标签:
在编者看到“【重磅】微信开源PhxSQL:高可用、强一致的MySQL集群”时,由衷赞叹,这等造福广大DBA及运维同仁的事情,真心赞。腾讯及微信的开放,真的不是说说而已。
本文由资深DB从业者撰写,相信其本意更多聚焦在技术的逻辑性,及引发的思与辩。祝愿PhxSQL越来越好,让世界看到中国开源的力量。
今天微信在微信朋友圈发表了其在MySQL领域实现的一套高可用、强一致的集群方案,顿时朋友圈刷屏,都在啧啧称赞。
有些人转发是用来Mark一下,留着后面细细品尝,有些人应该是看过了,说是高质量的开源,而还有一些人,说是有Galera或者group replication的味道。
在我知道这事儿之后,心里很高兴,觉得太强大了,想必是一个非常好的方案,首先要感谢微信团队,在开源的路上又带了一个好头。
在看完之后,我心里面是忐忑的,因为目前所能看到的实现架构或者支持的功能与朋友圈转发的架势来看有很大的出入,所以关于微信的这个开源,我问了一下我周边的朋友,我说为啥这个这么火?
我自己觉得有两方面的原因:
一是微信开源这个动作本身,微信在国内的影响力太大了。
二是这个MySQL解决方案,MySQL太需要靠谱的高可用和一致性解决方案了,目前来看,还无出Galera其右者。
腾讯最近在这方面做了很多工作,开源了不少产品,这是值得庆贺的,这是圈内的福利,圈内的良心,如果非常火,这是有道理的,这是圈内的正能量,我一直希望有更多的公司或者个人,能开源更多的好产品,一起进步一起成长。
我花了一个下午的时间认真研究了一下PhxSQL,优点已经在别的文章里面都说得很多了,我就不再赘述了。
从技术方案的角度来看,我来说说在研究或者将来计划使用PhxSQL的话,有什么需要注意的地方。
时间比较仓促,也许有理解不对的地方,也请大家支招。现在还没来得及看代码,以后如果有机会继续深入研究的话,可以在后续文章中加以说明。
我觉得大家在研究的时候,要注意以下几个部分:
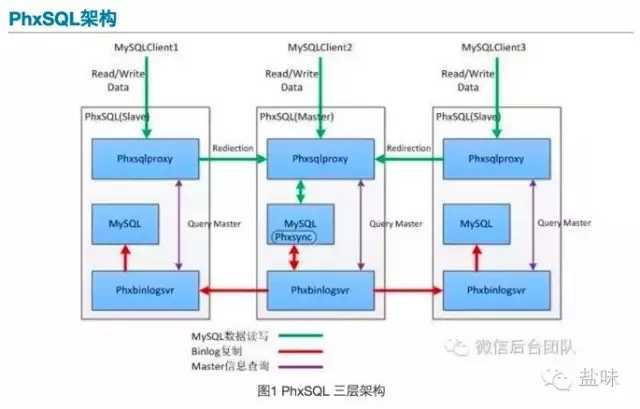
这个是很明确的,图1中可以看到phxSQL的架构,原本一套集群只有MySQL三个节点,现在加入了两个新的服务:Phxbinlogsvr、Phxsqlproxy。
很明显,模块越多,整个集群的故障率就越高,不可靠性就越高,部署这么一套集群需要多久?
需要考虑入手门槛。
模块多了,机器压力及相应成本就增加了,同时DBA需要运维的对象就多了,压力变大了,这都是需要考虑的问题。
有些评论说到了,其实现架构有Galera或者group replication的味道,在我研究之后,这两者之间还是差距比较的大。
说白了,PhxSQL还是主从架构,只是将原来的Binlog从主节点复制到从节点的架构,修改为从主节点,复制到Phxbinlogsvr集群,然后MySQL从节点再从Phxbinlogsvr中拉取。
这样的实现方式,增加了中间一层服务,势必数据复制的延迟时间就会有所增加,主从延迟之后,还如何能做到对用户无影响的随意切换呢?
或者说,如果当前正在主从延迟(司空见惯了),那自动切换程序如何选择?等待?还是强制切换?
这种情况下,要么牺牲一致性,要么牺牲可用性,很难做到像Galera那样的两全。
接着上面说,Galera或者group replication,最大的革命是支持了多点写入,这个特性我认为是最大的最有意义的特点。
因为目前在MySQL主从复制的方案中,我们所做的高一致性的工作,都是因为不能双写(单点写入)所导致的,而支持了多点写入即可实现对应用程序零影响的去运维了。
而PhxSQL的多点写入,从架构图1中可以看出,支持的多点写入是通过中间层来转发的,中间层Phxsqlproxy还是找到了写节点,将写入打到Master上面,这完全不是一个概念。
如果我想主动切的,还是要把当前的Master设置为Readonly,然后找到新的Master取消Readonly,然后继续写入,那这样势必影响了业务。所以主从复制的模式先天性的不支持多点写入。
从宣传文章中的图2.1来看,这个图所示的是我们平常所使用的半同步的示意图。
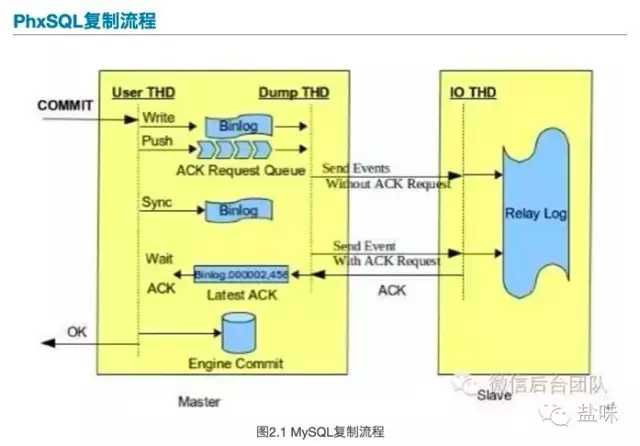
上图是我们每个人都熟悉的,而我们可以看看PhxSQL的图2.2。
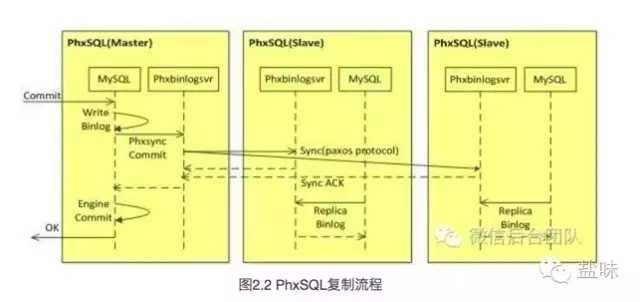
很明显可以看得出,这个有点像5.7中的等待多点节点ACK的半同步了,但这里等待的是Phxbinlogsvr返回的ACK。
是的,在使用了Paxos协议的情况下,Phxbinlogsvr会向其它几个节点复制Binlog,但集群中只有3个节点的情况下,必须要等其它2个节点的ACK,不然不能超过半数。
那么此时和3个节点的半同步相比,性能似乎也没什么太大的区别。所以从这个图中可以看到,实际上实现的架构就是半同步。
另外,宣传文章中说到了,PhxSQL可以保证的是从库节点不回滚,这个说法我是支持的,半同步确实有时候是需要回滚的,PhxSQL解决了这个问题。解决方案是,针对Master,可能还是存在回滚数据的可能性的,但对于Slave,只需要补数据即可。
但我的疑问是,用这么复杂的架构来解决这个回滚的问题,有多大产出比?
这个算一个问题,在MySQL5.6中,至少是可以并行复制的,或者5.7的话,更好的并行复制。
而在PhxSQL中,因为中间插入一个Phxbinlogsvr,那从Phxbinlogsvr到MySQL的应用,是如何支持并行的,是像原生的把Phxbinlogsvr做为一个主库,向MySQL从节点Send,让MySQL用原生的复制?还是自己做了新的开发?
上面已经说过,这么一个复杂的架构,每个模块本身的存活及健壮性如何保证,也就是它们的监控程序如何来做,监控程序是否可以做到公布式的监控?或者这个监控就是相互监控?
这也算一个问题吧,因为监控是集群健壮性必不可少的一部分。
最后一点,如果舍弃半同步的数据回滚(假设可以接受),那如果和一个中间层加上半同步的实现方案相比,优势在哪里?
标签:
原文地址:http://www.cnblogs.com/zengkefu/p/5835508.html