标签:
作为DBA,时不时会遇到将数据导入到数据库的情况,假设业务或研发提供一个包含上百万行INSERT语句的脚本文件,而且这些INSERT 语句没有使用GO来进行批处理拆分,那么直接使用SQLCMD来执行会发现该进程消耗大量物理内存并迟迟没有数据写入,即使脚本中每一行都添加了GO,你依然会发现这插入效率太差,让你无法忍受,怎么搞呢,下面小代码帮你折腾下:
$old_file_path= ‘C:\insert_scripts.sql‘ $new_file_path=‘C:\insert_scripts_new.sql‘ $tran_rows=50 $line_content=" SET NOCOUNT ON GO BEGIN TRAN BEGIN TRY " $line_content |Out-File $new_file_path $line_num=1 $sr1=[IO.StreamReader]$old_file_path $line_content="" while(-not $sr1.EndOfStream) { $tmp_content= $sr1.ReadLine() $line_content=$line_content+"`r"+$tmp_content $line_num_mode =$line_num % $tran_rows if($line_num_mode -eq 0) { $line_content=$line_content+" COMMIT PRINT ‘执行第"+($line_num-$tran_rows)+"行到第"+($line_num)+"行成功‘ END TRY BEGIN CATCH ROLLBACK PRINT ‘执行第"+($line_num-$tran_rows)+"行到第"+($line_num)+"行失败‘ END CATCH GO BEGIN TRAN BEGIN TRY " $line_content | Out-File -Append $new_file_path Write-Host "处理到行" $line_num $line_content="" } $line_num=$line_num+1 } $line_content=$line_content+" COMMIT PRINT ‘执行第"+($line_num-$tran_rows)+"行到第"+($line_num)+"行完成‘ END TRY BEGIN CATCH ROLLBACK PRINT ‘执行第"+($line_num-$tran_rows)+"行到第"+($line_num)+"行失败‘ END CATCH GO " $line_content | Out-File -Append $new_file_path $sr1.Close()
还是看点疗效吧,原始SQL为:

经过此脚本修改过的变为:
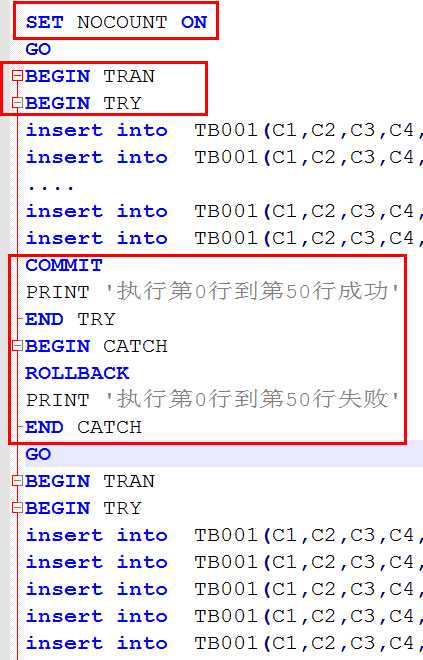
这样实现有以下有点:
1. 使用“SET NOCOUNT ON”来屏蔽每条语句返回影响行数,减少与cmd窗口交互的次数;
2. 将每50条语句拆分到一个批处理中,降低数据库进行语法检查分析的消耗,在封装到一个事务中进行提交,减少写日志的次数;
3. 打印输出事务执行结果,方便排查错误(可修改代码只输出执行失败的事务)
执行结果截图:
====================================================
在个人电脑测试,以100条一个事务来拆分,大概1分钟可以导入50万到60万,按不同的行数进行拆分插入效率不同,具体合适的拆分行数需要根据实际情况测试为准。
对于超大数据量的导入,还是推荐使用csv+bcp的方式来导入,INSERT+SQLCMD的效率始终太低太低!
====================================================
没啥技术含量,厚脸拿出来分享,只是因为很久没写博客啦!

标签:
原文地址:http://www.cnblogs.com/TeyGao/p/5849989.html