For those who want to get right to the good stuff, the installation instructions are below. This is a modification of Google DeepMind’s code: instead of training a computer to play classic Atari games, you train it to play Super Mario Bros.
1. On a linux-like system, execute the following steps:
sudo apt-get install git
git clone https://github.com/ehrenbrav/DeepQNetwork.git
cd DeepQNetwork
sudo ./install_dependencies.sh
This will grab the necessary dependencies, along with the emulator to run Super Mario Bros. Note that if you want to run training and testing on your CUDA-equipped GPU, you’ll need to install the appropriate CUDA toolkit. If you’ve done this and the script doesn’t automatically install cutorch and cunn (it looks for the presence of the Nvidia CUDA Compiler NVCC which might not be installed on Debian systems for example), uncomment the lines at the end of the script and try again.
2. Obtain the ROM for the original Super Mario Bros. from somewhere on the internet, place it in the DeepQNetwork/roms directory, and call it “smb.zip”.
3. Run the following to start the training from DeepQNetwork/ (assuming you have a CUDA-friendly GPU – if not, run the “train_cpu.sh” instead:
./train_gpu.sh smb
Watch Mario bounce around at random at first, and slowly start to master the level! This will run for a very long time – I suggest you at least let it get through 4 million training steps in order to really see some improvement. The progress is logged in the logs directory in case you want to compare results while tweaking the parameters. Once you run out of patience, hit Control-C to terminate it. The neural network is saved in the dqn/ directory with a *.t7 filename. Move this somewhere safe if you want to save it, because it is overwritten each time you train.
If you want to watch the computer play the network you trained, execute the following (again, use the “_cpu” script if you don’t have a compatible GPU):
./test_gpu.sh smb <full-path-to-the-saved-file>
To help get you started, I posted my network trained through about 4 million steps here (over 1GB) – if you want to start with this to just see how it works, or use it as a jumping-off point for your own training so you don’t need to start from scratch, use this by uncommenting the saved_network line in the train script and specifying the complete path to this file.
Background
Earlier this year I happened upon Seth Bling’s fantastic video about training a computer to play Super Mario Bros. Seth used a genetic algorithm approach, described in this paper, which yielded impressive performance. It was fun to get this working and see Mario improve over the span of a couple of hours to the point where he was just tooling the level! The approach Seth used, however, was almost 15 years old and I started wondering what a more modern approach would look like…
Around the same time, I happened upon this video about the Google DeepMind project to train a computer to play a set of classic Atari games (see especially around 10:00). Now this was something! DeepMind used a process that they called a Deep Q Network to master a host of different Atari games. What was interesting about this approach was (i) they only used the pixels and the score as inputs to the network and (ii) they used the same algorithm and parameters on each game. This gets closer to the mythical Universal Algorithm: one single process that can be successfully applied to numerous tasks, almost like how the human mind can be trained to master varied challenges, using only our five senses as inputs. I read DeepMind’s paper in Nature, grabbed their code, and got it running on my machine.
What I especially liked about Google’s reinforcement learning approach is that the machine really doesn’t need to know anything about the task it’s learning – it could be flipping burgers or driving cars or flying rockets. All that really matters are the pixels it sees, the actions it can take at any moment in time, and the rewards/penalties it receives as a consequence of taking those actions. Seth’s code tells the machine: (i) which pixels in the game were nothing, (ii) which were enemies, and (iii) which parts Mario could stand on. He did this by reading off this information from the game’s memory. The number he programmed Mario to optimize was simply how far (and how fast) Mario moved to the right.
What was most exciting to me was unifying these two approaches. Why not use a Deep Q Network to learn to play Super Mario Bros. – a more complex game than the arcade-style Atari titles… Seth called his approach MarI/O, so you can might this version Deep-Q MarI/O.
How It Works
The Google Atari project, like many other machine learning efforts in academia, used something called theArcade Learning Environment (ALE) to train and test their models. This is an emulator that lets you programmatically run and control Atari games from the comfort of your own computer (or the cloud). So my first task was to create the same sort of thing for Super Mario Bros.
I started with the open source FCEUX emulator for the Nintendo Entertainment System, and ported the ALE code to use FCEUX instead. The code for that is here (though I didn’t implement parts of the ALE interface that I didn’t need). Please reuse this for your own machine learning experiments!
I then modified DeepMind’s code to run Super Mario Bros using this emulator. The first results were…rather disappointing. Super Mario Bros. is just way more complex than most Atari games, and often the rewards for an action come quite a bit of time after the action actually happens, which is a notorious problem for reinforcement learning.
Little by little, over the course of several months and probably a couple solid weeks of machine time, I modified the parameters to get something that worked. But even then, Mario would often just kind of stand around without moving.
To correct this, I decided to give him a reward for moving to the right and a penalty for moving to the left. I didn’t originally want to do this since it seems to detract from the purity of using just the score to calculate rewards, but I justified it by thinking about how humans actually play the game… When you first pick up Super Mario Bros, you basically just try to get as far as possible without dying. Score seemed to be almost an afterthought; something you care about after mastering the game. So it definitely is not quite as pure as DeepMind’s approach here because it does get into some unique aspects of the game, but I think it better matches how a human would play. Once I made this change, things started to improve.
The second issue I noticed was that Mario seemed to have a blithe disregard for his own safety – he would happily run right into Goombas again and again…and again…and again. So I added a penalty for dying, also justifying this by saying that this is how a person would actually play.
With these modifications, I spent extensive time tuning the parameters to improve performance. I noticed a few things. First, there would often be an initial peak after a relatively small number of steps, and then scores would decline steadily with further training. I think this might be related to my increasing the size of the one of the higher levels of the neural network (which handle the more abstract behaviors): the downside to this additional expressive power is overfitting, which could have contributed to that early spike and then steady decline with more training…
The second issue I noticed was that there seemed to be little connection between the network’s confidence in its actions and its actual score. I came across another recent paper on something called Double Q Learning, also courtesy of DeepMind, which substantially improved Google’s original results. Double Q Learning counters the tendency for Q networks to become overconfident in their predictions. I changed Google’s original Deep Q Network to a Double Deep Q Network, and that helped substantially.
Finally, the biggest improvement of all came when I was just more patient. Even running on a powerful machine with a Nvidia 980 GPU, the emulator could only go so fast. As a consequence, one million training steps took about an entire day, with quite a bit of variance in the scores along the way.
Changes to Google’s Code
So here’s a summary of my changes from Google’s Atari Project:
- Changed the Deep Q Nework into a Double Deep Q Network.
- Ported the Atari Learning Environment to Nintendo using the FCEUX emulator.
- Granted rewards equal to points obtained per step, plus a reward for moving to the right minus a penalty for moving to the left.
- Implemented a penalty for dying.
- Clipped the rewards to +/- 10,000 per step.
- Scaled the rewards to [-1,1].
- Doubled the action repeat amount (the number of frames an action is repeated) to 8. I did this because the pace of Super Mario Bros. can be quite a bit slower than many Atari games. Without this, Mario seems a bit hyperactive and in the beginning just jumps around like crazy without going anywhere.
- Increased the size of the third convolutional layer from 64 to 128. This was an attempt to deal with the increased complexity of Super Mario Bros. but definitely slows things down and I’m sure risks overfitting.
How Deep Q Learning Works
Since I was starting from scratch, it took me quite a bit of time to understand reinforcement learning. I thought I’d try to explain it here in layman’s terms, since this sort of explanation would have really helped me when I embarked on this project.
The idea behind reinforcement learning is you allow the machine (or “agent” in the machine learning lingo) to experiment with playing different moves, while the environment provides rewards and penalties. The agent doesn’t know anything about the underlying task and starts out simply doing random stuff and observing the rewards and punishments it receives. Given enough time, so long as the rewards aren’t random, the agent will develop a strategy (called a “policy”) for maximizing its score. This is “unsupervised” learning because the human doesn’t provide any guidance at all beyond setting up the environment – the machine must figure things out on its own.
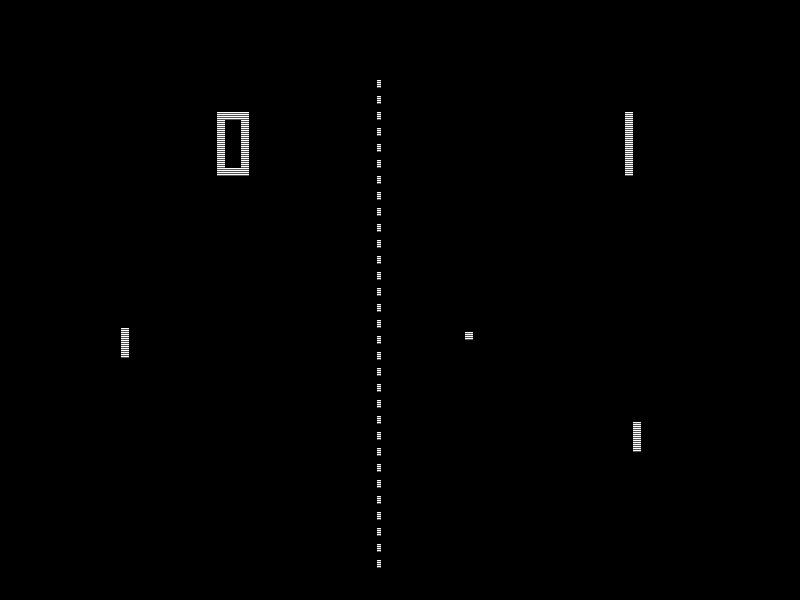
Which way is the ball going? We can’t tell looking at just one frame.
Our goal is a magical black box that, when you input the current state of the game, it will provide an estimate of the value of each possible move (up, down, right, left, jump, fire, and combinations of these). It then plays the best one. Games like Super Mario Bros. and many Atari games require you to look at more than a single frame to figure out what is going on – you need to be able to see the immediate history. Imagine looking at a single frame of Pong – you can see the ball and the paddles, but you have no idea which direction the ball is traveling! The same is true for Super Mario Bros., so you need to input the past couple of frames into our black box to allow it to provide a meaningful recommendation. Thus in our case, a “state” actually comprises the frame that is currently being shown on the screen plus three frames from the recent past – that is the input to the black box.
In mathematical terms, our black box is a function Q(s, a). Yes, a really, really big nasty complicated function, but a function nonetheless. It takes this input (the state s) and spits out an output (an estimate of the value of each possible move, each of these called an “action” a). This is a perfect job for a neural network, which at its heart is just a fancy way of approximating an arbitrary function.
In the past, reinforcement learning used a big matrix called a transition table instead of a neural network, which kept track of every possible transition for every possible state of the game. This works great for tasks like figuring out your way through a maze, but fails dramatically with more complex challenges. Given that the input to our model is four grayscale 84×84 images, there are a truly gigantic number of different states. There are 15 possible moves (including combinations of moves) in Super Mario Bros., meaning that each of these states would need to keep track of the transitions to all other possible states, which rapidly becomes utterly intractable. What we need is a way to generalize the states – a Goomba on the right of the screen is the same thing as a Goomba on the left, only in a different position and can be represented far more efficiently than specifying every single pixel on the screen.
Over the past few years, one of the hottest topics in computer science is the use of a type of neural network called a “deep convolutional network“. This type of network was inspired by the study of the animal visual cortex – our minds have a fantastic ability to generalize what our eyes see, and recognize shapes and colors regardless of where they appear in our field of view. Convolutional neural networks work well for visual problems since they are robust against translation. In other words, they’ll recognize the same shape no matter where it appears on the screen.
The networks are called “deep” because they incorporate many layers of interconnected nodes. The lowest layers learn to recognize very low-level features of an image such as edges, and each successive layer learns more abstract things like shapes and, eventually, Goombas. Thus the higher up you go in the network, the greater the level of abstraction that layer learns to recognize.
Each layer consists of a bunch of individual “neurons” connected to adjacent layers and each neural connection has a numeric weight associated with it – these weights are really the heart of the network and ultimately control its output. So if a given neuron has enough inputs that fire and, when multiplied by their respective weights, the result is high enough, that neuron itself fires and the neurons that are connected to it from above receive its signal. Together, this set of weights that define our neural network is called theta (θ).
For this project, I used a the following neural network, adapted from Google’s code:
- Input: Eight 84×84 grayscale frames;
- First Layer (convolutional): 32 8×8 kernels with a stride of 4 pixels, followed by a rectifier non-linearity;
- Second Layer (convolutional): 64 4×4 kernels with a stride of 2 pixels, followed by a rectifier non-linearity;
- Third Layer (convolutional): 128 3×3 kernels with a stride of 1 pixel, followed by a rectifier non-linearity;
- Fourth Layer (fully-connected): 512 rectifier units;
- Output: Values for the 15 possible moves.
Armed with this neural network to approximate the function I described above using weights θ (written Q(s,a;θ)), we can start attacking the problem. In classic “supervised” learning tasks, the human trains the machine by showing it examples, each with its own label. This is how, for example, theImageNet competition for classifying images works: the learning algorithms are given large set of images, each categorized by humans into one of 200 categories (baby bed, dragonfly, spatula, etc.). The machines are trained on these and then set loose on pictures whose categories are hidden to see how well they do. But the issue with supervised learning is that you need someone to actually do all the labeling. In our case, you would need to label the best move in countless different scenarios within the game, which isn’t going to fly… Thus we need to let the machine figure it out on its own.
So how would a human approach learning Super Mario Bros? Well, you’d start by trying out a bunch of buttons. Once you figure out some moves in the game that kind of work, you start to play these. The risk here is that you learn a particular way of playing, and then you get stuck in a rut until you can convince yourself to start experimenting again. In computer science terms, this is known as the Explore/Exploit Dilemma: how much of your time should be spent exploring for new strategies versus exploiting those that you already know work. If you spend all of your time exploring, you don’t rack up the points. If you only exploit, you’re likely to get caught in a rut (in the language of computer science, a local minimum).
In Deep Q Learning, this is captured in a parameter called epsilon (ε): it’s simply the chance that, instead of playing the move recommended by the neural network, you play a random move instead. When the game starts, this is set to 100%. As time goes on and you accumulate experience, this number should slowly ramp down. How fast it ramps down is a key parameter in Deep Q Learning. Try tweaking this parameter and see what difference it makes.
Thus when it comes time for Mario to pick a move, he inputs the current state at time t (called st) into the Q-function and then selects the action at that time (at) that yields the highest value. In mathematical terms, the action Mario selects is:
at = maxaQ(s, a; θ)
There is also the probability ε that instead of playing this action, he’ll select a random action instead.
So how does the learning actually work? The Q function starts out with randomly assigned weights, so somehow these weights need to be modified to allow Mario to learn. Each time a move is played, the computer stores several things: the state of the game before the move at time t, the move played a, the state of the game after the move st+1, and the reward earned r. Each of these is called an experience and all of them together are called the replay memory. As Mario plays, every couple of moves he picks a couple of these experiences at random from the replay memory and uses them to improve the accuracy of his network (this was one of Google’s innovations).
This is the central algorithm of Q-learning: given a state at time t (called st, and remember a state includes the past few frames of gameplay), the value of each possible move is equal to the reward (r) we expect from that move plus the discounted value of the best possible move in the resulting state (st+1). The reason the value of the future state is discounted by a quantity called gamma (γ) is because future rewards should not be valued as highly as immediate rewards. If we set gamma to one, the machine treats rewards far into the future equally as a reward right now. Setting gamma low makes your computer into a pleasure-seeking hedonist, maxing out immediate rewards without regard to potentially bigger rewards in the future. In mathematical terms, the reward of making a move a at state st is expressed as:
r + γmaxaS(st+1, a; θ)
This gives us a way of estimating the value of making a move a at state st. For each learning step, the machine compares its estimate of this with the actual future rewards observed through experience. The weights of the neural network are then tweaked to bring the two into closer alignment using an algorithm called stochastic gradient descent.
The rate at which the network changes its weights is called the learning rate. At first, a high learning rate sounds fantastic for those of us who are impatient, since faster learning is best, right? The problem here is that the network could bounce around between different strategies without ever really settling down, kind of like a dieter following the latest fad without ever really following through a regimen far enough to see results.
As you iterate through enough experiences, hopefully the network learns how to play. By observing enough of these state-action-result memories, we hope that the machine will start to link these together into a general strategy that can handle both short- and long-term goals. That’s the goal at least!
What all this stuff means in practice is that you have a large number of levers to play with. That’s both the fascinating and infuriating thing about machine learning, since you can endlessly tweak these parameters in hopes of getting better results. But each run of the network takes a long time – there’s just so much number crunching to do, even with the rate of play sped up as fast as possible. GPUs help a lot since they can do tons of linear algebra calculations in parallel, but even so there’s only so fast you can go with commonly available hardware. With this project, I tried running it in the cloud using AWS but, even with one of the more powerful instances available, my home machine was faster. And since you pay by the hour with AWS, it quickly became obvious that it would be cheaper just to by more powerful gear for my home computer. If you are Google or Microsoft and have access to near limitless processing power, I’m sure you can do better. But for the average amateur hacker, you just have to be patient!
Conclusion
So those are the basics of Q learning. Please tweak the code and parameters to see if you can improve on my results – I would be very interested to hear!