标签:
下午仿照网上例子写了个抓取网页中图片并保存到本地的Python的例子,好奇就google了下是否有类似的在线抓取图片的外挂工具。
接着就找到了
Image Cyborg是一项提供网页图片批次下载、备份的免费线上工具,它能将你输入的网址内所有图片批次下载、撷取并打包成压缩档。隐私是它最大特色,网站不会记录追踪使用者下载的资料。Image Cyborg支援data URI Scheme格式图片(以一段Base64编码来处理图片,减少频宽、增加网站载入效率技术),以及延迟载入、动态产生的图片,一般外挂无法做到。
这项服务支援的图片格式 ??包括:.bmp, .eps, .gif, .jpeg, .jpg, .icns, .im, .mps, .pcx, .png, .ppm, .spider, .tiff, .webp , .xbm, .svg,只要输入要下载图片的原始网址,它就会自动抓取该网页内的所有图片、打包成压缩档让使用者下载。
网站名称:Image Cyborg
网站链接:https://imagecyborg.com/
使用步骤
Step 1
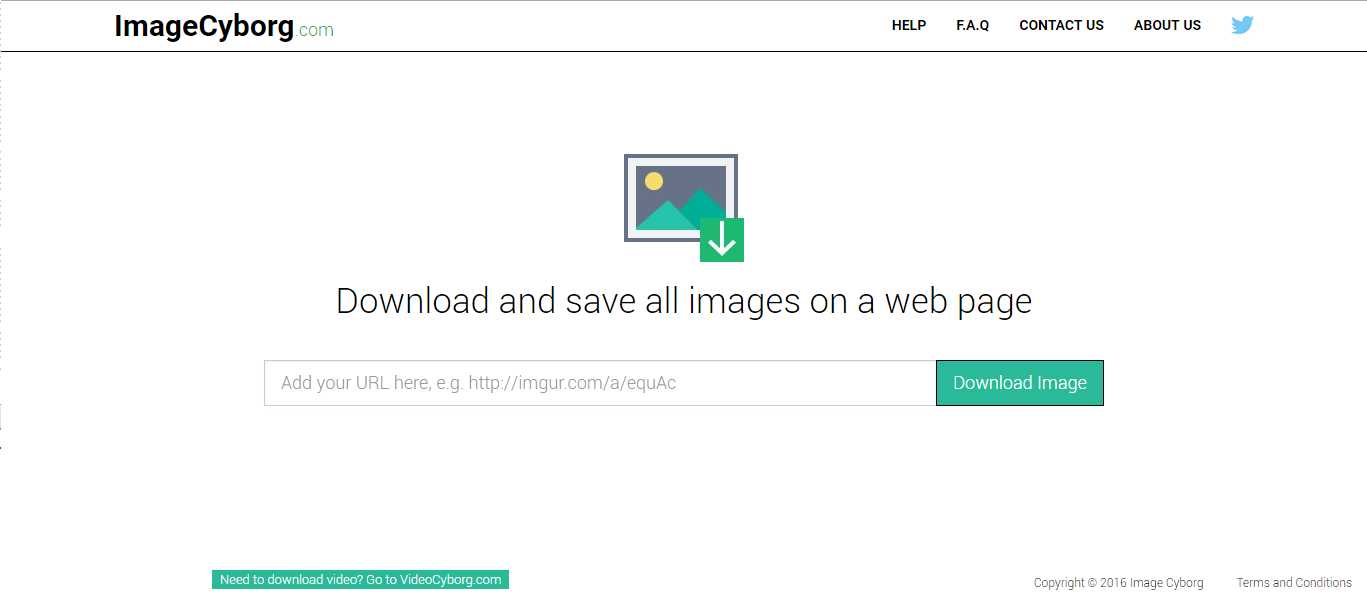
Step 2
处理时需要一段时间,Image Cyborg 网站会显示目前进度,我测试几次后发现速度还蛮快的,下载10 张图片的单一网页几乎不用30 秒的处理时间。

Step 3
处理完成后,Image Cyborg 会跳出档案下载的提示,即将下载一个名为[imagecyborg.com].zip的压缩包。

将下载的压缩档解压缩后,就能取得该网页里的所有图片原始档。不仅如此,它还会自动修改图片档名,在最前面加上来源网址及一个随机字串。
————————————————————————————————————————————————————
依照以上三步,我找了个链接http://www.topit.me/album/1800867/item/64746180测试下载:
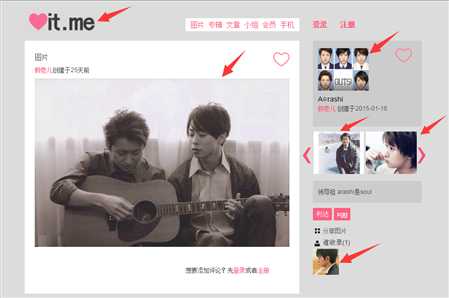
其中原网页如下图有图中红色箭头标注的6处图片:
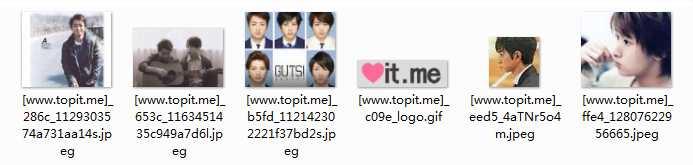
得到的[imagecyborg.com].zip压缩包解压后,依次得到了如下6张图:
总结:
image-cyborg是个很棒的在线抓取网页图片的工具。
标签:
原文地址:http://www.cnblogs.com/xixihuang/p/5810571.html