标签:
陆陆续续做了有一个月,期间因为各种技术问题被多次暂停,最关键的一次主要是因为存储容器使用的普通二叉树,在节点权重相同的情况下导致树高增高,在进行遍历的时候效率大大降低,甚至在使用递归的时候导致栈内存溢出。后来取消递归遍历算法,把普通的二叉排序树升级为平衡二叉树这才解决这些问题。着这个过程中把栈、队列、链表、HashMap、HashTable各种数据结构都重新学习了一遍,使用红黑二叉树实现的TreeMap暂时还没有看,后期需要把TreeMap的实现源码学习一下。
为了把项目做成可扩展性的,方便后期进行升级,又把以前看过的设计模式重新学习了一下,收获不小,对编程思想以及原则理解更进一步。以前看了多次也没有分清楚的简单工厂模式、工厂方法模式和抽象工厂模式这次也搞清楚了。站在系统结构的高度去考虑系统设计还是比较有意思的。
下面就简单介绍一下网络爬虫的实现。
如果把爬虫当做一个系统来进行设计,里面涉及的技术是非常多的,包括:链接解析、链接去重、页面内容去重(不同的URL,但页面内容一样)、页面下载技术、域名高速解析技术……这里的每一项都能够扩展成一个大的主题,甚至可以把这些功能单独列出来做成一个小的项目,进行分布式部署。初期计划把这个爬虫的主要模块做出来留出可扩展接口,后期慢慢一步一步进行各个模块的功能完善,尽量把它做成一个功能比较完善的大型系统。项目已经上传到GitHub中,对爬虫有兴趣的朋友可以扩展一下。https://github.com/PerkinsZhu/WebSprider
系统的结构比较简单,可以看一下类图:
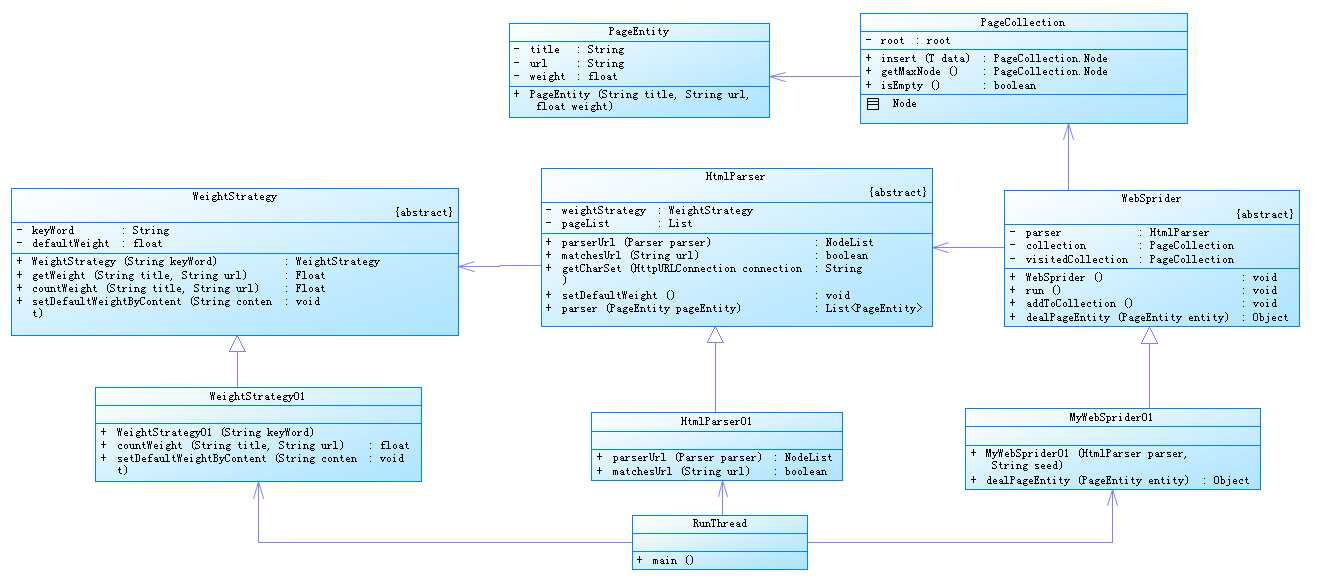
具体讲解一下各个类的作用:
页面实体:PageEntity,代表一个URL。主要有title、URL、weight三个属性,用户可继承继续扩展新的属性。实体必须实现Comparable接口,实现public int compareTo(PageEntity node)方法,在进行存储的时候会根据此方法获取两个节点的比较结果进行存储。
package com.zpj.entity; /** * @author PerKins Zhu * @date:2016年9月2日 下午8:43:26 * @version :1.1 * */ public class PageEntity implements Comparable<PageEntity> { private String title; private String url; private float weight; private int PRIME = 1000000000; public PageEntity(String title, String url, float weight) { super(); this.title = title; this.url = url; this.weight = weight; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public float getWeight() { return weight; } public void setWeight(float weight) { this.weight = weight; } /** * 比较优先级: weight > title > url */ @Override public int compareTo(PageEntity node) { if (this.weight == node.weight) { if (this.title.equals(node.title)) { if (this.url.equals(node.url)) { return 0; } else { return this.url.compareTo(node.url); } } else { return this.title.compareTo(node.title); } } else { return this.weight > node.weight ? 1 : -1; } } //覆写hashCode @Override public int hashCode() { //如果调用父类的hashCode,则每个对象的hashcode都不相同,这里通过url计算hashcode,相同url的hashcode是相同的 int hash, i; for (hash = this.url.length(), i = 0; i < this.url.length(); ++i) hash = (hash << 4) ^ (hash >> 28) ^ this.url.charAt(i); if (hash < 0) { hash = -hash; } return (hash % PRIME); } }
节点存储容器:PageCollection。用来存储实体对象,在程序中主要用来存储待访问节点PageEntity和访问之后节点的hashCode。
这里主要使用的是平衡二叉树,不是太了解的话可以看一下:数据结构—平衡二叉树,里面有详细的实现讲解
主要方法有三个对外公开:public Node<T> insert(T data);插入节点
public T getMaxNode();获取下一个权重最大的节点,同时删除该节点。
public T get(T data) ;查找指定节点
public void inorderTraverse();中序遍历多有节点
public Node<T> remove(T data) ;删除指定节点。
package com.zpj.collection; /** * @author PerKins Zhu * @date:2016年9月2日 下午9:03:35 * @version :1.1 * */ public class PageCollection<T extends Comparable<T>> { private Node<T> root; private static class Node<T> { Node<T> left; Node<T> right; T data; int height; public Node(Node<T> left, Node<T> right, T data) { this.left = left; this.right = right; this.data = data; this.height = 0; } } /** * 如果树中已经存在该节点则不进行插入,如果没有该节点则进行插入 判断是否存在该节点的方法是compareTo(T node) == 0。 * * @param data * @return */ public Node<T> insert(T data) { return root = insert(data, root); } private Node<T> insert(T data, Node<T> node) { if (node == null) return new Node<T>(null, null, data); int compareResult = data.compareTo(node.data); if (compareResult > 0) { node.right = insert(data, node.right); if (getHeight(node.right) - getHeight(node.left) == 2) { int compareResult02 = data.compareTo(node.right.data); if (compareResult02 > 0) node = rotateSingleLeft(node); else node = rotateDoubleLeft(node); } } else if (compareResult < 0) { node.left = insert(data, node.left); if (getHeight(node.left) - getHeight(node.right) == 2) { int intcompareResult02 = data.compareTo(node.left.data); if (intcompareResult02 < 0) node = rotateSingleRight(node); else node = rotateDoubleRight(node); } } node.height = Math.max(getHeight(node.left), getHeight(node.right)) + 1; return node; } private Node<T> rotateSingleLeft(Node<T> node) { Node<T> rightNode = node.right; node.right = rightNode.left; rightNode.left = node; node.height = Math.max(getHeight(node.left), getHeight(node.right)) + 1; rightNode.height = Math.max(node.height, getHeight(rightNode.right)) + 1; return rightNode; } private Node<T> rotateSingleRight(Node<T> node) { Node<T> leftNode = node.left; node.left = leftNode.right; leftNode.right = node; node.height = Math.max(getHeight(node.left), getHeight(node.right)) + 1; leftNode.height = Math.max(getHeight(leftNode.left), node.height) + 1; return leftNode; } private Node<T> rotateDoubleLeft(Node<T> node) { node.right = rotateSingleRight(node.right); node = rotateSingleLeft(node); return node; } private Node<T> rotateDoubleRight(Node<T> node) { node.left = rotateSingleLeft(node.left); node = rotateSingleRight(node); return node; } private int getHeight(Node<T> node) { return node == null ? -1 : node.height; } public Node<T> remove(T data) { return root = remove(data, root); } private Node<T> remove(T data, Node<T> node) { if (node == null) { return null; } int compareResult = data.compareTo(node.data); if (compareResult == 0) { if (node.left != null && node.right != null) { int balance = getHeight(node.left) - getHeight(node.right); Node<T> temp = node; if (balance == -1) { exChangeRightData(node, node.right); } else { exChangeLeftData(node, node.left); } temp.height = Math.max(getHeight(temp.left), getHeight(temp.right)) + 1; return temp; } else { return node.left != null ? node.left : node.right; } } else if (compareResult > 0) { node.right = remove(data, node.right); node.height = Math.max(getHeight(node.left), getHeight(node.right)) + 1; if (getHeight(node.left) - getHeight(node.right) == 2) { Node<T> leftSon = node.left; if (leftSon.left.height > leftSon.right.height) { node = rotateSingleRight(node); } else { node = rotateDoubleRight(node); } } return node; } else if (compareResult < 0) { node.left = remove(data, node.left); node.height = Math.max(getHeight(node.left), getHeight(node.right)) + 1; if (getHeight(node.left) - getHeight(node.right) == 2) { Node<T> rightSon = node.right; if (rightSon.right.height > rightSon.left.height) { node = rotateSingleLeft(node); } else { node = rotateDoubleLeft(node); } } return node; } return null; } private Node<T> exChangeLeftData(Node<T> node, Node<T> right) { if (right.right != null) { right.right = exChangeLeftData(node, right.right); } else { node.data = right.data; return right.left; } right.height = Math.max(getHeight(right.left), getHeight(right.right)) + 1; int isbanlance = getHeight(right.left) - getHeight(right.right); if (isbanlance == 2) { Node<T> leftSon = node.left; if (leftSon.left.height > leftSon.right.height) { return node = rotateSingleRight(node); } else { return node = rotateDoubleRight(node); } } return right; } private Node<T> exChangeRightData(Node<T> node, Node<T> left) { if (left.left != null) { left.left = exChangeRightData(node, left.left); } else { node.data = left.data; return left.right; } left.height = Math.max(getHeight(left.left), getHeight(left.right)) + 1; int isbanlance = getHeight(left.left) - getHeight(left.right); if (isbanlance == -2) { Node<T> rightSon = node.right; if (rightSon.right.height > rightSon.left.height) { return node = rotateSingleLeft(node); } else { return node = rotateDoubleLeft(node); } } return left; } public void inorderTraverse() { inorderTraverseData(root); } private void inorderTraverseData(Node<T> node) { if (node.left != null) { inorderTraverseData(node.left); } System.out.print(node.data + "、"); if (node.right != null) { inorderTraverseData(node.right); } } public boolean isEmpty() { return root == null; } // 取出最大权重的节点返回 ,同时删除该节点 public T getMaxNode() { if (root != null) root = getMaxNode(root); else return null; return maxNode.data; } private Node<T> maxNode; private Node<T> getMaxNode(Node<T> node) { if (node.right == null) { maxNode = node; return node.left; } node.right = getMaxNode(node.right); node.height = Math.max(getHeight(node.left), getHeight(node.right)) + 1; if (getHeight(node.left) - getHeight(node.right) == 2) { Node<T> leftSon = node.left; if (isDoubleRotate(leftSon.left, leftSon.right)) { node = rotateDoubleRight(node); } else { node = rotateSingleRight(node); } } return node; } // 根据节点的树高判断是否需要进行两次旋转 node01是外部节点,node02是内部节点(前提是该节点的祖父节点需要进行旋转) private boolean isDoubleRotate(Node<T> node01, Node<T> node02) { // 内部节点不存在,不需要进行两次旋转 if (node02 == null) return false; // 外部节点等于null,则内部节点树高必为2,进行两侧旋转 // 外部节点树高小于内部节点树高则必定要进行两次旋转 if (node01 == null || node01.height < node02.height) return true; return false; } /** * 查找指定节点 * @param data * @return */ public T get(T data) { if (root == null) return null; return get(data, root); } private T get(T data, Node<T> node) { if (node == null) return null; int temp = data.compareTo(node.data); if (temp == 0) { return node.data; } else if (temp > 0) { return get(data, node.right); } else if (temp < 0) { return get(data, node.left); } return null; } }
爬虫核心类:WebSprider,该类实现了Runnable,可进行多线程爬取。
该类中分别用PageCollection<PageEntity> collection 和PageCollection<Integer> visitedCollection来存储待爬取节点和已爬取节点,其中visitedCollection容器存储的是已爬取节点的hashCode,在pageEntity中覆写了hashCode()方法,计算节点hashCode。
在使用的时候客户端需要继承该类实现一个子类,然后实现public abstract Object dealPageEntity(PageEntity entity);抽象方法,在该方法中处理爬取的节点,可以进行输出、存储等操作。WebSprider依赖于HtmlParser。
package com.zpj.sprider; import java.util.List; import com.zpj.collection.PageCollection; import com.zpj.entity.PageEntity; import com.zpj.parser.HtmlParser; /** * @author PerKins Zhu * @date:2016年9月2日 下午9:02:39 * @version :1.1 * */ public abstract class WebSprider implements Runnable { private HtmlParser parser; // 存储待访问的节点 private PageCollection<PageEntity> collection = new PageCollection<PageEntity>(); // 存储已经访问过的节点 private PageCollection<Integer> visitedCollection = new PageCollection<Integer>(); public WebSprider(HtmlParser parser, String seed) { super(); this.parser = parser; collection.insert(new PageEntity("", seed, 1)); } @Override public void run() { PageEntity entity; while (!collection.isEmpty()) { entity = collection.getMaxNode(); dealPageEntity(entity); addToCollection(parser.parser(entity)); } } private void addToCollection(List<PageEntity> list) { for (int i = 0; i < list.size(); i++) { PageEntity pe = list.get(i); int hashCode = pe.hashCode(); if (visitedCollection.get(hashCode) == null) { collection.insert(pe); visitedCollection.insert(hashCode); } } } /** * 子类对爬取的数据进行处理,可以对entity进行存储或者输出等操作 * @param entity * @return */ public abstract Object dealPageEntity(PageEntity entity); }
页面解析类:HtmlParser
该类为抽象类,用户需要实现其子类并实现 public abstract NodeList parserUrl(Parser parser);和 public abstract boolean matchesUrl(String url);两个抽象方法。
public abstract NodeList parserUrl(Parser parser);用来自定义节点过滤器,返回的NodeList就是过滤出的document节点。
public abstract boolean matchesUrl(String url);用来校验URL是否是用户想要爬取的URL,可以通过正则表达式实现URL校验,返回true则加入容器,否则放弃该URL。
该类依赖于WeightStrategy,权重策略
package com.zpj.parser; import java.net.HttpURLConnection; import java.net.URL; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Set; import org.htmlparser.Parser; import org.htmlparser.util.NodeList; import com.zpj.entity.PageEntity; import com.zpj.weightStrategy.WeightStrategy; /** * @author PerKins Zhu * @date:2016年9月2日 下午8:44:39 * @version :1.1 * */ public abstract class HtmlParser { private WeightStrategy weightStrategy; private List<PageEntity> pageList = new ArrayList<PageEntity>(); public HtmlParser(WeightStrategy weightStrategy) { super(); this.weightStrategy = weightStrategy; } NodeList list; public List<PageEntity> parser(PageEntity pageEntity) { try { String entityUrl = pageEntity.getUrl(); URL getUrl = new URL(entityUrl); HttpURLConnection connection = (HttpURLConnection) getUrl.openConnection(); connection.connect(); Parser parser; parser = new Parser(entityUrl); // TODO 自动设置编码方式 parser.setEncoding(getCharSet(connection)); list = parserUrl(parser); setDefaultWeight(); } catch (Exception e) { e.printStackTrace(); } if (list == null) return pageList; for (int i = 0; i < list.size(); i++) { String url = list.elementAt(i).getText().substring(8); int lastIndex = url.indexOf("\""); url = url.substring(0, lastIndex == -1 ? url.length() : lastIndex); if (matchesUrl(url)) { String title = list.elementAt(i).toPlainTextString(); float weight = weightStrategy.getWeight(title, url); if (weight <= 1) { continue; } pageList.add(new PageEntity(title, url, weight)); } } return pageList; } private void setDefaultWeight() { // 解析出body网页文本内容 String text = ""; // 调用权重策略计算本页面中的所有连接的默认权重,每个页面的默认权重都要重新计算 weightStrategy.setDefaultWeightByContent(text); } /** * 子类实现方法,通过过滤器过滤出节点集合 * @param parser * @return */ public abstract NodeList parserUrl(Parser parser); /** * 子类实现方法,过滤进行存储的url * @param url * @return */ public abstract boolean matchesUrl(String url); //获取页面编码方式,默认gb2312 private String getCharSet(HttpURLConnection connection) { Map<String, List<String>> map = connection.getHeaderFields(); Set<String> keys = map.keySet(); Iterator<String> iterator = keys.iterator(); // 遍历,查找字符编码 String key = null; String tmp = null; while (iterator.hasNext()) { key = iterator.next(); tmp = map.get(key).toString().toLowerCase(); // 获取content-type charset if (key != null && key.equals("Content-Type")) { int m = tmp.indexOf("charset="); if (m != -1) { String charSet = tmp.substring(m + 8).replace("]", ""); return charSet; } } } return "gb2312"; } }
节点权重计算:WeightStrategy,该类为抽象类,用户可自定义权重计算策略,主要实现如下两个方法:
public abstract float countWeight(String title, String url) ;根据title和URL计算出该节点的权重,具体算法由用户自己定义
public abstract void setDefaultWeightByContent(String content);计算出该页面所有连接的基础权重。
也就是说该页面的节点的权重=基础权重(页面权重)+节点权重。基础权重是由该页面的内容分析计算出来,具体算法由public abstract void setDefaultWeightByContent(String content);方法进行计算,然后在public abstract float countWeight(String title, String url) ;计算出该页面中的某个节点权重,最终权重由两者之和。
package com.zpj.weightStrategy; /** * @author PerKins Zhu * @date:2016年9月2日 下午9:04:37 * @version :1.1 * */ public abstract class WeightStrategy { protected String keyWord; protected float defaultWeight = 1; public WeightStrategy(String keyWord) { this.keyWord = keyWord; } public float getWeight(String title, String url){ return defaultWeight+countWeight(title,url); }; /** * 计算连接权重,计算结果为:defaultWeight+该方法返回值 * @param title * @param url * @return */ public abstract float countWeight(String title, String url) ; /** * 根据网页内容计算该页面中所有连接的默认权重 * @param content */ public abstract void setDefaultWeightByContent(String content); }
核心代码就以上五个类,其中两个为数据存储容器,剩下的三个分别是爬虫抽象类、权重计算抽象类和页面解析抽象类。用户使用的时候需要实现这三个抽象类的子类并实现抽象方法。下面给出一个使使用示例:
页面解析:HtmlParser01
package com.zpj.test; import java.util.regex.Pattern; import org.htmlparser.Node; import org.htmlparser.NodeFilter; import org.htmlparser.Parser; import org.htmlparser.util.NodeList; import org.htmlparser.util.ParserException; import com.zpj.parser.HtmlParser; import com.zpj.weightStrategy.WeightStrategy; /** * @author PerKins Zhu * @date:2016年9月2日 下午8:46:39 * @version :1.1 * */ public class HtmlParser01 extends HtmlParser { public HtmlParser01(WeightStrategy weightStrategy) { super(weightStrategy); } @Override public NodeList parserUrl(Parser parser) { NodeFilter hrefNodeFilter = new NodeFilter() { @Override public boolean accept(Node node) { if (node.getText().startsWith("a href=")) { return true; } else { return false; } } }; try { return parser.extractAllNodesThatMatch(hrefNodeFilter); } catch (ParserException e) { e.printStackTrace(); } return null; } @Override public boolean matchesUrl(String url) { Pattern p = Pattern .compile("(http://|ftp://|https://|www){0,1}[^\u4e00-\u9fa5\\s]*?\\.(com|net|cn|me|tw|fr)[^\u4e00-\u9fa5\\s]*"); return p.matcher(url).matches(); } }
权重计算:WeightStrategy01
package com.zpj.test; import com.zpj.weightStrategy.WeightStrategy; /** * @author PerKins Zhu * @date:2016年9月2日 下午8:34:19 * @version :1.1 * */ public class WeightStrategy01 extends WeightStrategy { public WeightStrategy01(String keyWord) { super(keyWord); } public float countWeight(String title, String url) { int temp = 0; while (-1 != title.indexOf(keyWord)) { temp++; title = title.substring(title.indexOf(keyWord) + keyWord.length()); } return temp * 2; } @Override public void setDefaultWeightByContent(String content) { // 解析文本内容计算defaultWeight super.defaultWeight = 1; } }
爬虫主类:MyWebSprider01
package com.zpj.test; import com.zpj.entity.PageEntity; import com.zpj.parser.HtmlParser; import com.zpj.sprider.WebSprider; /** * @author PerKins Zhu * @date:2016年9月2日 下午8:54:39 * @version :1.1 * */ public class MyWebSprider01 extends WebSprider { public MyWebSprider01(HtmlParser parser, String seed) { super(parser, seed); } @Override public Object dealPageEntity(PageEntity entity) { System.out.println(entity.getTitle() + "---" + entity.getWeight() + "--" + entity.getUrl()); return null; } }
测试类:RunThread
package com.zpj.test; import com.zpj.parser.HtmlParser; import com.zpj.sprider.WebSprider; import com.zpj.weightStrategy.WeightStrategy; /** * @author PerKins Zhu * @date:2016年9月2日 下午8:34:26 * @version :1.1 * */ public class RunThread { public static void main(String[] args) { WeightStrategy weightStrategy = new WeightStrategy01("中国"); HtmlParser htmlParser = new HtmlParser01(weightStrategy); WebSprider sprider01 = new MyWebSprider01(htmlParser, "http://news.baidu.com/"); Thread thread01 = new Thread(sprider01); thread01.start(); } }
程序中需要进行完善的有:存储容器的存储效率问题、已爬取节点限制问题(数量最多1000000000,实际远远小于这个数字)、URL去重策略、PageEntity的扩展问题、爬取出的节点处理问题等,后面会逐步进行优化,优化之后会提交到https://github.com/PerkinsZhu/WebSprider
对爬虫有兴趣的朋友如果有什么建议或者程序中有什么错误欢迎留言指出 !
-----------------------------------------------------转载请注明出处!------------------------------------------------------------------------------
标签:
原文地址:http://www.cnblogs.com/PerkinsZhu/p/5836197.html