标签:
今天是我们学习数据的相关的知识第二天。
在mysql中,数据的主要类型主要分三种:
数字型,字符型,时间型
数据类型的主要作用就是在开创一个数据表的时候来设定字段的类型。
数字型:
1.整数型:tinyint,smallint,mediumint,int,bigint
2.浮点型:浮点 float,double
定点 decimal
字符型:
set,enum,blob,text,varchar,char
时间型:
year, timestam,time,date,datetime
整数类型的字段设置
主要有:tinyint,smallint,mediumint,bigint
整数类型所占的空间:
int:占四个字节,即32位
tinyint:占一个字节,即8位,最多能存储256个数字
bigint:占8个字节,64位
1.整数类型字段的设定形式:
类型名[M][unsigned][zerofill]
说明:
1.m表示设定该整数的显示长度,即输出的时候,如果m为6,可能显示为000123.
2.unsigned用于设定该整数位无符号数,其实就是没有负数。
3.zerofill用于设定是否填充‘0’到一个数字的左边,此时,需要与m配合使用
4.如果设置了zerofill,则自动也就表示同时具备了unsigned修饰。
2.小数类型
float,double,decimal
float:单精度浮点型,其精度大约只有6--7位有效数字
double:双精度浮点型,其精度大约有15位有效数字。
decimal:定点小数类型,整数部分最长可以有65位,小数最多可以有30位,一般设置格式为:decimal(总位数,小数位数)



mysql中的字符串,应该使用“单引号”引起来。
字符串类型主要有:char,varchar,enum,set,text,binary,varbinary,blob
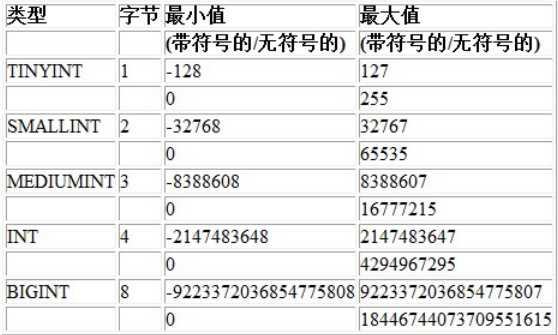
varchar类型:变长字符串,使用是我们必须设定长度,最大长度是65535个,字符编码不同,也有可能会更少,这里的储存限制,其实都是来源一个表格的一行的数据储存最大容量限制:65535.
char类型:定长字符串;使用时通常需要设定其长度,如果不设定,默认为1,最大理论长度为255个,定长字符串都是适合存储数据都是可以明确固钉长度的字符,比如手机号,中国邮编等,实际存储时,如果少于设定长度,但是都会补满填空。
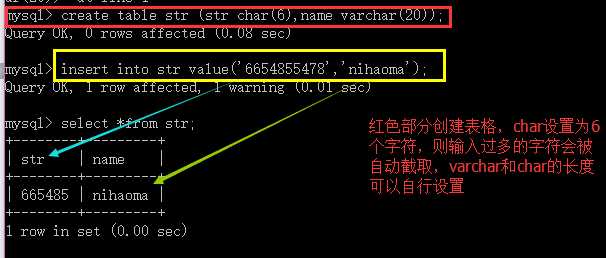
enum类型:单选项字符串数据类型。比较适合存储表单界面中的单选项,在设定的时候需要给定固定 的几个选项,然后存储的时候值存储一个值:
enum(“选项1”,“选项2”,“选项3”......)
实际内部对应的是数字值:1,2,3,4,5,6......最多65535项;
写入形式也可以选用字符串本身,也可以用对应的数组;
set类型:多选项字符串数据类型。它适合存储表单界面的多选项,用法与enum相同:
set(“选项1”,“选项2”,“选项3”......)
这些字符串选择对应的数字下标是:1,2,4,8,16.....最多64个选项。
写入形式可以用该选项字符串并用逗号隔开,也可以用对应数字的和。

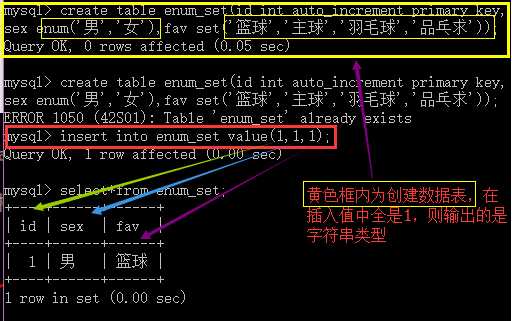
text类型:长文本字符类型,其中存储的数据不占表格中的数据容量限制。可以存储65535个字符,其他同类型的有:smalltext,tinytext,longtext.
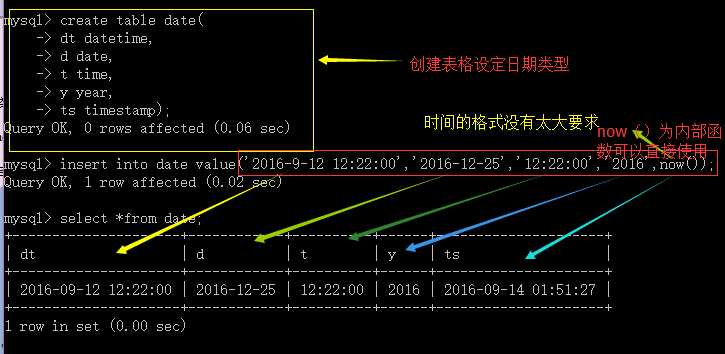
时间类型的设置有以下几类:
datetime类型:时间日期类型
date:日期类型
time:时间类型
year:年份类型
timestamp:时间戳,相当于now()
常用时间类型的在我们自己给定的数据下,需要使用单引号引起来,跟字符串一样。
创建表格的语法有:
create table 【if not exists】 表名 (字段列表 【,索引或约束列表】) 【表选项列表】;
或:
create table 【if not exists】 表名 (字段1, 字段2, .... 【,索引1, 索引2, ....,约束1,约束2,.... 】) 【表选项1, 表选项2,.... 】
字段的设定形式:
字段名 类型 【字段属性1 字段属性2】
字段类型我们已经在上一节讲过了,今天我们主要讲一下字段的属性;
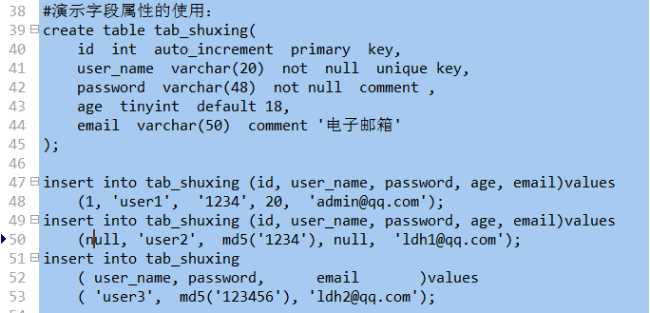
auto_increment:只用于整数类型,让该字段的值自动增长,通常是一个表的第一个字段,并且是当做主键 primary key;
primary key:用于设定该字段为主键,此时字段的值就可以唯一确定一行数据;
unique key:设定该字段是唯一的,不能重复
not null:用于设定该字段不能为空,如果不设定默认可以为空;
default :用于设定该字段的默认值;
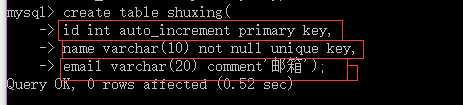
comment ‘字段说明’;
如图:
索引
什么是索引: 索引就是系统内部自动维护的隐藏数据表,它的作用就是可以极大 的加快数据的查找。
所谓的建立索引,其实就是制定的一个表的某个或者某些字段作为“索引数据字段”就可以了,形式为:
普通索引: key(字段名)
就是一个索引而已,就是可以加快查找速度
唯一索引: unique key(字段名)
是一个索引,而且还可以设定其字段的值不能重复;
主键索引: primary key(字段名)
是一个索引,而且还具有区分该表中的任何一行数据的作用,主键不能为空。
全文索引: fulltext(字段名)
外键索引: foreign(字段名)references 其他表(对应其他表中的字段名)
索引创建的方法:

外键索引:
形式:foreign key(字段名) references 其他表(字段)
外键的定义:就是指设定某个表的某个字段,它的数据的值,必须是另一个表中的某一个字段;
· 
约束:
约束的定义:就是要求数据需要满足什么条件的一种规定
主要有以下几种约束:
主键约束:primary key(字段名)
使该字段的值可以用于唯一确定一行数据,其实就是主键的意思;
唯一约束:unique key(字段名)
使该字段的值具有唯一性,可以更好的区分;
外键约束:foreign key(字段名) references 表名(字段名)
使该设定字段的值,必须在其定的对应表中的字段中已经有的值;
非空约束:not null
设定一个字段时写的那个notnull属性
默认约束:default 值
就是设置字段上的那个属性
检查约束: check (某种判断语句)
其实,主键约束,唯一约束,外键约束,和索引没有差别就是同一件事的不同角度的说法。
选项列表
选项列表就是 在创建一个表的时候,对该表的整体设定:
charset = 要使用的字符编码;
engine = 要使用的存储引擎;
auto_increment= 设定当前表的自增长字段的初始值,默认为1;
comment = ‘说明文字’
说明:
1,设定的字符编码是为了跟数据库设定的不一样。如果一样,就不需要设定了:因为其会自动使用数据库级别的设定;
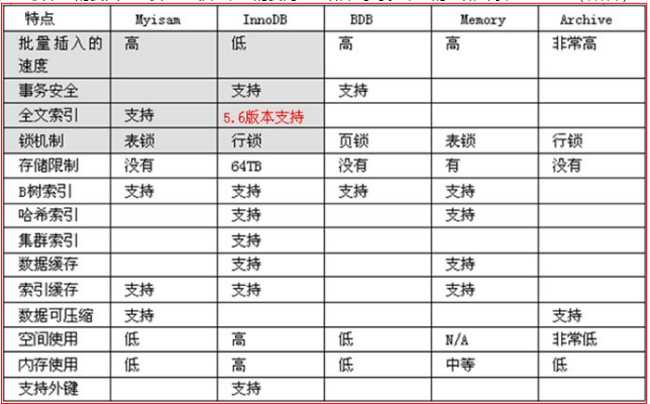
2,engine(存储引擎)在代码层面,就是一个名词:InnoDB, MyIsam, BDB, archive, Memory。默认是InnoDB。
什么叫做存储引擎?
存储引擎是将数据存储到硬盘的“机制”。其实,也就几种机制(如上名字所述);不同的存储引擎,其实主要是从2个大的层面来设计存储机制:
1,尽可能快的速度;
2,尽可能多的功能;
选择不同的存储引擎,就是上述性能和功能的“权衡”。
大体如下:
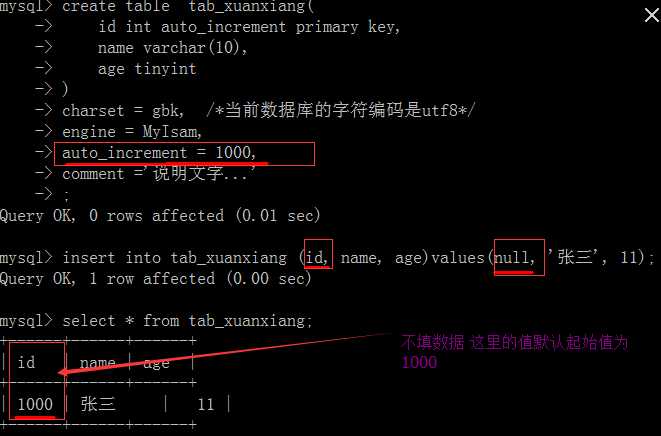
几点说明:
修改表指修改表的格式;
创建表能做到的事修改表几乎都能做到————比较不推荐修改表
可以对字段进行操作也可以对索引进行操作
表的选项,通常是修改 即使不谢任何表选项,他们都是默认值。
修改表的语句比较多这里不进行详解一下是比较常见的几个:
添加字段:alter table 表名 add [column] 新字段名 字段类型 [字段属性列表];
修改字段(并可改名):alter table 表名 change [column] 旧字段名 新字段名 新字段类型 [新字段属性列表];
删除字段:alter table 表名 drop [column] 字段名;
添加普通索引:alter table 表名 add key [索引名] (字段名1[,字段名2,...]);
添加唯一索引(约束):alter table 表名 add unique key (字段名1[,字段名2,...]);
添加主键索引(约束):alter table 表名 add primary key (字段名1[,字段名2,...]);
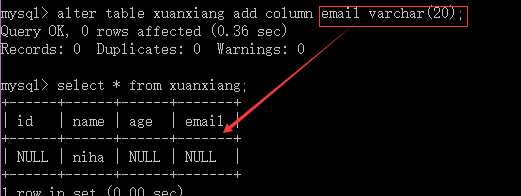
drop table if exists 表名;
显示当前数据库中的所有表: show tables;
显示某表的结构: desc 表名; 或:describe 表名;
显示某表的创建语句:show create table 表名;
重命名表:rename table 旧表名 to 新表名;
从已有表复制表结构:create table [if not exists] 新表名 like 原表名;
就是一个select语句,我们给其中一个名字(视图名),以后,要使用(执行)该select语句就方便了:用该视图就可以了
create view 视图名【(字段1,字段2,字段3.....)】 as select
距离:create view v as
select id,fl,name,age,email from 表1 where id>7 and id<100

基本上就可以当做一个表来用了:
drop view 【if exists】 视图名;
标签:
原文地址:http://www.cnblogs.com/pzp-fire/p/5870427.html