标签:
import urllib.request response = urllib.request.urlopen("http://www.baidu.com") html = response.read() html = html.decode(‘UTF-8‘) print(html)
其中用 用urllib.request 中的urlopen打开百度(一定要加http,用read方法读取html代码,用 utf—8 解码。
其中,response对象有一个getcode()方法,可以得到HTTP状态码(200为成功
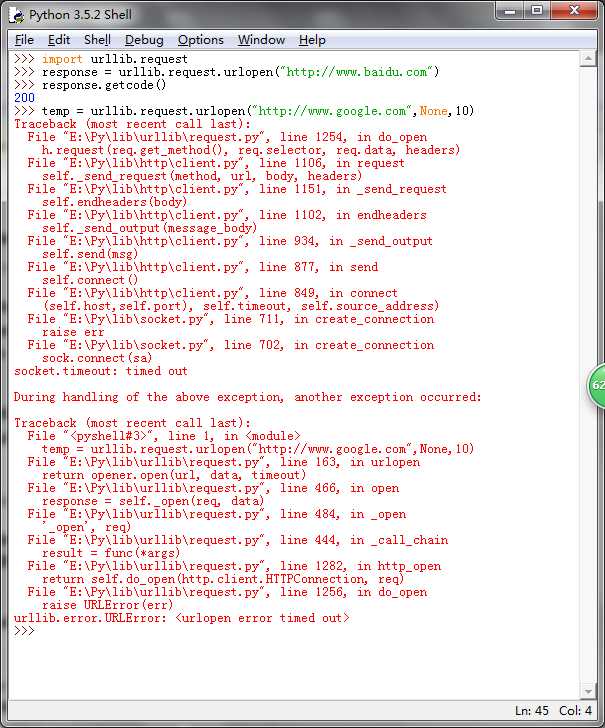
其中baidu能够正常访问,google访问超时,其中传入的三个参数:URL,向服务器发送的数据(没有为None,也可缺省),超时时间
返回的异常最后一句,timed out
标签:
原文地址:http://www.cnblogs.com/Kurokey/p/5856267.html