标签:
十四、正则表达式
正则表达式是用于处理字符串的功能强大的工具,但它并不是Python所独有的,许多编程语言都支持正则表达式,用法也都区别不大;
Python中的正则表达式在re模块中;
Python中的数量词默认是贪婪的,总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符(例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb";而如果使用非贪婪的数量词"ab*",将找到"a"。);
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。
(本文正则表达式部分大部分借鉴于http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html,若有错,欢迎指正)
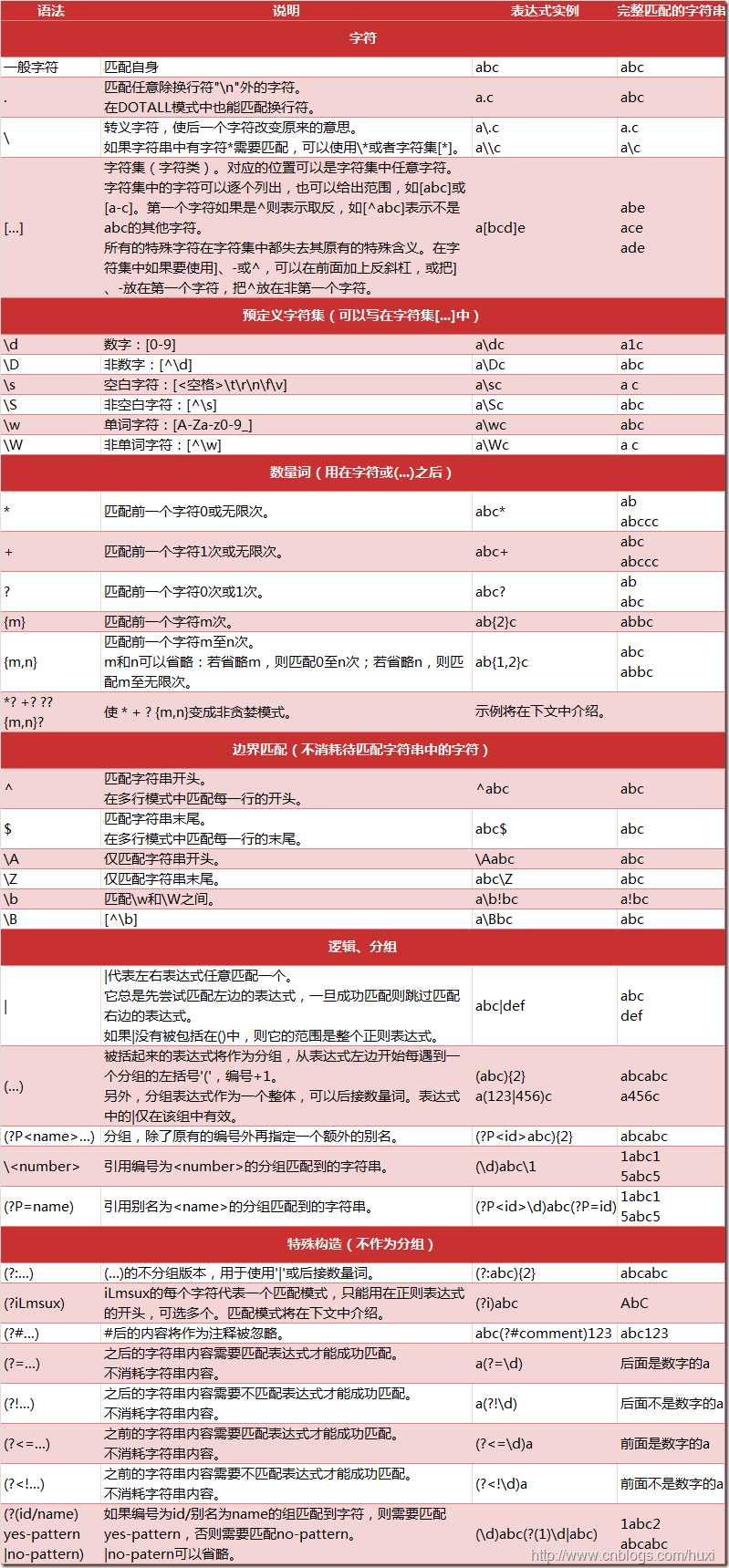
下面介绍re模块中的几个常用方法:
>>> import re >>> pattern = re.compile(‘python‘) # compile将字符串当做正则表达式来编译 >>> result = pattern.search(‘hello python!‘) >>> result <_sre.SRE_Match object; span=(6, 12), match=‘python‘> >>> result.group() ‘python‘ >>> >>> result = re.match(‘a‘, ‘abc‘) # match是从字符串的开头开始匹配 >>> result <_sre.SRE_Match object; span=(0, 1), match=‘a‘> >>> result.group() # 并不直接返回匹配成功的字符串,需要使用group()方法 ‘a‘ >>> result = re.match(‘a‘, ‘dabc‘) >>> result >>> result.group() # 没有匹配成功 Traceback (most recent call last): File "<pyshell#6>", line 1, in <module> result.group() AttributeError: ‘NoneType‘ object has no attribute ‘group‘ >>> >>> result = re.search(‘python‘, ‘abcpythondef‘) # 在字符串的全文中搜索匹配,同样也不会直接返回匹配成功的字符串 >>> result <_sre.SRE_Match object; span=(3, 9), match=‘python‘> >>> result.group() ‘python‘ >>> >>> result = re.findall(‘python‘, ‘abc python def python ghi‘) >>> result [‘python‘, ‘python‘] >>> >>> result = re.sub(‘c‘, ‘z‘, ‘click‘, 1) # 使用匹配成功的字符串替换成指定的字符串,参数依次为正则表达式,匹配成功后要去替换的字符串,原字符串,替换次数 >>> result # 返回替换后的字符串 ‘zlick‘ >>> >>> result = re.split(‘a‘, ‘1a2a3a4guyuyun‘) # 将匹配成功的字符串用作字符串分隔符,返回分隔后的字符串列表 >>> result [‘1‘, ‘2‘, ‘3‘, ‘4guyuyun‘] >>>
标签:
原文地址:http://www.cnblogs.com/guyuyun/p/5839881.html