算共有。所以变量是不可变(final)类型,也就是常量了。
(5) 接口中不可以定义变量?如果接口可以定义变量,但是接口中的方法又都是抽象的,在接口中无法通过行为来修改属性。有的人会说了,没有关系,可以通过 实现接口的对象的行为来修改接口中的属性。这当然没有问题,但是考虑这样的情况。如果接口 A 中有一个public 访问权限的静态变量 a。按照 Java 的语义,我们可以不通过实现接口的对象来访问变量 a,通过 A.a = xxx; 就可以改变接口中的变量 a 的值了。正如抽象类中是可以这样做的,那么实现接口 A 的所有对象也都会自动拥有这一改变后的 a 的值了,也就是说一个地方改变了 a,所有这些对象中 a 的值也都跟着变了。这和抽象类有什么区别呢,怎么体现接口更高的抽象级别呢,怎么体现接口提供的统一的协议呢,那还要接口这种抽象来做什么呢?所以接口中 不能出现变量,如果有变量,就和接口提供的统一的抽象这种思想是抵触的。所以接口中的属性必然是常量,只能读不能改,这样才能为实现接口的对象提供一个统 一的属性。
通俗的讲,你认为是要变化的东西,就放在你自己的实现中,不能放在接口中去,接口只是对一类事物的属性和行为更高层次的抽象。对修改关闭,对扩展(不同的实现 implements)开放,接口是对开闭原则的一种体现。
所以:
接口的方法默认是public abstract;
接口中不可以定义变量即只能定义常量(加上final修饰就会变成常量)。所以接口的属性默认是public static final 常量,且必须赋初值。
注意:final和abstract不能同时出现。
15. 不通过构造函数也能创建对象吗()
A 是 B 否
答案:A
解析:Java创建对象的几种方式(重要):
(1) 用new语句创建对象,这是最常见的创建对象的方法。
(2) 运用反射手段,调用java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
(3) 调用对象的clone()方法。
(4) 运用反序列化手段,调用java.io.ObjectInputStream对象的 readObject()方法。
(1)和(2)都会明确的显式的调用构造函数 ;(3)是在内存上对已有对象的影印,所以不会调用构造函数 ;(4)是从文件中还原类的对象,也不会调用构造函数。
16. ArrayList list = new ArrayList(20);中的list扩充几次()
A 0 B 1 C 2 D 3
答案:A
解析:这里有点迷惑人,大家都知道默认ArrayList的长度是10个,所以如果你要往list里添加20个元素肯定要扩充一次(扩充为原来的1.5倍),但是这里显示指明了需要多少空间,所以就一次性为你分配这么多空间,也就是不需要扩充了。
17. 下面哪些是对称加密算法()
A DES B AES C DSA D RSA
答案:AB
解析:常用的对称加密算法有:DES、3DES、RC2、RC4、AES
常用的非对称加密算法有:RSA、DSA、ECC
使用单向散列函数的加密算法:MD5、SHA
18.新建一个流对象,下面哪个选项的代码是错误的?()
A)new BufferedWriter(new FileWriter("a.txt"));
B)new BufferedReader(new FileInputStream("a.dat"));
C)new GZIPOutputStream(new FileOutputStream("a.zip"));
D)new ObjectInputStream(new FileInputStream("a.dat"));
答案:B
解析:请记得13题的那个图吗?Reader只能用FileReader进行实例化。
19. 下面程序能正常运行吗()
public class NULL {
public static void haha(){
System.out.println("haha");
}
public static void main(String[] args) {
((NULL)null).haha();
}
}
答案:能正常运行
解析:输出为haha,因为null值可以强制转换为任何java类类型,(String)null也是合法的。但null强制转换后是无效对象,其返回值还是为null,而static方法的调用是和类名绑定的,不借助对象进行访问所以能正确输出。反过来,没有static修饰就只能用对象进行访问,使用null调用对象肯定会报空指针错了。这里和C++很类似。这里感谢@Florian网友解答。
20. 下面程序的运行结果是什么()
class HelloA {
public HelloA() {
System.out.println("HelloA");
}
{ System.out.println("I‘m A class"); }
static { System.out.println("static A"); }
}
public class HelloB extends HelloA {
public HelloB() {
System.out.println("HelloB");
}
{ System.out.println("I‘m B class"); }
static { System.out.println("static B"); }
public static void main(String[] args) {
new HelloB();
}
}
答案:
static A static B I‘m A class HelloA I‘m B class HelloB
解析:说实话我觉得这题很好,考查静态语句块、构造语句块(就是只有大括号的那块)以及构造函数的执行顺序。
对象的初始化顺序:(1)类加载之后,按从上到下(从父类到子类)执行被static修饰的语句;(2)当static语句执行完之后,再执行main方法;(3)如果有语句new了自身的对象,将从上到下执行构造代码块、构造器(两者可以说绑定在一起)。
下面稍微修改下上面的代码,以便更清晰的说明情况:
 View Code
View Code此时输出结果为:
static A static B -------main start------- I‘m A class HelloA I‘m B class HelloB I‘m A class HelloA I‘m B class HelloB -------main end-------
21. getCustomerInfo()方法如下,try中可以捕获三种类型的异常,如果在该方法运行中产生了一个IOException,将会输出什么结果()
public void getCustomerInfo() {
try {
// do something that may cause an Exception
} catch (java.io.FileNotFoundException ex) {
System.out.print("FileNotFoundException!");
} catch (java.io.IOException ex) {
System.out.print("IOException!");
} catch (java.lang.Exception ex) {
System.out.print("Exception!");
}
}
A IOException!
BIOException!Exception!
CFileNotFoundException!IOException!
DFileNotFoundException!IOException!Exception!
答案:A
解析:考察多个catch语句块的执行顺序。当用多个catch语句时,catch语句块在次序上有先后之分。从最前面的catch语句块依次先后进行异常类型匹配,这样如果父异常在子异常类之前,那么首先匹配的将是父异常类,子异常类将不会获得匹配的机会,也即子异常类型所在的catch语句块将是不可到达的语句。所以,一般将父类异常类即Exception老大放在catch语句块的最后一个。
22. 下面代码的运行结果为:()
import java.io.*;
import java.util.*;
public class foo{
public static void main (String[] args){
String s;
System.out.println("s=" + s);
}
}
A 代码得到编译,并输出“s=”
B 代码得到编译,并输出“s=null”
C 由于String s没有初始化,代码不能编译通过
D 代码得到编译,但捕获到 NullPointException异常答案:C
解析:开始以为会输出null什么的,运行后才发现Java中所有定义的基本类型或对象都必须初始化才能输出值。
23. System.out.println("5" + 2);的输出结果应该是()。
A 52 B7 C2 D5
答案:A
解析:没啥好说的,Java会自动将2转换为字符串。
24. 指出下列程序运行的结果 ()
public class Example {
String str = new String("good");
char[] ch = { ‘a‘, ‘b‘, ‘c‘ };
public static void main(String args[]) {
Example ex = new Example();
ex.change(ex.str, ex.ch);
System.out.print(ex.str + " and ");
System.out.print(ex.ch);
}
public void change(String str, char ch[]) {
str = "test ok";
ch[0] = ‘g‘;
}
}
A、 good and abc
B、 good and gbc
C、 test ok and abc
D、 test ok and gbc答案:B
解析:大家可能以为Java中String和数组都是对象所以肯定是对象引用,然后就会选D,其实这是个很大的误区:因为在java里没有引用传递,只有值传递
这个值指的是实参的地址的拷贝,得到这个拷贝地址后,你可以通过它修改这个地址的内容(引用不变),因为此时这个内容的地址和原地址是同一地址,
但是你不能改变这个地址本身使其重新引用其它的对象,也就是值传递,可能说的不是很清楚,下面给出一个完整的能说明情况的例子吧:
View Code程序有些啰嗦,但能反映问题,该程序运行结果为:
对象交换前:p1 = Alexia female 对象交换前:p2 = Edward male 对象交换后:p1 = Alexia female 对象交换后:p2 = Edward male 对象数组交换前:arraya[0] = Alexia female, arraya[1] = Edward male 对象数组交换前:arrayb[0] = jmwang female, arrayb[1] = hwu male 对象数组交换后:arraya[0] = Alexia female, arraya[1] = Edward male 对象数组交换后:arrayb[0] = jmwang female, arrayb[1] = hwu male 基本类型数组交换前:a[0] = 0, a[1] = 1 基本类型数组交换前:b[0] = 1, b[1] = 2 基本类型数组交换后:a[0] = 0, a[1] = 1 基本类型数组交换后:b[0] = 1, b[1] = 2 对象数组内容交换并改变后:arraya[1] = wjl male 对象数组内容交换并改变后:arrayb[1] = Edward male 基本类型数组内容交换并改变后:a[1] = 5 基本类型数组内容交换并改变后:b[1] = 1
说明:不管是对象、基本类型还是对象数组、基本类型数组,在函数中都不能改变其实际地址但能改变其中的内容。
A FileInputStream in=new FileInputStream("file.dat"); in.skip(9); int c=in.read();
B FileInputStream in=new FileInputStream("file.dat"); in.skip(10); int c=in.read();
C FileInputStream in=new FileInputStream("file.dat"); int c=in.read();
D RandomAccessFile in=new RandomAccessFile("file.dat"); in.skip(9); int c=in.readByte();
答案:A?D?
解析:long skip(long n)作用是跳过n个字节不读,主要用在包装流中的,因为一般流(如FileInputStream)只能顺序一个一个的读不能跳跃读,但是包装流可以用skip方法跳跃读取。那么什么是包装流呢?各种字节节点流类,它们都只具有读写字节内容的方法,以FileInputStream与FileOutputStream为例,它们只能在文件中读取或者向文件中写入字节,在实际应用中我们往往需要在文件中读取或者写入各种类型的数据,就必须先将其他类型的数据转换成字节数组后写入文件,或者从文件中读取到的字节数组转换成其他数据类型,想想都很麻烦!!因此想通过FileOutputStream将一个浮点小数写入到文件中或将一个整数写入到文件时是非常困难的。这时就需要包装类DataInputStream/DataOutputStream,它提供了往各种输入输出流对象中读入或写入各种类型的数据的方法。
DataInputStream/DataOutputStream并没有对应到任何具体的流设备,一定要给它传递一个对应具体流设备的输入或输出流对象,完成类似 DataInputStream/DataOutputStream功能的类就是一个包装类,也叫过滤流类或处理流类。它对InputOutStream/OutputStream流类进行了包装,使编程人员使用起来更方便。其中DataInputStream包装类的构造函数语法:public DataInputStream(InputStream in)。包装类也可以包装另外一个包装类。
首先BC肯定 是错的,那A正确吗?按上面的解析应该也不对,但我试了下,发现A也是正确的,与网上解析的资料有些出入,下面是我的code:
View Code那么D呢,RandomAccessFile是IO包的类,但是其自成一派,从Object直接继承而来。可以对文件进行读取和写入。支持文件的随机访问,即可以随机读取文件中的某个位置内容,这么说RandomAccessFile肯定可以达到题目的要求,但是选项有些错误,比如RandomAccessFile的初始化是两个参数而非一个参数,采用的跳跃读取方法是skipBytes()而非skip(),即正确的写法是:
RandomAccessFile in = new RandomAccessFile("file.dat", "r");
in.skipBytes(9);
int c = in.readByte();
这样也能读到第十个字节,也就是A和D都能读到第十个字节,那么到底该选哪个呢?A和D有啥不同吗?求大神解答~~~
26. 下列哪种异常是检查型异常,需要在编写程序时声明 ()
ANullPointerException BClassCastException CFileNotFoundException D IndexOutOfBoundsException
答案:C
解析:看第2题的解析。
27. 下面的方法,当输入为2的时候返回值是多少?()
public static int getValue(int i) {
int result = 0;
switch (i) {
case 1:
result = result + i;
case 2:
result = result + i * 2;
case 3:
result = result + i * 3;
}
return result;
}
A0 B2 C4 D10
答案:D
解析:注意这里case后面没有加break,所以从case 2开始一直往下运行。
28. 选项中哪一行代码可以替换题目中//add code here而不产生编译错误?()
public abstract class MyClass {
public int constInt = 5;
//add code here
public void method() {
}
}
Apublic abstract void method(int a);
B constInt = constInt + 5;
C public int method();
D public abstract void anotherMethod() {}
答案:A
解析:考察抽象类的使用。
抽象类遵循的原则:
(1)接口是公开的,里面不能有私有的方法或变量,是用于让别人使用的,而抽象类是可以有私有方法或私有变量的。
(2)abstract class 在 Java 语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface,实现多重继承。接口还有标识(里面没有任何方法,如Remote接口)和数据共享(里面的变量全是常量)的作用。
(3)在abstract class 中可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface中,只能够有静态的不能被修改的数据成员(也就是必须是 static final的,不过在 interface中一般不定义数据成员),所有的成员方法默认都是 public abstract 类型的。
(4)abstract class和interface所反映出的设计理念不同。其实abstract class表示的是"is-a"关系,interface表示的是"has-a"关系。
(5)实现接口的一定要实现接口里定义的所有方法,而实现抽象类可以有选择地重写需要用到的方法,一般的应用里,最顶级的是接口,然后是抽象类实现接口,最后才到具体类实现。抽象类中可以有非抽象方法。接口中则不能有实现方法。
(6)接口中定义的变量默认是public static final 型,且必须给其初值,所以实现类中不能重新定义,也不能改变其值。抽象类中的变量默认是 friendly 型,其值可以在子类中重新定义,也可以在子类中重新赋值。
29. 阅读Shape和Circle两个类的定义。在序列化一个Circle的对象circle到文件时,下面哪个字段会被保存到文件中? ( )
class Shape {
public String name;
}
class Circle extends Shape implements Serializable{
private float radius;
transient int color;
public static String type = "Circle";
}
Aname
B radius
C color
D type
答案:B
解析:这里有详细的解释:http://www.cnblogs.com/lanxuezaipiao/p/3369962.html
30.下面是People和Child类的定义和构造方法,每个构造方法都输出编号。在执行new Child("mike")的时候都有哪些构造方法被顺序调用?请选择输出结果 ( )
class People {
String name;
public People() {
System.out.print(1);
}
public People(String name) {
System.out.print(2);
this.name = name;
}
}
class Child extends People {
People father;
public Child(String name) {
System.out.print(3);
this.name = name;
father = new People(name + ":F");
}
public Child() {
System.out.print(4);
}
}
A312 B 32 C 432 D 132
答案:D
解析:考察的又是父类与子类的构造函数调用次序。在Java中,子类的构造过程中必须调用其父类的构造函数,是因为有继承关系存在时,子类要把父类的内容继承下来。但如果父类有多个构造函数时,该如何选择调用呢?
第一个规则:子类的构造过程中,必须调用其父类的构造方法。一个类,如果我们不写构造方法,那么编译器会帮我们加上一个默认的构造方法(就是没有参数的构造方法),但是如果你自己写了构造方法,那么编译器就不会给你添加了,所以有时候当你new一个子类对象的时候,肯定调用了子类的构造方法,但是如果在子类构造方法中我们并没有显示的调用基类的构造方法,如:super(); 这样就会调用父类没有参数的构造方法。
第二个规则:如果子类的构造方法中既没有显示的调用基类构造方法,而基类中又没有无参的构造方法,则编译出错,所以,通常我们需要显示的:super(参数列表),来调用父类有参数的构造函数,此时无参的构造函数就不会被调用。
总之,一句话:子类没有显示调用父类构造函数,不管子类构造函数是否带参数都默认调用父类无参的构造函数,若父类没有则编译出错。
最后,给大家出个思考题:下面程序的运行结果是什么?
public class Dervied extends Base {
private String name = "dervied";
public Dervied() {
tellName();
printName();
}
public void tellName() {
System.out.println("Dervied tell name: " + name);
}
public void printName() {
System.out.println("Dervied print name: " + name);
}
public static void main(String[] args){
new Dervied();
}
}
class Base {
private String name = "base";
public Base() {
tellName();
printName();
}
public void tellName() {
System.out.println("Base tell name: " + name);
}
public void printName() {
System.out.println("Base print name: " + name);
}
}
标签:
原文地址:http://www.cnblogs.com/doudouxiaoye/p/5811605.html