标签:
参考文章:https://swlaschin.gitbooks.io/fsharpforfunandprofit/content/posts/fvsc-download.html
参考的文章教了我们如果在F#里利用.Net的库来下载一个网页,这里,我来发散一下,把它弄成一个可以用来帮助写爬虫的基础库。
首先,下载的代码我做了几处修改:
1、去掉了回调,直接改成了保存文本到文件,注意如果是下载图片不能这样写。
2、用流来一步步调用.Net的库,并且加上了异常处理。
3、增加了一个async的异步方法,这和C#的async、await是一样的。
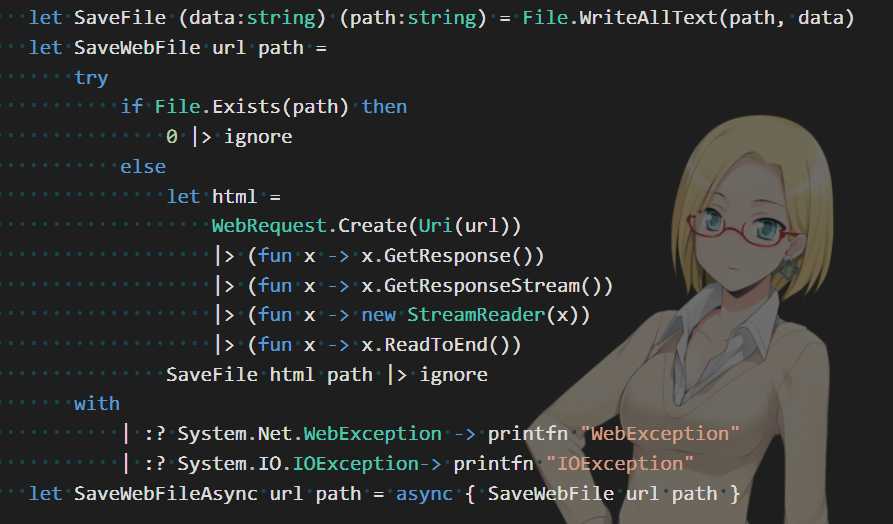
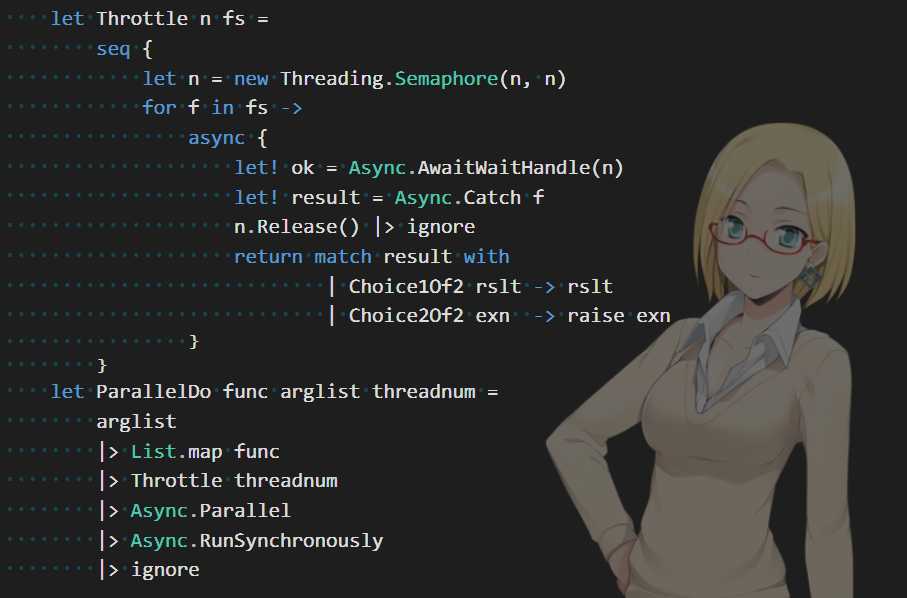
接下来,有了async,自然是要让这个下载操作能够并发了,辅助并发的基础函数是这样的:
1、在stackoverflow上找了一个Throttle辅助函数,可以用来控制并发数,很赞。
2、用流和Async.Parallel实现了并发。
标签:
原文地址:http://www.cnblogs.com/zapline/p/5841669.html