标签:
查询处理的四个步骤:
1.查询分析
分析时主要进行词法和语法分析。
首先对整条sql语句进行扫描,根据数据库数据字典中的数据标记,识别出sql的关键字、关系名和属性名等词组,检查是否存在词法错误。完成后检查语句排列是否符合语法规则,如果符合的话进入下一环节,否则直接报错。
2.查询检查
检查主要包括语义检查和完整性检查。
sql的基本分析流程和编译器的分析流程是相似的,只不过多加了sql特殊的检查。
语义分析时,根据数据字典定义的数据库对象名、关系名、属性名和视图、过程和函数等数据库建造者自定义的名称检查词法分析中的“词”,检验词是否存在和有效。同时,对于视图操作,需要将对视图的操作转换为对基本表的操作。
完整性检查主要是检查用户的权限能力,如果用户没有权限或是权限不够就拒绝执行语句。
查询检查之后sql语句将转换为对应的关系代数表达式。
实例:
检索学习课程号为C2的学生学号与成绩
sql语句:
SELECT SNO,GRADE FROM SC WHERE CNO=‘C2‘
关系代数表达式:
π SNO, GRADE (σ CNO=‘C2‘ (SC))
3.查询优化
每个查询都会有执行策略和操作算法,查询优化就是根据数据库和sql语句选择最好的查询方式。一般的查询优化有两种:代数优化和物理优化。
4.查询执行
优化器根据优化策略生成查询执行计划,代码生成器将执行计划编译和执行,并返回结果。
整个过程的流程图如下:

代数优化
sql语句执行完查询检查后得到查询树,也就是关系代数表达式,代数优化就是等价变换关系代数表达式,以此来提高查询效率。
代数优化的原则
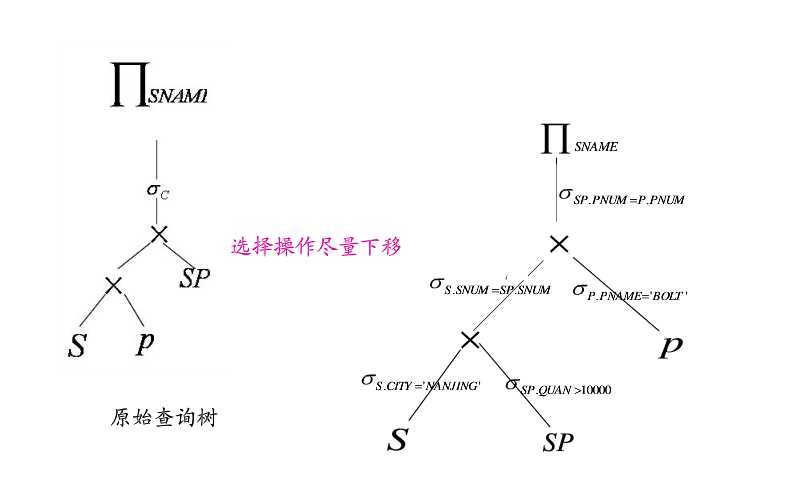
1.先做选择和投影
在进行sql语句查询的时候必须先做选择操作,确定操作对象,如果sql语句中同时还有投影操作也一起进行,投影操作其实也可以看做是一种选择操作,为了避免重复扫描sql语句,投影和选择同时进行。
2.预处理连接操作
连接操作是非常大的消耗,为了加快连接操作,可以对数据建立索引或排序。
3.投影结合双目运算
投影操作结合之前或之后的双目元素,没有必要为了去掉某些字段二扫描一遍关系。
单目运算时对一个关系施加的运算。双目运算是对两个关系时间的运算。
选择、投影是单目运算符,连接和笛卡尔乘积是双目运算符。
4.选择结合笛卡尔运算
把选择操作结合笛卡尔运算形成连接运算,连接运算(特别是等值连接)比笛卡尔乘积要省很多时间。
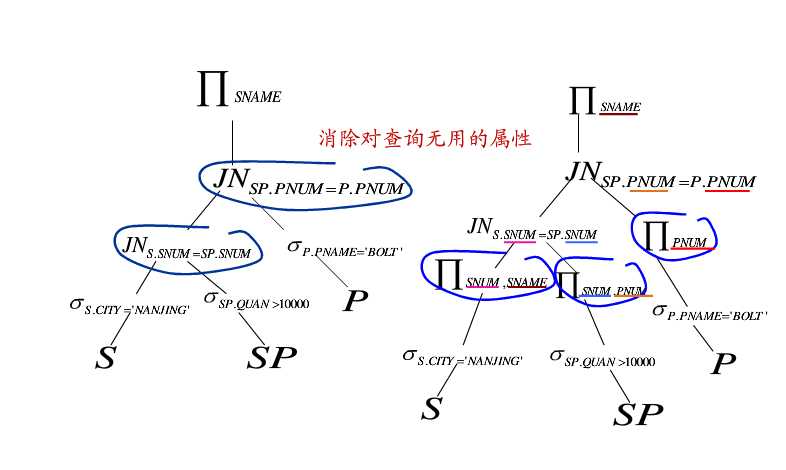
5.找出公共子表达式
就是先计算大家都会用到表达式结果,减少重复计算。
第3和4条说白了就是将单目运算想尽办法结合双目运算,单目运算有选择和投影,选择是根据条件选择符合条件的选项,投影是筛选数据的属性。投影可以结合连接或笛卡尔乘积,先将两张表合成一张表在筛选属性。选择只需要结合笛卡尔乘积,因为连接本来就是选择后的结果,不需要在选择了。
关系代数优化步骤
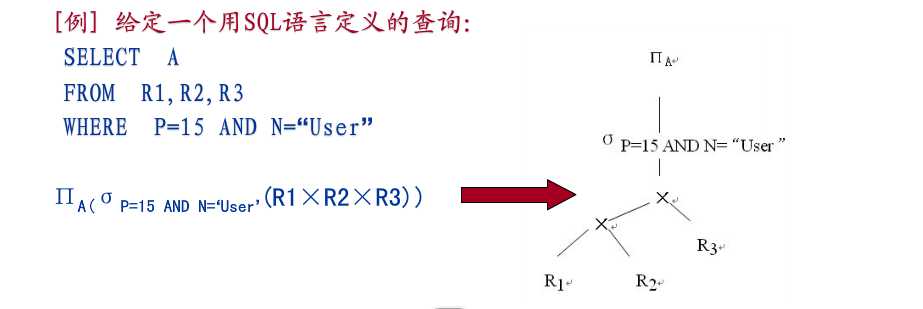
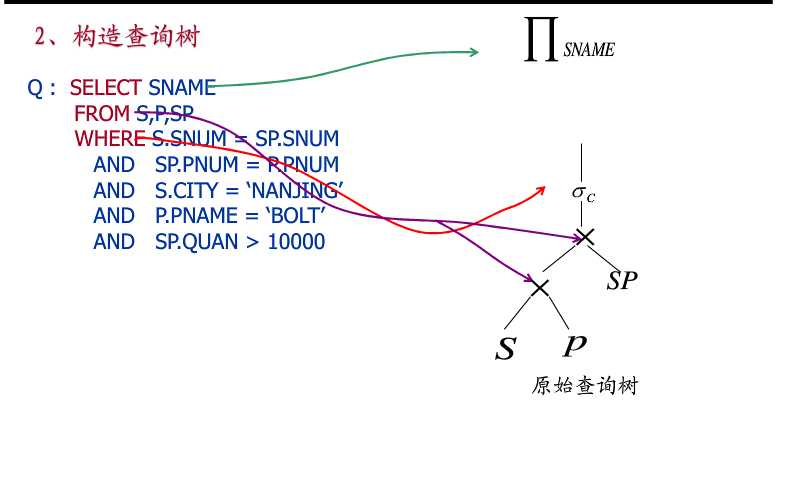
1.构造查询树
将sql语句中的关键字变换成关系代数运算符,以下是对应关系:
where-选择运算-σ
select-投影运算-∏
from-笛卡尔乘积-χ
然后构造树形结构,叶子节点表示关系,内部节点代数操作。自底向上进行查询操作。
物理优化
代数优化仅仅是改变查询语句中的操作的次序和组合,不涉及底层的存取路径,应对小的数据库还可以,但是对于大型数据库还需要数据存取优化,所以就发展了物理优化,选择高效合理的操作算法和存取路径。
物理优化的三种优化算法:
1.基于规则的启发式操作
选择操作的启发式规则:
对于小关系,使用全表顺序扫描,即使选择列上有索引
对于大关系,启发式规则有:
查询结果最多是一个元组,可以选择主码索引
一般的RDBMS会自动建立主码索引。
要估算查询结果的元组数目,如果比例较小(<10%)可以使用索引扫描方法
否则还是使用全表顺序扫描
要估算查询结果的元组数目,如果比例较小(<10%)可以使用索引扫描方法
否则还是使用全表顺序扫描
如果有涉及这些属性的组合索引,优先采用组合索引扫描方法
如果某些属性上有一般的索引,则可以前四种扫描方法
否则使用全表顺序扫描。
一般使用全表顺序扫描
基于启发的优化方法实现简单并且优化代价较小,适合解释执行的系统。(关于解释执行和编译执行和编译器的链接:http://lavasoft.blog.51cto.com/62575/187229)
但是对于编译执行的系统则不适用。
基于代价估算的优化
基于代价的优化方法要计算各种操作算法的执行代价,与数据库的状态密切相关。
数据字典中存储的优化器需要的统计信息:
1. 对每个基本表:
该表的元组总数(N)
元组长度(l)
占用的块数(B)
占用的溢出块数(BO)
2.每个表的基本列
选择率(f)
如果不同值的分布是均匀的,f=1/m
如果不同值的分布不均匀,则每个值的选择率=具有该值的元组数/N
该列最大值
该列最小值
该列上是否已经建立了索引
索引类型(B+树索引、Hash索引、聚集索引)
3. 对索引(如B+树索引)
索引的层数(L)
不同索引值的个数
索引的选择基数S(有S个元组具有某个索引值)
索引的叶结点数(Y)
标签:
原文地址:http://www.cnblogs.com/x739400043/p/5829603.html