标签:
下载地址:https://www.elastic.co/downloads
When time comes to deploy a new project, one often overlooked aspect is log management. ELK stack (Elasticsearch, Logstash, Kibana) is, among other things, a powerful and freely available log management solution. In this article I will show you how to install and setup ELK and use it with default log format of a Spring Boot application.
For this guide, I‘ve setup a demo Spring Boot application with logging enabled and with Logstash configuration that will send log entries to Elasticsearch. Demo application is a simple todo list available here.

Application will store logs into a log file. Logstash will read and parse the log file and ship log entries to an Elasticsearch instance. Finally, we will use Kibana 4 (Elasticsearch web frontend) to search and analyze the logs.
bin/elasticsearch or bin/elasticsearch.bat on Windows)curl -XGET http://localhost:9200Here‘s how to do it (steps are written for OS X but should be similar on other systems):
wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.1.zip
unzip elasticsearch-1.7.1.zip
cd elasticsearch-1.7.1
bin/elasticsearch
Elasticsearch should be running now. You can verify it‘s running using curl. In a separate terminal window execute a GET request to Elasticsearch‘s status page:
curl -XGET http://localhost:9200
If all is well, you should get the following result:
{
"status" : 200,
"name" : "Tartarus",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.7.1",
"build_hash" : "b88f43fc40b0bcd7f173a1f9ee2e97816de80b19",
"build_timestamp" : "2015-07-29T09:54:16Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
bin/kibana)Here‘s how to do it:
wget https://download.elastic.co/kibana/kibana/kibana-4.1.1-darwin-x64.tar.gz
tar xvzf kibana-4.1.1-darwin-x64.tar.gz
cd kibana-4.1.1-darwin-x64
bin/kibana
Point your browser to http://localhost:5601 (if Kibana page shows up, we‘re good - we‘ll configure it later)
wget https://download.elastic.co/logstash/logstash/logstash-1.5.3.zip
unzip logstash-1.5.3.zip
In order to have Logstash ship log files to Elasticsearch, we must first configure Spring Boot to store log entries into a file. We will establish the following pipeline: Spring Boot App → Log File → Logstash → Elasticsearch. There are other ways of accomplishing the same thing, such as configuring logback to use TCP appender to send logs to a remote Logstash instance via TCP, and many other configurations. I prefer the file approach because it‘s simple, unobtrusive (you can easily add it to existing systems) and nothing will be lost/broken if for some reason Logstash stops working or if Elasticsearch dies.
Anyhow, let‘s configure Spring Boot‘s log file. The simplest way to do this is to configure log file name in application.properties. It‘s enough to add the following line:
logging.file=application.log
Spring Boot will now log ERROR, WARN and INFO level messages in the application.log log file and will also rotate it as it reaches 10 Mb.
Now comes the tricky part. We need to create Logstash config file. Typical Logstash config file consists of three main sections: input, filter and output. Each section contains plugins that do relevant part of the processing (such as file input plugin that reads log events from a file or elasticsearch output plugin which sends log events to Elasticsearch).

Input section defines from where Logstash will read input data - in our case it will be a file hence we will use a file plugin with multilinecodec, which basically means that our input file may have multiple lines per log entry.
Here‘s the input section:
input {
file {
type => "java"
path => "/path/to/application.log"
codec => multiline {
pattern => "^%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}.*"
negate => "true"
what => "previous"
}
}
}
file plugin.type is set to java - it‘s just additional piece of metadata in case you will use multiple types of log files in the future.path is the absolute path to the log file. It must be absolute - Logstash is picky about this.multiline codec which means that multiple lines may correspond to a single log event,pattern => "^%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}.*" → Each new log event needs to start with date.negate => "true" → if it doesn‘t start with a date ...what => "previous" → ... then it should be grouped with a previous line.File input plugin, as configured, will tail the log file (e.g. only read new entries at the end of the file). Therefore, when testing, in order for Logstash to read something you will need to generate new log entries.
Filter section contains plugins that perform intermediary processing on an a log event. In our case, event will either be a single log line or multiline log event grouped according to the rules described above. In the filter section we will do several things:
Filter section for Spring Boot‘s log format that aforementioned things looks like this:
filter {
#If log line contains tab character followed by ‘at‘ then we will tag that entry as stacktrace
if [message] =~ "\tat" {
grok {
match => ["message", "^(\tat)"]
add_tag => ["stacktrace"]
}
}
#Grokking Spring Boot‘s default log format
grok {
match => [ "message",
"(?<timestamp>%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}) %{LOGLEVEL:level} %{NUMBER:pid} --- \[(?<thread>[A-Za-z0-9-]+)\] [A-Za-z0-9.]*\.(?<class>[A-Za-z0-9#_]+)\s*:\s+(?<logmessage>.*)",
"message",
"(?<timestamp>%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}) %{LOGLEVEL:level} %{NUMBER:pid} --- .+? :\s+(?<logmessage>.*)"
]
}
#Parsing out timestamps which are in timestamp field thanks to previous grok section
date {
match => [ "timestamp" , "yyyy-MM-dd HH:mm:ss.SSS" ]
}
}
Explanation:
if [message] =~ "\tat" → If message contains tab character followed by at (this is ruby syntax) then...grok plugin to tag stacktraces:
match => ["message", "^(\tat)"] → when message matches beginning of the line followed by tab followed by at then...add_tag => ["stacktrace"] → ... tag the event with stacktrace tag.grok plugin for regular Spring Boot log message parsing:
date plugin to parse and set the event date:
match => [ "timestamp" , "yyyy-MM-dd HH:mm:ss.SSS" ] → timestamp field (grokked earlier) contains the timestamp in the specified formatOutput section contains output plugins that send event data to a particular destination. Outputs are the final stage in the event pipeline. We will be sending our log events to stdout (console output, for debugging) and to Elasticsearch.
Compared to filter section, output section is rather straightforward:
output {
# Print each event to stdout, useful for debugging. Should be commented out in production.
# Enabling ‘rubydebug‘ codec on the stdout output will make logstash
# pretty-print the entire event as something similar to a JSON representation.
stdout {
codec => rubydebug
}
# Sending properly parsed log events to elasticsearch
elasticsearch {
host => "127.0.0.1"
}
}
Explanation:
stdout and elasticsearch.stdout { ... } → stdout plugin prints log events to standard output (console).
codec => rubydebug → Pretty print events using JSON-like formatelasticsearch { ... } → elasticsearch plugin sends log events to Elasticsearch server.
host => "127.0.0.1" → Hostname where Elasticsearch is located - in our case, localhost.Update 5/9/2016: At the time of writing this update, the latest versions of Logstash‘s elasticsearch output plugin uses
hostsconfiguration parameter instead ofhostwhich is shown in example above. New parameter takes an array of hosts (e.g. elasticsearch cluster) as value. In other words, if you are using the latest Logstash version, configure elasticsearch output plugin as follows:elasticsearch { hosts => ["127.0.0.1"] }
Finally, the three parts - input, filter and output - need to be copy pasted together and saved into logstash.conf config file. Once the config file is in place and Elasticsearch is running, we can run Logstash:
/path/to/logstash/bin/logstash -f logstash.conf
If everything went well, Logstash is now shipping log events to Elasticsearch.
Ok, now it‘s time to visit the Kibana web UI again. We have started it in step 2 and it should be running at http://localhost:5601.
First, you need to point Kibana to Elasticsearch index(s) of your choice. Logstash creates indices with the name pattern of logstash-YYYY.MM.DD. In Kibana Settings → Indices configure the indices:
Now click on "Discover" tab. In my opinion, "Discover" tab is really named incorrectly in Kibana - it should be labeled as "Search" instead of "Discover" because it allows you to perform new searches and also to save/manage them. Log events should be showing up now in the main window. If they‘re not, then double check the time period filter in to right corner of the screen. Default table will have 2 columns by default: Time and _source. In order to make the listing more useful, we can configure the displayed columns. From the menu on the left select level, class and logmessage.
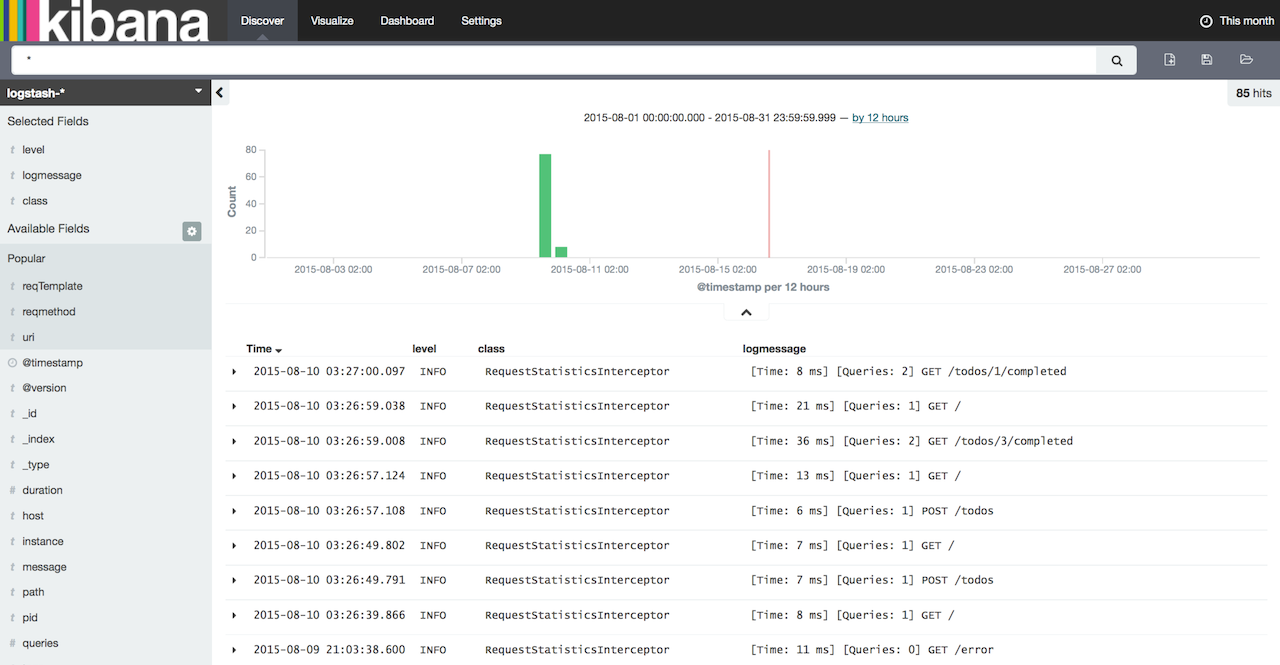
Alright! You‘re now ready to take control of your logs using ELK stack and start customizing and tweaking your log management configuration. You can download the sample application used when writing this article from here: https://github.com/knes1/todo. It‘s already configured to write logs in a file and has the Logstash config as described above (although absolute paths will need to be tweaked in logstash.conf).
If you would like to search or follow your EL logs from command line, checkout Elktail - a command line utility I‘ve created for accessing and tailng logs stored in EL.
As always, let me know if you have any question/comments or ideas in the comments section below.
http://knes1.github.io/blog/2015/2015-08-16-manage-spring-boot-logs-with-elasticsearch-kibana-and-logstash.html

最近由于之前协助前公司做了点力所能及的事情,居然收到了一份贵重的端午礼物,是给我女儿的一个乐高积木,整个有7大包物件,我花了接近一天的时间一砖一瓦的组织起来,虽然很辛苦但是能够从过程中体验到乐趣。这次将分享从头搭建分布式日志系统,主要是在spring mvc上结合ELK套件实现(之前有些工作由于分工不同由不同的同事来完成,我只是在已经配置好的环境下做开发而已),包含如下这些技术点:
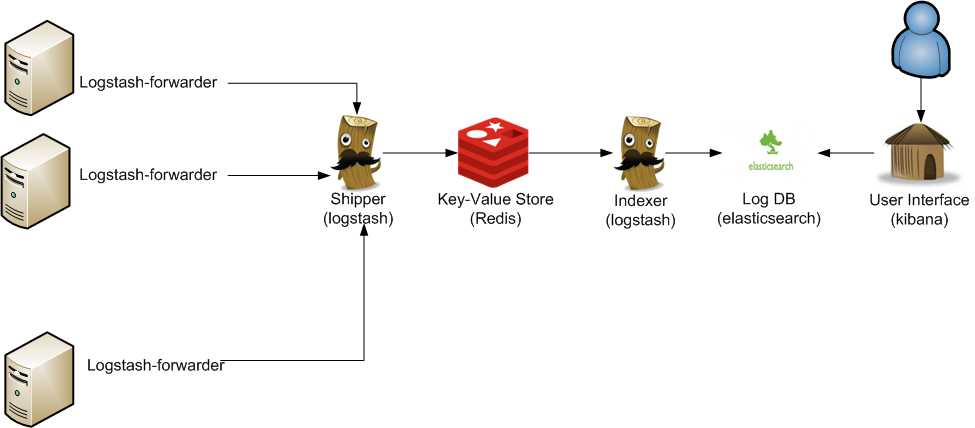
来看下整体的架构图,这类架构非常容易解决当下分布式系统下的日志记录,查询以及分析困难的问题。
操作系统,IDE环境:
1:搭建spring mvc项目
eclipse自带创建的dynamic web project是个空结构,没有任何配置,我们要想跑起来一个hello world的项目,还需要做些配置,比如创建程序文件,比如view,controller等等。
spring tool suite可以帮助我们解决这个问题,它提供了spring mvc的项目模板,里面自带一个hello world的可启动的应用页面,在eclipse中可以很方便的以插件形式安装spring tool suit,安装好之后就可以创建了。
这里需要注意的是不同版本的spring tool suite在创建时的菜单会有不同,我目前的菜单位于:
首先要选中spring标签:
然后在File菜单下找:
创建好之后,我们就可以直接在tomcat下运行了,不需要任何的其它操作,相对创建的dynamic web project要方便的多,不过通过这种模板创建的项目也有缺点:如果你喜欢新的一些依赖包,那么你需要手工去pom文件中去更新版本号为你想要的,还有可能会引入部分你暂时可能用不上的一些第三方包。下图是稍加修改的项目完成图,是一个标准的maven结构的spring mvc。

2:redis安装
由于我的是windows环境,所以相应的需要下载windows版本的redis:
windows版:https://github.com/mythz/redis-windows
下载下来解压,然后选择一个版本:
配置文件我只修改了一个:bind,它是用来绑定一个固定IP的,为什么要显示的去绑定一个IP呢?后面会介绍我遇到的问题。
启动服务端:在redis/bin目录下执行:redis-server.exe redis.windows.conf即可启动
启动客户端:在redis/bin目录下执行:redis-cli.exe -h 127.0.0.1 -p 6379,在这个窗口可以通过一些redis命令再测试redis是否正常,比如get,set ,keys *等等。
3:ELK安装
在这个网站可以找到ELK最新版本:https://www.elastic.co/downloads,将elasticsearch,logstash,kibana这三个全部下载下来。
大部分的配置都使用默认的,只是为了好标识我修改了cluster.name以及node.name,详细的参数可研究文档。然后直接在bin目录下运行elasticsearch.bat就可以启动了。
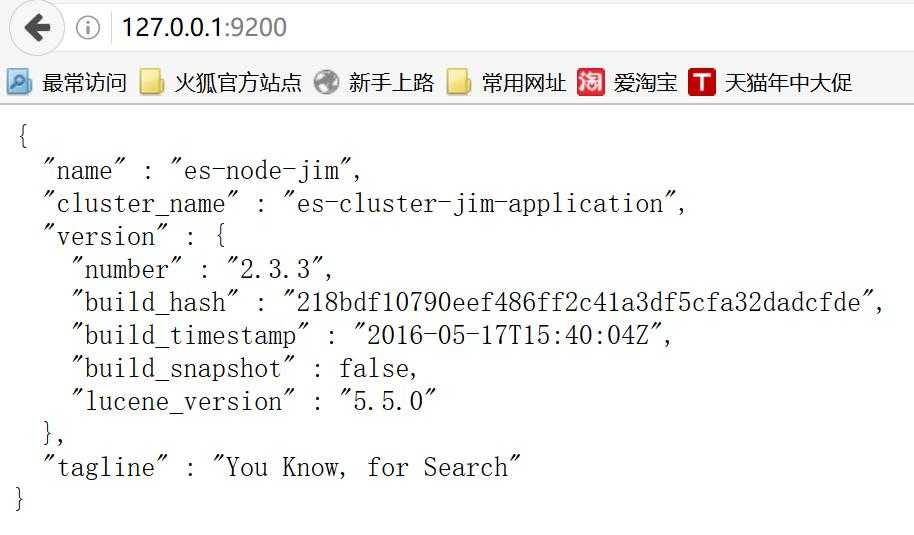
打开http://127.0.0.1:9200/就可以,看到如下信息就说明启动正常了。
还有很多插件可以安装,用来帮助我们查看监控elasticsearch,这里先安装head,命令行进入elasticsearch的目录,然后执行plugin install mobz/elasticsearch-head即可安装。
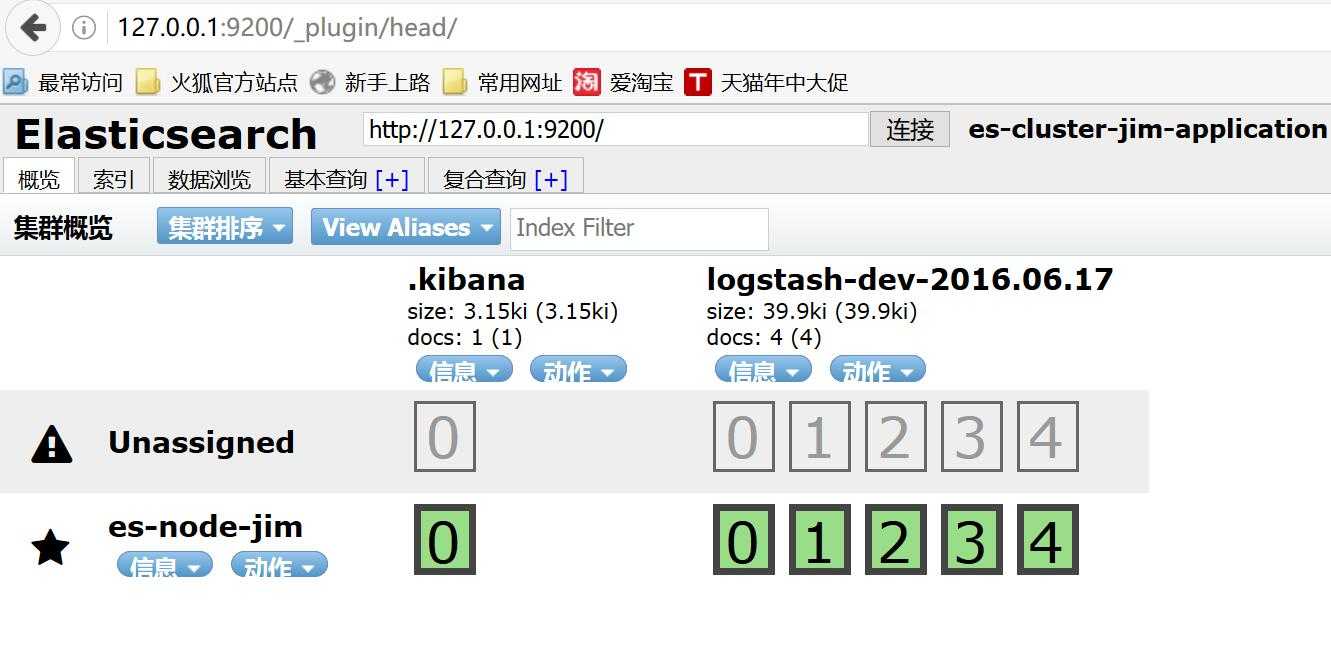
安装成功后打开http://127.0.0.1:9200/_plugin/head/
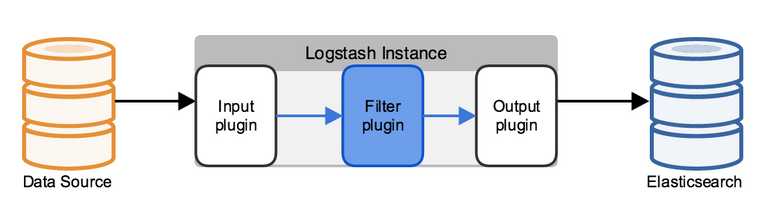
先看下logstash的架构设计以及与其它ELK的配合,本篇的data source就是redis,不涉及到filter,最终日志输出到elasticsearch中。
这里我们只配置input以及output,需要注意的是不同版本的logstash在配置上也会略有不同,大家有兴趣可以进一步做下对比。

input {
redis {
data_type => "list"
key => "logstash"
host => "127.0.0.1"
port => 6379
threads => 5
codec => "json"
}
}
filter {
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "logstash-%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
workers => 1
flush_size => 20
idle_flush_time => 1
template_overwrite => true
}
stdout{}
}
然后在logstash目录下执行logstash -f etc/logstash.d/即可启动

需要有一个记录日志的入口,将logback-classic引入进来,为了将日志传递给redis,需要配置一个logback-redis-appender,依赖如下:
<!-- Logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${org.slf4j-version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
<!--logstash begin -->
<dependency>
<groupId>com.cwbase</groupId>
<artifactId>logback-redis-appender</artifactId>
<version>1.1.3</version>
<exclusions>
<exclusion>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</exclusion>
</exclusions>
</dependency>
配置logback.xml,key需要与logstash配置文件中配置的key相匹配。
<appender name="LOGSTASH" class="com.cwbase.logback.RedisAppender">
<source>logstashdemo</source>
<type>dev</type>
<host>127.0.0.1</host>
<key>logstash</key>
<tags>dev</tags>
<mdc>true</mdc>
<location>true</location>
<callerStackIndex>0</callerStackIndex>
</appender>
在homecontroller中记录日志,slf4j由于完成了与logback完美集成,所以我们也不需要做任何转换类的配置即可实现日志记录。
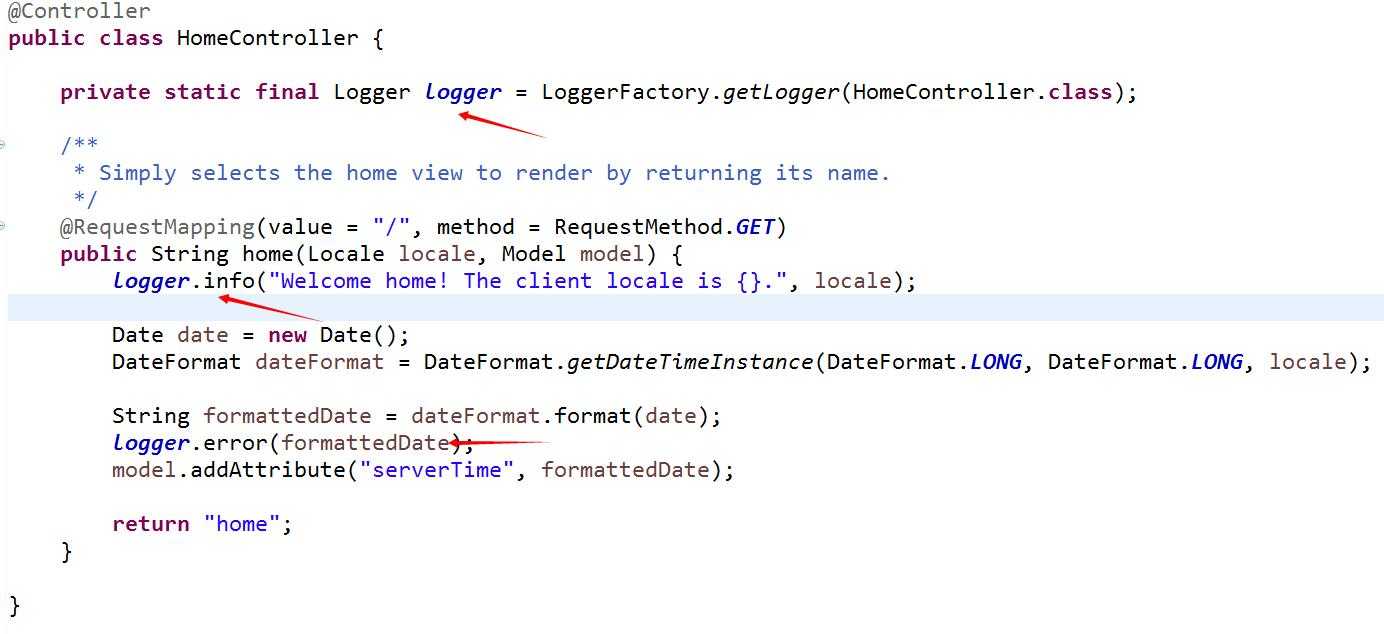
前文中曾经提到在配置redis时,设置了bind属性,让其指定到一个固定的IP。如果不指定,在logstash连接redis会有问题,其中的原因有待后续进一步确认。
4:运行网站,查看日志
当redis,elasticsearch,logstash服务运行正常后,启动spring mvc,通过logger记录的日志就可以在kibana中方便的查看了。
测试logback是否已经将日志发送到redis,可以通过redis的命令来查看是否包含了配置的logstash这个key,还可以通过llen来判断日志是否在正常的递增。
![]()
如果上面都正常,再找开kibana的页面,第一次打开会提示创建索引规则,创建好之后就可以看到日志已经被采集到elasticsearch中了。
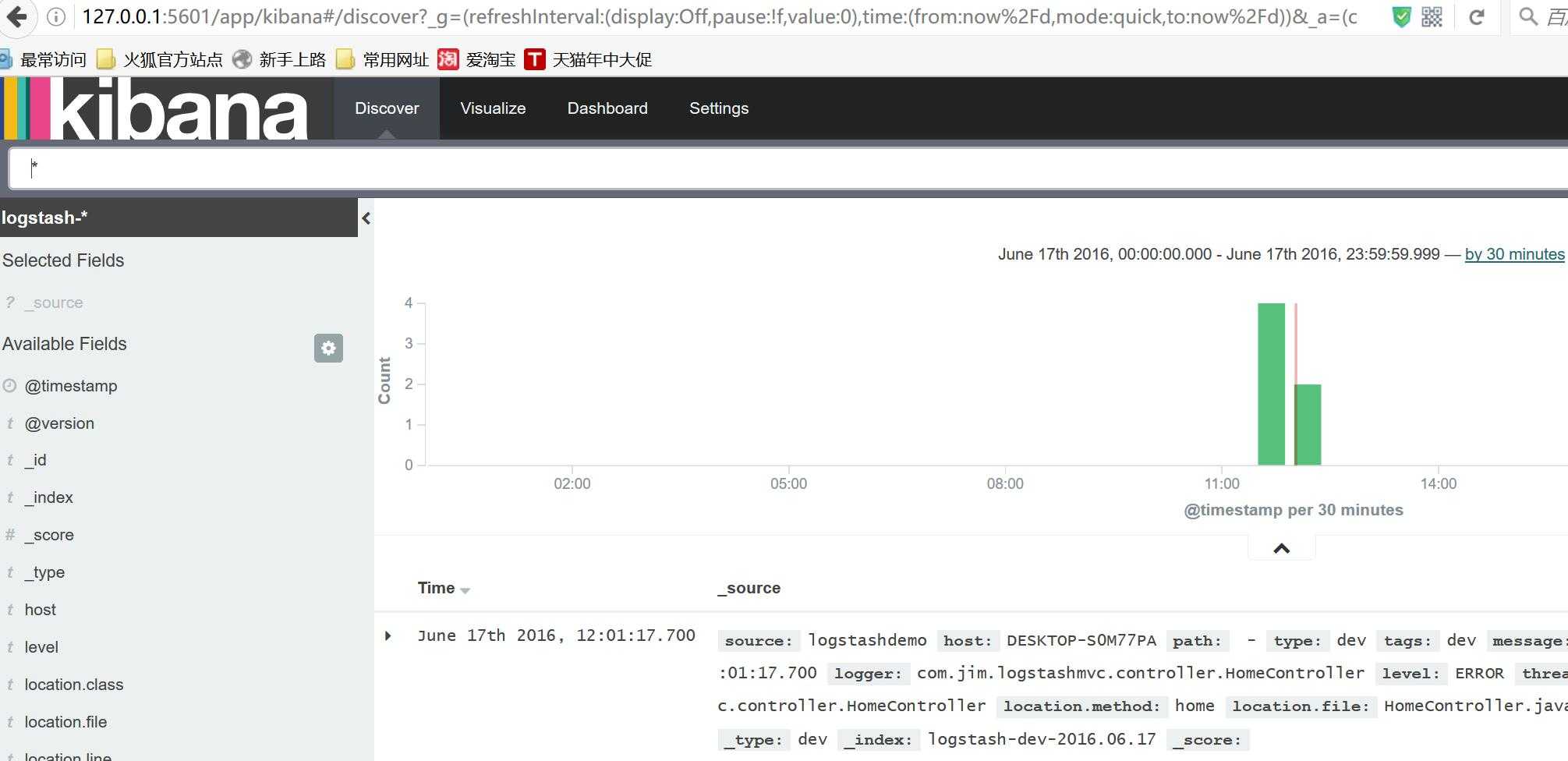
经过接近两天的研究,终于从0开始搭建成功了spring mvc+ELK的分布式日志管理平台,java平台的优势就是开源的产品多,可利用优秀插件也多,擅于去发倔还是可以很省事的做些比较优秀的项目的。虽然本篇只是一个练手入门文章,但有了开始就会有收获。

本文参考:
http://www.cnblogs.com/ASPNET2008/p/5594479.html
http://www.oschina.net/translate/elasticsearch-getting-started
Manage Spring Boot Logs with Elasticsearch, Logstash and Kibana
标签:
原文地址:http://www.cnblogs.com/softidea/p/5813797.html