标签:
同样参照网上教程,同时把会的不多的html标签又复习了一下
同时安利一个网站,我唯一加入过的一个社团官网(web开发协会
前任会长是属于大牛级的存在,目前网站已多次重构,花生太神辣。
好了,于是用这个网站做了下练习
import re import urllib.request import urllib from collections import deque queue = deque() visited = set() url = ‘http://www.nutjs.com/‘ # 初始抓取网站 queue.append(url) cnt = 0 #抓取网页计数器 while queue: #队列循环bfs抓取 url = queue.popleft() visited |= {url} #去重,防止重复抓取 print(‘正在抓取:‘+ url) cnt+=1 urlop = urllib.request.urlopen(url) if ‘html‘ not in urlop.getheader(‘Content-Type‘): continue #过滤出合法所需的文本 try: data = urlop.read().decode(‘utf-8‘) except: continue linkre = re.compile(‘href=\"(.+?)\"‘) for x in linkre.findall(data): # print(x) if ‘http‘ in x and x not in visited: queue.append(x)
运行效果如下:
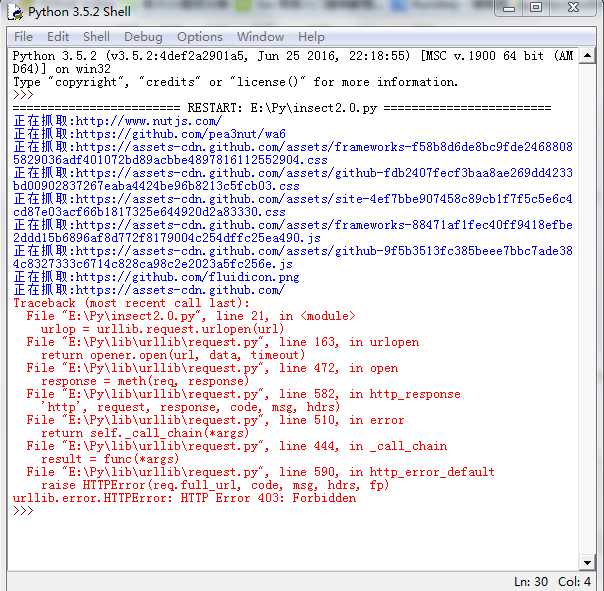
标签:
原文地址:http://www.cnblogs.com/Kurokey/p/5864494.html