标签:
char * strcpy(char * dest, const char * src) // 实现src到dest的复制 { if ((src == NULL) || (dest == NULL)) //判断参数src和dest的有效性 { return NULL; } char *strdest = dest; //保存目标字符串的首地址 while ((*strDest++ = *strSrc++)!=‘\0‘); //把src字符串的内容复制到dest下 return strdest; }
memcpy的原型是:void *memcpy( void *dest, const void *src, size_t count );
void *memcpy(void *memTo, const void *memFrom, size_t size) { if((memTo == NULL) || (memFrom == NULL)) //memTo和memFrom必须有效 return NULL; char *tempFrom = (char *)memFrom; //保存memFrom首地址 char *tempTo = (char *)memTo; //保存memTo首地址 while(size -- > 0) //循环size次,复制memFrom的值到memTo中 *tempTo++ = *tempFrom++ ; return memTo; }
strcpy和memcpy主要有以下3方面的区别。
1、复制的内容不同。strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。
2、复制的方法不同。strcpy不需要指定长度,它遇到被复制字符的串结束符"\0"才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。
3、用途不同。通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy
extern char *strtok( char *s, const char *delim );
功能:分解字符串为一组标记串。s为要分解的字符串,delim为分隔符字符串。
说明:strtok()用来将字符串分割成一个个片段。当strtok()在参数s的字符串中发现到参数delim的分割字符时则会将该字符改为 \0 字符。在第一次调用时,strtok()必需给予参数s字符串,往后的调用则将参数s设置成NULL。每次调用成功则返回被分割出片段的指针。当没有被分割的串时则返回NULL。所有delim中包含的字符都会被滤掉,并将被滤掉的地方设为一处分割的节点。
char * strstr( const char * str1, const char * str2 );
功能:从字符串 str1 中寻找 str2 第一次出现的位置(不比较结束符NULL),如果没找到则返回NULL。
char * strchr ( const char *str, int ch );
功能:查找字符串 str 中首次出现字符 ch 的位置
说明:返回首次出现 ch 的位置的指针,如果 str 中不存在 ch 则返回NULL。
char * strcpy( char * dest, const char * src );
功能:把 src 所指由NULL结束的字符串复制到 dest 所指的数组中。
说明:src 和 dest 所指内存区域不可以重叠且 dest 必须有足够的空间来容纳 src 的字符串。返回指向 dest 结尾处字符(NULL)的指针。
类似的:
strncpy
char * strncpy( char * dest, const char * src, size_t num );
char * strcat ( char * dest, const char * src );
功能:把 src 所指字符串添加到 dest 结尾处(覆盖dest结尾处的‘\0‘)并添加‘\0‘。
说明:src 和 dest 所指内存区域不可以重叠且 dest 必须有足够的空间来容纳 src 的字符串。
返回指向 dest 的指针。
类似的 strncat
char * strncat ( char * dest, const char * src, size_t num );
int strcmp ( const char * str1, const char * str2 );
功能:比较字符串 str1 和 str2。
说明:
当s1<s2时,返回值<0
当s1=s2时,返回值=0
当s1>s2时,返回值>0
类似的:
strncmp
int strncmp ( const char * str1, const char * str2, size_t num );
size_t strlen ( const char * str );
功能:计算字符串 str 的长度
说明:返回 str 的长度,不包括结束符NULL。(注意与 sizeof 的区别)
类似的 strnlen:它从内存的某个位置(可以是字符串开头,中间某个位置,甚至是某个不确定的内存区域)开始扫描,直到碰到第一个字符串结束符‘\0‘或计数器到达以下的maxlen为止,然后返回计数器值。
size_t strnlen(const char *str, size_t maxlen);
二、mem 系列
1.memset
void * memset ( void * ptr, int value, size_t num );
功能:把 ptr 所指内存区域的前 num 个字节设置成字符 value。
说明:返回指向 ptr 的指针。可用于变量初始化等操作
举例:

#include <stdio.h>
#include <string.h>
int main ()
{
char str[] = "almost erery programer should know memset!";
memset(str, ‘-‘, sizeof(str));
printf("the str is: %s now\n", str);
return 0;
}
2.memmove
void * memmove ( void * dest, const void * src, size_t num );
功能:由 src 所指内存区域复制 num 个字节到 dest 所指内存区域。
说明:src 和 dest 所指内存区域可以重叠,但复制后 src 内容会被更改。函数返回指向dest的指针。
举例:
#include <stdio.h>
#include <string.h>
int main ()
{
char str[] = "memmove can be very useful......";
memmove(str + 20, str + 15, 11);
printf("the str is: %s\n", str);
return 0;
}
the str is: memmove can be very very useful.
3.memcpy
void * memcpy ( void * destination, const void * source, size_t num );
类似 strncpy。区别:拷贝指定大小的内存数据,而不管内容(不限于字符串)。
memcpy和memmove作用是一样的,唯一的区别是,当内存发生局部重叠的时候,memmove保证拷贝的结果是正确的,memcpy不保证拷贝的结果的正确。(memcpy更快)
但当源内存和目标内存存在重叠时,memcpy会出现错误,而memmove能正确地实施拷贝,但这也增加了一点点开销。
memmove的处理措施:
(1)当源内存的首地址等于目标内存的首地址时,不进行任何拷贝
(2)当源内存的首地址大于目标内存的首地址时,实行正向拷贝
(3)当源内存的首地址小于目标内存的首地址时,实行反向拷贝
4.memcmp
int memcmp ( const void * ptr1, const void * ptr2, size_t num );
类似 strncmp
5.memchr
void * memchr ( const void *buf, int ch, size_t count);
功能:从 buf 所指内存区域的前 count 个字节查找字符 ch。
说明:当第一次遇到字符 ch 时停止查找。如果成功,返回指向字符 ch 的指针;否则返回NULL。
类的析构函数为什么设计成虚函数?
析构函数的作用与构造函数正好相反,是在对象的生命期结束时,释放系统为对象所分配的空间,即要撤消一个对象。
用对象指针来调用一个函数,有以下两种情况:
如果是虚函数,会调用派生类中的版本。(在有派生类的情况下)
如果是非虚函数,会调用指针所指类型的实现版本。
析构函数也会遵循以上两种情况,因为析构函数也是函数嘛,不要把它看得太特殊。 当对象出了作用域或是我们删除对象指针,析构函数就会被调用。
当派生类对象出了作用域,派生类的析构函数会先调用,然后再调用它父类的析构函数, 这样能保证分配给对象的内存得到正确释放。
但是,如果我们删除一个指向派生类对象的基类指针,而基类析构函数又是非虚的话, 那么就会先调用基类的析构函数(上面第2种情况),派生类的析构函数得不到调用。
补充构造函数为什么不能是虚函数:
1. 从存储空间角度,虚函数对应一个指向vtable虚函数表的指针,这大家都知道,可是这个指向vtable的指针其实是存储在对象的内存空间的。问题出来了,如果构造函数是虚的,就需要通过 vtable来调用,可是对象还没有实例化,也就是内存空间还没有,怎么找vtable呢?所以构造函数不能是虚函数。 2. 从使用角度,虚函数主要用于在信息不全的情况下,能使重载的函数得到对应的调用。构造函数本身就是要初始化实例,那使用虚函数也没有实际意义呀。所以构造函数没有必要是虚函数。虚函数的作用在于通过父类的指针或者引用来调用它的时候能够变成调用子类的那个成员函数。而构造函数是在创建对象时自动调用的,不可能通过父类的指针或者引用去调用,因此也就规定构造函数不能是虚函数。 3. 构造函数不需要是虚函数,也不允许是虚函数,因为创建一个对象时我们总是要明确指定对象的类型,尽管我们可能通过实验室的基类的指针或引用去访问它但析构却不一定,我们往往通过基类的指针来销毁对象。这时候如果析构函数不是虚函数,就不能正确识别对象类型从而不能正确调用析构函数。 4. 从实现上看,vbtl在构造函数调用后才建立,因而构造函数不可能成为虚函数从实际含义上看,在调用构造函数时还不能确定对象的真实类型(因为子类会调父类的构造函数);而且构造函数的作用是提供初始化,在对象生命期只执行一次,不是对象的动态行为,也没有必要成为虚函数。 5. 当一个构造函数被调用时,它做的首要的事情之一是初始化它的VPTR。因此,它只能知道它是“当前”类的,而完全忽视这个对象后面是否还有继承者。当编译器为这个构造函数产生代码时,它是为这个类的构造函数产生代码——既不是为基类,也不是为它的派生类(因为类不知道谁继承它)。所以它使用的VPTR必须是对于这个类的VTABLE。而且,只要它是最后的构造函数调用,那么在这个对象的生命期内,VPTR将保持被初始化为指向这个VTABLE, 但如果接着还有一个更晚派生的构造函数被调用,这个构造函数又将设置VPTR指向它的 VTABLE,等.直到最后的构造函数结束。VPTR的状态是由被最后调用的构造函数确定的。这就是为什么构造函数调用是从基类到更加派生类顺序的另一个理由。但是,当这一系列构造函数调用正发生时,每个构造函数都已经设置VPTR指向它自己的VTABLE。如果函数调用使用虚机制,它将只产生通过它自己的VTABLE的调用,而不是最后的VTABLE(所有构造函数被调用后才会有最后的VTABLE)。
说两种进程间通信的方式。
1. 管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。 2. 命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。 3. 内存映射MemoryMapping 4. 消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。 5. 共享存储SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。 6. 信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。 7. 套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
8. 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
问了一些调试的问题,VS为什么能进行断点单步调式,原理是啥?(腾讯实习生面试也问过这个问题,软中断)
要在被调试进程中的某个目标地址上设定一个断点,调试器需要做下面两件事情:
1. 保存目标地址上的数据
2. 将目标地址上的第一个字节替换为int 3指令
然后,当调试器向操作系统请求开始运行进程时(通过前一篇文章中提到的PTRACE_CONT),进程最终一定会碰到int 3指令。此时进程停止,操作系统将发送一个信号。这时就是调试器再次出马的时候了,接收到一个其子进程(或被跟踪进程)停止的信号,然后调试器要做下面几 件事:
1. 在目标地址上用原来的指令替换掉int 3
2. 将被跟踪进程中的指令指针向后递减1。这么做是必须的,因为现在指令指针指向的是已经执行过的int 3之后的下一条指令。
3. 由于进程此时仍然是停止的,用户可以同被调试进程进行某种形式的交互。这里调试器可以让你查看变量的值,检查调用栈等等。
4. 当用户希望进程继续运行时,调试器负责将断点再次加到目标地址上(由于在第一步中断点已经被移除了),除非用户希望取消断点。
template <class T> class auto_ptr { T* ptr; public: explicit auto_ptr(T* p = 0) : ptr(p) {} ~auto_ptr() {delete ptr;} T& operator*() {return *ptr;} T* operator->() {return ptr;} // ... };
从上面auto_ptr可以看出来,智能指针将基本类型指针封装为类对象指针(这个类肯定是个模板,以适应不同基本类型的需求),并在析构函数里编写delete语句删除指针指向的内存空间。
templet<class T>
class auto_ptr {
explicit auto_ptr(X* p = 0) ;
...
};
因此不能自动将指针转换为智能指针对象,必须显式调用:
shared_ptr<double> pd;
double *p_reg = new double;
pd = p_reg; // not allowed (implicit conversion)
pd = shared_ptr<double>(p_reg); // allowed (explicit conversion)
shared_ptr<double> pshared = p_reg; // not allowed (implicit conversion)
shared_ptr<double> pshared(p_reg); // allowed (explicit conversion)
string vacation("I wandered lonely as a cloud.");
shared_ptr<string> pvac(&vacation); // No
pvac过期时,程序将把delete运算符用于非堆内存,这是错误的。
四种智能指针:
STL一共给我们提供了四种智能指针:auto_ptr、unique_ptr、shared_ptr和weak_ptr(本文章暂不讨论)。
模板auto_ptr是C++98提供的解决方案,C+11已将将其摒弃,并提供了另外两种解决方案。然而,虽然auto_ptr被摒弃,但它已使用了好多年:同时,如果您的编译器不支持其他两种解决力案,auto_ptr将是唯一的选择。
先来看下面的赋值语句:
auto_ptr< string> ps (new string ("I reigned lonely as a cloud.”);
auto_ptr<string> vocation;
vocaticn = ps;
上述赋值语句将完成什么工作呢?如果ps和vocation是常规指针,则两个指针将指向同一个string对象。这是不能接受的,因为程序将试图删除同一个对象两次——一次是ps过期时,另一次是vocation过期时。要避免这种问题,方法有多种:
四种智能指针:
| 列1 | 列2 |
| auto_ptr | 内部使用一个成员变量,指向一块内存资源(构造函数), 并在析构函数中释放内存资源。(未实现深复制,因此拷贝一个auto_ptr将会有删除两次一个内存的潜在问题) |
| unique_ptr | 独享所有权的智能指针: 1、拥有它指向的对象 2、无法进行复制构造,无法进行复制赋值操作。即无法使两个unique_ptr指向同一个对象。但是可以进行移动构造和移动赋值操作(所有权转让) 3、保存指向某个对象的指针,当它本身被删除释放的时候,会使用给定的删除器释放它指向的对象 |
| shared_ptr | 使用计数机制来表明资源被几个指针共享。可以通过成员函数use_count()来查看资源的所有者个数。 拷贝构造时候,计数器会加一。当我们调用release()时,当前指针会释放资源所有权,计数减一。当计数等于0时,资源会被释放 会有死锁问题,引入weak_ptr:,如果说两个shared_ptr相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。 |
| weak_ptr | 构造和析构不会引起引用记数的增加或减少。协助shared_ptr,没有重载*和->但可以使用lock获得一个可用的shared_ptr对象 |
Visual C++内置内存泄露检测工具,但是功能十分有限。VLD就相当强大,可以定位文件、行号,可以非常准确地找到内存泄漏的位置,而且还免费、开源!
在使用的时候只要将VLD的头文件和lib文件放在工程文件中即可。
也可以一次设置,新工程就不用重新设置了。只介绍在Visual Studio 2003/2005中的设置方法,VC++ 6.0类似:
#include “vld.h”
顺序无所谓,但是一定不能在一些预编译的文件前(如stdafx.h)。我是加在stdafx.h文件最后。
---------- Block 2715024 at 0x04D8A368: 512 bytes ----------
Call Stack:
d:\kangzj\documents\visual studio 2005\projects\rsip.root\readtiff\readtiff\segmentflag.cpp (56): CSegmentFlag::GetFlagFromArray
d:\kangzj\documents\visual studio 2005\projects\rsip.root\readtiff\readtiff\wholeclassdlg.cpp (495): segmentThreadProc
f:\dd\vctools\vc7libs\ship\atlmfc\src\mfc\thrdcore.cpp (109): _AfxThreadEntry
f:\dd\vctools\crt_bld\self_x86\crt\src\threadex.c (348): _callthreadstartex
f:\dd\vctools\crt_bld\self_x86\crt\src\threadex.c (331): _threadstartex
0x7C80B729 (File and line number not available): GetModuleFileNameA
template <class RandomAccessIterator> inline void sort(RandomAccessIterator first, RandomAccessIterator last) { if (first != last) { __introsort_loop(first, last, value_type(first), __lg(last - first) * 2); __final_insertion_sort(first, last); } }
它是一个模板函数,只接受随机访问迭代器。if语句先判断区间有效性,接着调用__introsort_loop,它就是STL的Introspective Sort实现。在该函数结束之后,最后调用插入排序。我们来揭开该算法的面纱:
template <class RandomAccessIterator, class T, class Size> void __introsort_loop(RandomAccessIterator first, RandomAccessIterator last, T*, Size depth_limit) { while (last - first > __stl_threshold) { if (depth_limit == 0) { partial_sort(first, last, last); return; } --depth_limit; RandomAccessIterator cut = __unguarded_partition (first, last, T(__median(*first, *(first + (last - first)/2), *(last - 1)))); __introsort_loop(cut, last, value_type(first), depth_limit); last = cut; } }
我们来比较一下两者的区别,试想,如果一个序列只需要递归两次便可结束,即它可以分成四个子序列。原始的方式需要两个递归函数调用,接着两者各自调 用一次,也就是说进行了7次函数调用,如下图左边所示。但是STL这种写法每次划分子序列之后仅对右子序列进行函数调用,左边子序列进行正常的循环调用, 如下图右边所示。
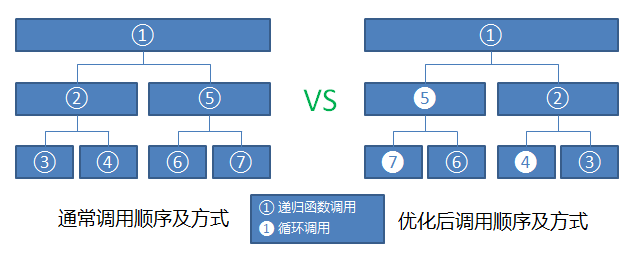
两者区别就在于STL节省了接近一半的函数调用,由于每次的函数调用有一定的开销,因此对于数据量非常庞大时,这一半的函数调用可能能够省下相当可观的时 间。真是为了效率无所不用其极,令人惊叹!更关键是这并没有带来太多的可读性的降低,稍稍一经分析便能够读懂。这种稍稍以牺牲可读性来换取效率的做法在 STL的实现中比比皆是,本文后面还会有例子。(more)
本文是关于调试器工作原理探究系列的第二篇。在开始阅读本文前,请先确保你已经读过本系列的第一篇(基础篇)。
本文的主要内容
这里我将说明调试器中的断点机制是如何实现的。断点机制是调试器的两大主要支柱之一 ——另一个是在被调试进程的内存空间中查看变量的值。我们已经在第一篇文章中稍微涉及到了一些监视被调试进程的知识,但断点机制仍然还是个迷。阅读完本文之后,这将不再是什么秘密了。

软中断
要在x86体系结构上实现断点我们要用到软中断(也称为“陷阱”trap)。在我们深入细节之前,我想先大致解释一下中断和陷阱的概念。
CPU有一个单独的执行序列,会一条指令一条指令的顺序执行。要处理类似IO或者硬件时钟这样的异步事件时CPU就要用到中断。硬件中断通常是一个 专门的电信号,连接到一个特殊的“响应电路”上。这个电路会感知中断的到来,然后会使CPU停止当前的执行流,保存当前的状态,然后跳转到一个预定义的地 址处去执行,这个地址上会有一个中断处理例程。当中断处理例程完成它的工作后,CPU就从之前停止的地方恢复执行。
软中断的原理类似,但实际上有一点不同。CPU支持特殊的指令允许通过软件来模拟一个中断。当执行到这个指令时,CPU将其当做一个中断——停止当 前正常的执行流,保存状态然后跳转到一个处理例程中执行。这种“陷阱”让许多现代的操作系统得以有效完成很多复杂任务(任务调度、虚拟内存、内存保护、调 试等)。
一些编程错误(比如除0操作)也被CPU当做一个“陷阱”,通常被认为是“异常”。这里软中断同硬件中断之间的界限就变得模糊了,因为这里很难说这种异常到底是硬件中断还是软中断引起的。我有些偏离主题了,让我们回到关于断点的讨论上来。
关于int 3指令
看过前一节后,现在我可以简单地说断点就是通过CPU的特殊指令——int 3来实现的。int就是x86体系结构中的“陷阱指令”——对预定义的中断处理例程的调用。x86支持int指令带有一个8位的操作数,用来指定所发生的 中断号。因此,理论上可以支持256种“陷阱”。前32个由CPU自己保留,这里第3号就是我们感兴趣的——称为“trap to debugger”。
不多说了,我这里就引用“圣经”中的原话吧(这里的圣经就是Intel’s Architecture software developer’s manual, volume2A):
“INT 3指令产生一个特殊的单字节操作码(CC),这是用来调用调试异常处理例程的。(这个单字节形式非常有价值,因为这样可以通过一个断点来替换掉任何指令的第一个字节,包括其它的单字节指令也是一样,而不会覆盖到其它的操作码)。”
上面这段话非常重要,但现在解释它还是太早,我们稍后再来看。
使用int 3指令
是的,懂得事物背后的原理是很棒的,但是这到底意味着什么?我们该如何使用int 3来实现断点机制?套用常见的编程问答中出现的对话——请用代码说话!
实际上这真的非常简单。一旦你的进程执行到int 3指令时,操作系统就将它暂停。在Linux上(本文关注的是Linux平台),这会给该进程发送一个SIGTRAP信号。
这就是全部——真的!现在回顾一下本系列文章的第一篇,跟踪(调试器)进程可以获得所有其子进程(或者被关联到的进程)所得到信号的通知,现在你知道我们该做什么了吧?
就是这样,再没有什么计算机体系结构方面的东东了,该写代码了。
手动设定断点
现在我要展示如何在程序中设定断点。用于这个示例的目标程序如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
section .text
;The _start symbol must be declared forthe linker(ld)
global_start
_start:
;Prepare arguments forthe sys_write system call:
; -eax:system call number(sys_write)
; -ebx:file descriptor(stdout)
; -ecx:pointer tostring
; -edx:stringlength
mov edx,len1
mov ecx,msg1
mov ebx,1
mov eax,4
;Execute the sys_write system call
int 0x80
;Now print the other message
mov edx,len2
mov ecx,msg2
mov ebx,1
mov eax,4
int 0x80
;Execute sys_exit
mov eax,1
int 0x80
section .data
msg1 db ‘Hello,‘,0xa
len1 equ $-msg1
msg2 db ‘world!‘,0xa
len2 equ $-msg2
|
我现在使用的是汇编语言,这是为了避免当使用C语言时涉及到的编译和符号的问题。上面列出的程序功能就是在一行中打印“Hello,”,然后在下一行中打印“world!”。这个例子与上一篇文章中用到的例子很相似。
我希望设定的断点位置应该在第一条打印之后,但恰好在第二条打印之前。我们就让断点打在第一个int 0x80指令之后吧,也就是mov edx, len2。首先,我需要知道这条指令对应的地址是什么。运行objdump –d:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
traced_printer2: file formatelf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0.text 00000033 08048080 08048080 00000080 2**4
CONTENTS,ALLOC,LOAD,READONLY,CODE
1.data 0000000e 080490b4 080490b4 000000b4 2**2
CONTENTS,ALLOC,LOAD,DATA
Disassembly of section.text:
08048080<.text>:
8048080: ba07000000 mov $0x7,%edx
8048085: b9 b4900408 mov $0x80490b4,%ecx
804808a: bb01000000 mov $0x1,%ebx
804808f: b804000000 mov $0x4,%eax
8048094: cd80 int $0x80
8048096: ba07000000 mov $0x7,%edx
804809b: b9 bb900408 mov $0x80490bb,%ecx
80480a0: bb01000000 mov $0x1,%ebx
80480a5: b804000000 mov $0x4,%eax
80480aa: cd80 int $0x80
80480ac: b801000000 mov $0x1,%eax
80480b1: cd80 int $0x80
|
通过上面的输出,我们知道要设定的断点地址是0x8048096。等等,真正的调试器不是像这样工作的,对吧?真正的调试器可以根据代码行数或者函 数名称来设定断点,而不是基于什么内存地址吧?非常正确。但是我们离那个标准还差的远——如果要像真正的调试器那样设定断点,我们还需要涵盖符号表以及调 试信息方面的知识,这需要用另一篇文章来说明。至于现在,我们还必须得通过内存地址来设定断点。
看到这里我真的很想再扯一点题外话,所以你有两个选择。如果你真的对于为什么地址是0x8048096,以及这代表什么意思非常感兴趣的话,接着看下一节。如果你对此毫无兴趣,只是想看看怎么设定断点,可以略过这一部分。
题外话——进程地址空间以及入口点
坦白的说,0x8048096本身并没有太大意义,这只不过是相对可执行镜像的代码段(text section)开始处的一个偏移量。如果你仔细看看前面objdump出来的结果,你会发现代码段的起始位置是0x08048080。这告诉了操作系统 要将代码段映射到进程虚拟地址空间的这个位置上。在Linux上,这些地址可以是绝对地址(比如,有的可执行镜像加载到内存中时是不可重定位的),因为在 虚拟内存系统中,每个进程都有自己独立的内存空间,并把整个32位的地址空间都看做是属于自己的(称为线性地址)。
如果我们通过readelf工具来检查可执行文件的ELF头,我们将得到如下输出:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
$readelf-htraced_printer2
ELF Header:
Magic: 7f454c46010101000000000000000000
Class: ELF32
Data: 2‘scomplement,little endian
Version: 1(current)
OS/ABI: UNIX-SystemV
ABI Version: 0
Type: EXEC(Executable file)
Machine: Intel80386
Version: 0x1
Entry point address: 0x8048080
Start of program headers: 52(bytes into file)
Start of section headers: 220(bytes into file)
Flags: 0x0
Size of thisheader: 52(bytes)
Size of program headers: 32(bytes)
Number of program headers: 2
Size of section headers: 40(bytes)
Number of section headers: 4
Section header stringtable index: 3
|
注意,ELF头的“entry point address”同样指向的是0x8048080。因此,如果我们把ELF文件中的这个部分解释给操作系统的话,就表示:
1. 将代码段映射到地址0x8048080处
2. 从入口点处开始执行——地址0x8048080
但是,为什么是0x8048080呢?它的出现是由于历史原因引起的。每个进程的地址空间的前128MB被保留给栈空间了(注:这一部分原因可参考 Linkers and Loaders)。128MB刚好是0x80000000,可执行镜像中的其他段可以从这里开始。0x8048080是Linux下的链接器ld所使用的 默认入口点。这个入口点可以通过传递参数-Ttext给ld来进行修改。
因此,得到的结论是这个地址并没有什么特别的,我们可以自由地修改它。只要ELF可执行文件的结构正确且在ELF头中的入口点地址同程序代码段(text section)的实际起始地址相吻合就OK了。
通过int 3指令在调试器中设定断点
要在被调试进程中的某个目标地址上设定一个断点,调试器需要做下面两件事情:
1. 保存目标地址上的数据
2. 将目标地址上的第一个字节替换为int 3指令
然后,当调试器向操作系统请求开始运行进程时(通过前一篇文章中提到的PTRACE_CONT),进程最终一定会碰到int 3指令。此时进程停止,操作系统将发送一个信号。这时就是调试器再次出马的时候了,接收到一个其子进程(或被跟踪进程)停止的信号,然后调试器要做下面几 件事:
1. 在目标地址上用原来的指令替换掉int 3
2. 将被跟踪进程中的指令指针向后递减1。这么做是必须的,因为现在指令指针指向的是已经执行过的int 3之后的下一条指令。
3. 由于进程此时仍然是停止的,用户可以同被调试进程进行某种形式的交互。这里调试器可以让你查看变量的值,检查调用栈等等。
4. 当用户希望进程继续运行时,调试器负责将断点再次加到目标地址上(由于在第一步中断点已经被移除了),除非用户希望取消断点。
标签:
原文地址:http://www.cnblogs.com/LUO77/p/5816325.html