标签:
一、数据源的产生
1、JDBC操作原理
(1) 加载数据库驱动程序(数据库驱动程序可通过classpath配置);
Class.forName();
(2)通过DriverManager类取得数据库连接对象;
Connection conNn = DriverManager.getConnection();
(3)通过Connection实例化PreparedStatement对象,编写SQL命令操作数据库;
PreparedStatement ps = conn.prepareStatement(sql);
ps.executeQuery();
(4)数据库属于资源操作,操作完成后要关闭数据库以及释放资源。
con.close();
2、由于每一个用户进行数据库操作时都要经过相同的(1)(2)(4)步骤,但每个用户对于数据库的操作却是不同,所以在进行数据库操作时如果可以将重复的3个步骤去掉而只保留步骤3的话性能肯定能有所提高。
二、数据源简介
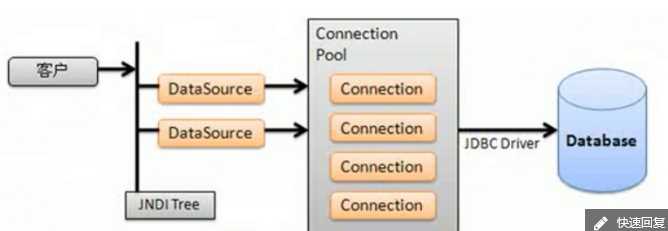
1、数据源的核心原理:在一个对象池中保存多个数据库连接(也成为数据库连接池--Connection Pool),用户对数据库进行操作时取出一个,用完后放回连接等待其他用户继续使用;
2、考虑因素:
1>最小连接数:如果一个程序在使用时没有一个用户连接,则数据库最小应该维持的数据库连接 数;
2>最大连接数:在一个程序中一个数据库最多可以打开的数据库连接数;
3>最大等待时间:当一个数据库连接池中已经没有更多的数据库连接提供给用户时,其他用户的最大等待时间,如果再等到的时间内有放回则可以继续使用,否则用户无法取得数据库连接。
由此我们可以Java应用程序实现,先在一个类集中保存多个数据库连接对象,之后通过控制类集达到连接池功能的实现,但是这样就要考虑多线程问题,以上三种问题也要考虑,实现起来比较困难; Tomcat4.1.x版本之后已经支持了此操作,所以在Web开发中可以直接通过Tomcat即可实现数据库连接池功能;除此之外也可通过数据库连接池组件进行实现 如Apache组织的C3P0组件。
3、web容器中数据库的连接池都是通过数据源(javax.sql.Datasource)访问的,即可以通过javax.sql.Datasource类得到一个Connection对象,而想要的得到DataSource对象需要使用JNDI进行查找(JNDI--java 命名及目录接口,java EE13种技术之一,主要功能是通过一个名称的key查找到对应的一个value)
三、数据源的实现
注意,mysql-connector-java-5.1.6-bin.jar 包存放于 docBase所指定的lib目录下或者Tomcat安装文件下的lib中
1、配置数据库连接池,server.xml文件
<Context path="/kk" docBase="D:\Local\webKK" reloadable="true">
<Resource
name="jdbc/xrk" ->配置一个连接池资源,名称为jdbc/xrk
auth="Container" ->容器负责资源的连接
type="javax.sql.DataSource" ->此数据源名称对应的类型是DataSource
maxActive="100" ->最大连接数
maxIdle="30" ->最小连接数
maxWait="10000" ->用户等待的最大时间
username="root" ->数据库用户名
password="kk" ->数据库密码
driverClassName="org.gjt.mm.mysql.Driver" ->数据库驱动程序
url="jdbc:mysql://localhost:3306/test" ->数据库名称
/>
</Context>
以上配置是全局数据源配置,全局数据源意思是配置了一个数据源后任何web应用都能够访问。
<Resource>节点中的auth选项表示的是连接数据库的方法:
Container--容器将代表应用程序登录到资源管理器(常用);
Application--应用程序必须程序化的登录到资源管理器。
2、配置web.xml文件
注意在文件中指明要使用的数据源名;
<display-name>Welcome to Tomcat</display-name>
<resource-ref>
<description>DB Connection</description>
<res-ref-name>jdbc/xrk</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
</web-app>
3、查找数据源
数据源的操作使用的是JNDI方式进行查找,步骤如下:
1>初始化名称查找上下文:Context ctx=new InitialContext();
2>通过名称查找DataSource对象:DataSource ds=(DataSource)ctx.lookup(DSNAME);
3>通过DataSource取得一个数据库连接:Connection conn=ds.getConnection();
<%@ page contentType="text/html" pageEncoding="utf-8"%>
<%@ page import="javax.naming.*"%>
<%@ page import="javax.sql.*"%>
<%@ page import="java.sql.*"%>
<html>
<head><title>xur</title></head>
<body>
<%
String DSNAME="java:comp/env/jdbc/xrk"; //JNDI名称
Context ctx=new InitialContext();
DataSource ds=(DataSource)ctx.lookup(DSNAME);
Connection conn=ds.getConnection();
%>
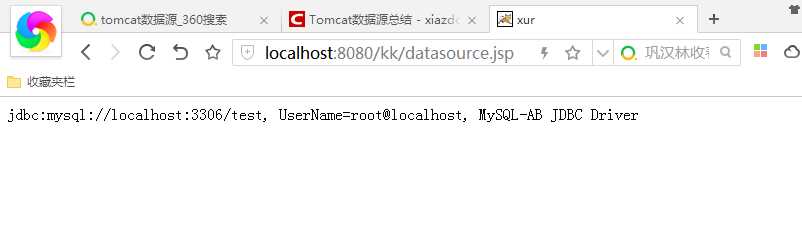
<%=conn%>
<%
conn.close();
%>
</body>
</html>
上述文件中初始化JNDI名称时前面加了java:comp/env/前缀,主要是为了解决JNDI查找时的冲突问题(java EE规定的环境命名上下文--Environment Naming Context(ENC))
运行该程序,取得连接则输出如下,否则输出null。
四、使用数据库连接池的好处
1、通过数据库连接池可以提升数据库的操作性能,可以避免类加载、数据库连接、数据库关闭等操作;
2、数据源操作时要使用JNDI查找,而且查找时需要制定前缀属性。
标签:
原文地址:http://www.cnblogs.com/iamkk/p/5830462.html