标签:
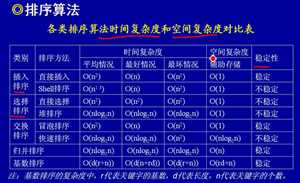
排序算法是计算机技术中最基本的算法,许多复杂算法都会用到排序。尽管各种排序算法都已被封装成库函数供程序员使用,但了解排序算法的思想和原理,对于编写高质量的软件,显得非常重要。
本文介绍了常见的排序算法,从算法思想,复杂度和使用场景等方面做了总结。
2. 几个概念
(1)排序稳定:如果两个数相同,对他们进行的排序结果为他们的相对顺序不变。例如A={1,2,1,2,1}这里排序之后是A = {1,1,1,2,2} 稳定就是排序后第一个1就是排序前的第一个1,第二个1就是排序前第二个1,第三个1就是排序前的第三个1。同理2也是一样。不稳定就是他们的顺序与开始顺序不一致。
(2)原地排序:指不申请多余的空间进行的排序,就是在原来的排序数据中比较和交换的排序。例如快速排序,堆排序等都是原地排序,合并排序,计数排序等不是原地排序。
总体上说,排序算法有两种设计思路,一种是基于比较,另一种不是基于比较。《算法导论》一书给出了这样一个证明:“基于比较的算法的最优时间复杂度是O(N lg N)”。对于基于比较的算法,有三种设计思路,分别为:插入排序,交换排序和选择排序。非基于比较的排序算法时间复杂度为O(lg N),之所以复杂度如此低,是因为它们一般对排序数据有特殊要求。如计数排序要求数据范围不会太大,基数排序要求数据可以分解成多个属性等。
3. 基于比较的排序算法
正如前一节介绍的,基于比较的排序算法有三种设计思路,分别为插入,交换和选择。对于插入排序,主要有直接插入排序,希尔排序;对于交换排序,主要有冒泡排序,快速排序;对于选择排序,主要有简单选择排序,堆排序;其它排序:归并排序。
3.1 插入排序(需要额外空间)
(1) 直接插入排序
特点:稳定排序,原地排序,时间复杂度O(N*N)
思想:将所有待排序数据分成两个序列,一个是有序序列S,另一个是待排序序列U,初始时,S为空,U为所有数据组成的数列,然后依次将U中的数据插到有序序列S中,直到U变为空。
适用场景:当数据已经基本有序时,采用插入排序可以明显减少数据交换和数据移动次数,进而提升排序效率。
(2)希尔排序
特点:非稳定排序,原地排序,时间复杂度O(n^lamda)(1 < lamda < 2), lamda和每次步长选择有关。
思想:增量缩小排序。先将序列按增量划分为元素个数近似的若干组,使用直接插入排序法对每组进行排序,然后不断缩小增量直至为1,最后使用直接插入排序完成排序。
适用场景:因为增量初始值不容易选择,所以该算法不常用。
3.2 交换排序(不需要额外开辟空间)
(1)冒泡排序
特点:稳定排序,原地排序,时间复杂度O(N*N)
思想:将整个序列分为无序和有序两个子序列,不断通过交换较大元素至无序子序列首完成排序。
适用场景:同直接插入排序类似
(2)快速排序(取一个中心点)
特点:不稳定排序,原地排序,时间复杂度O(N*lg N)
思想:不断寻找一个序列的枢轴点,然后分别把小于和大于枢轴点的数据移到枢轴点两边,然后在两边数列中继续这样的操作,直至全部序列排序完成。
适用场景:应用很广泛,差不多各种语言均提供了快排API
3.3 选择排序(不需要额外开辟空间)
(1)简单选择排序
特点:不稳定排序(比如对3 3 2三个数进行排序,第一个3会与2交换),原地排序,时间复杂度O(N*N)
思想:将序列划分为无序和有序两个子序列,寻找无序序列中的最小(大)值和无序序列的首元素交换,有序区扩大一个,循环下去,最终完成全部排序。
所排序序列的记录个数为n。i取1,2,…,n-1,从所有n-i+1个记录(Ri,Ri+1,…,Rn)中找出排序码最小的记录,与第i个记录交换。执行n-1趟 后就完成了记录序列的排序
适用场景:交换少
(2) 堆排序
特点:非稳定排序,原地排序,时间复杂度O(N*lg N)
思想:小顶堆或者大顶堆
适用场景:不如快排广泛
3.4 其它排序
(1) 归并排序
特点:稳定排序,非原地排序,时间复杂度O(N*N)
思想:首先,将整个序列(共N个元素)看成N个有序子序列,然后依次合并相邻的两个子序列,这样一直下去,直至变成一个整体有序的序列。
(2)外部排序
适用场景:外部排序(海量数据,切分M个文件,每个文件进行内排序,取每个文件的第1个数据,初始化堆,把第一个数据放到输出缓冲区,后取文件《上一个已经放到缓冲区数据》中的下一个数据,放到堆中,进行堆排序,再取堆顶的数据放到缓冲区,进行这个递归,直到文件中数据全部清洗完成,并且堆为空<堆最大数量为M>)
4. 非基于比较的排序算法
非基于比较的排序算法主要有三种,分别为:基数排序,桶排序和计数排序。这些算法均是针对特殊数据的,不如要求数据分布均匀,数据偏差不会太大。采用的思想均是内存换时间,因而全是非原地排序。
4.1 基数排序
特点:稳定排序,非原地排序,时间复杂度O(N)
思想:把每个数据看成d个属性组成,依次按照d个属性对数据排序(每轮排序可采用计数排序),复杂度为O(d*N)
适用场景:数据明显有几个关键字或者几个属性组成
4.2 桶排序
特点:稳定排序,非原地排序,时间复杂度O(N)
思想:将数据按大小分到若干个桶(比如链表)里面,每个桶内部采用简单排序算法进行排序。
适用场景:0
4.3 计数排序
特点:稳定排序,非原地排序,时间复杂度O(N)
思想:对每个数据出现次数进行计数(用hash方法计数,最简单的hash是数组!),然后从大到小或者从小到大输出每个数据。
使用场景:比基数排序和桶排序广泛得多。
5. 总结
对于基于比较的排序算法,大部分简单排序(直接插入排序,选择排序和冒泡排序)都是稳定排序,选择排序除外;大部分高级排序(除简单排序以外的)都是不稳定排序,归并排序除外,但归并排序需要额外的存储空间。对于非基于比较的排序算法,它们都对数据规律有特殊要求 ,且采用了内存换时间的思想。排序算法如此之多,往往需要根据实际应用选择最适合的排序算法。
标签:
原文地址:http://www.cnblogs.com/guxuanqing/p/5839963.html