标签:
1、Python集合
2、Python文件操作
3、Python字符编码
4、Python函数介绍
list_1 = [1,3,5,7,26,8,65]
list_1=set(list_1)
list_2 =set([2,4,5,6,7,9,65])
print (list_1,list_2)
print ("交集:", list_1.intersection(list_2)) #交集
print("并集",list_1.union(list_2)) #并集
print("差集:",list_1.difference(list_2)) #差集 in list_1 but in list_2
print (list_2.difference(list_1))
list_3 = set([5,7])
print (list_3.issubset(list_2)) #判断是否是子集
print(list_2.issuperset(list_3)) ##判断是否是父集
print(list_1.symmetric_difference(list_2))#对称差集 , 取list_1和list_2对方都没有的取出来,即将都有的去掉。
list_4 = set([98,97])
print (list_1.isdisjoint(list_4)) #交集为空,返回True ;否则返回False
list_1.add(999) #添加一项
list_1.update([888,777,666])#添加多项
#list_1.remove(‘H‘)#删除
print("HHHH:",list_1.discard(‘o‘)) #删除字,若有删除,若没有什么也不做
#x in a#测试x 是否是 a 的成员
#x not in a #测试x是否不在 a 的成员
1)文件的写(w):
新建文件并将内容写进该文件,若有文件则覆盖掉。
f=open(‘yesterday2‘,‘w‘,encoding=‘utf-8‘)
f.write("wo ye bu zhi dao ni zai shuo shen me!")
2)文件的读(r):
f=open(‘yesterday2‘,‘r‘,encoding=‘utf-8‘)
print(f.read()) #全部读出
print (f.readline()) #只读一行
print (f.readlines()) #读出剩余的行
2)文件的追加(a):
f=open(‘yesterday2‘,‘a‘,encoding="utf-8") #文件句柄,将文件的内容最佳到文件的后面
3)文件的遍历:
#要把内容全部读出来,浪费内存,慢
for index,line in enumerate(f.readlines()):
if index ==9:
priint ("---------------我是分割线---------------")
contnue
print (line.strip())
#高校的做法
count=0
for line in f:
if count ==9:
print("-------------分割线------------")
print (line.strip())
else:
print (line.strip())
count+=1
4)文件的修改:
f = open(‘yesterday2‘,‘r‘,encoding=‘utf-8‘)
f_bak = open(‘yesterday2_bak‘,‘w‘,encoding=‘utf-8‘)
for line in f:
if "当我年少轻狂" in line:
line=line.replace(‘当我年少轻狂‘,‘年少轻狂‘)
f_bak.write(line)
f.close()
f_bak.close()
5)文件的其他操作:
print(f.encoding)
f.seek(0) #处理光标的位置
print (f.fileno()) #系统处理文件的编号
print(f.flush()) #等到缓存满了 一起刷到内存中
print(f.buffer) #刷新缓存
f.truncate(20) #不写就是清空 ,从头开始截断
f=open(‘yesterday‘,‘r+‘,encoding="utf-8") #可以先读后写 ------读写模式
f=open(‘yesterday‘,‘w+‘,encoding="utf-8") #可以先写后读-------写读模式
f=open(‘yesterday‘,‘a+‘,encoding="utf-8") #追加读写
f=open(‘yesterday‘,‘rb‘) #读取二进制文件 在socked的网络传输过程中只能用二进制格式;下载文件二进制
f=open(‘yesterday‘,‘wb‘) #二进制的写
f.write("hello ,binary\n".encode()) # bytes 转成二进制格式
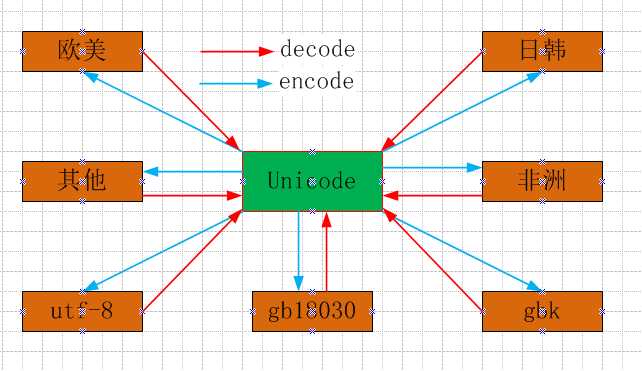
三、Python字符编码
unicode为万国码,所有其他字符编码间的转换都要经过unicode, "string".decode("one").encode("another"):
文件先解码(decode)成unicode,并告诉unicode我当前的编码格式, 之后再编码(encode)为即将使用改文件的程序的编码格式
1)函数的定义:
def test1():
print("the funtion ")
def test1(x): #带参数
"the funtion "
x +=1
return x
def sum(a,b,*args): #*args接收N个位置参数,转换成元组
print(a)
print(b)
print(args)
print(sum(100,1,1)
def sun1(**kwargs): #**kwargs接收N个关键字参数,转换成字典
print (kwargs)
print (kwargs[‘name‘])
2)函数的递归:
#递归必须要有一个明确的结束条件
#问题的规模较上一次要小
#执行效率低,递归会导致栈溢出 函数调用通过计算机的栈
# def calc(m):
# print (m)
# if m<100:
# return calc(m+1)
# else:
# pass
3)高阶函数:
#变量可以指向函数,函数参数可以接受变量,一个函数也可以接受另一个函数做为参数,这种函数就叫做高阶函数
def add(a,b,f):
return f(a)+f(b)
res=add(3,-6,abs)
print(res)
标签:
原文地址:http://www.cnblogs.com/sunfu/p/5832573.html