标签:
本文的配置环境是VMware10+centos2.5。
在学习大数据过程中,首先是要搭建环境,通过实验,在这里简短粘贴书写关于自己搭建大数据伪分布式环境的经验。
如果感觉有问题,欢迎咨询评论。
一:伪分布式准备工作
1.规划目录

2.修改目录所有者和所属组

3.删除原有的jdk

4.上传需要的jdk包
5.增加jdk 的执行权限
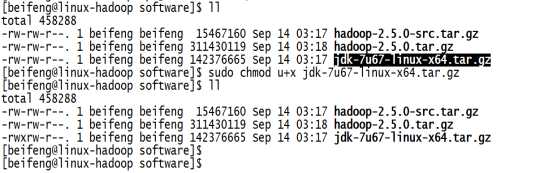
6.解压jdk

7.修改profile的JAVA_HOME,PATH

8.切换至root用户,使文件生效

9.检验jdk是否成功

二:搭建为分布式
1.解压hadoop
2.进入hadoop主目录

3.获取JAVA_HOME的目录

4.修改hadoop-env.sh的JAVA_HOME

5.修改mapred-env.h的JAVA_HOME

6.修改yarn-env.sh的JAVA_HOME

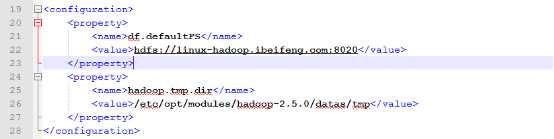
7.配置core-site.xml
8.修改slave的配置

9.修改hdfs.site.xml

10.检验hdfs

11.格式化hdfs


12.启动namenode 以及datanode进程
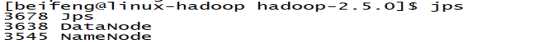
13.查看浏览器,方便管理HDFS
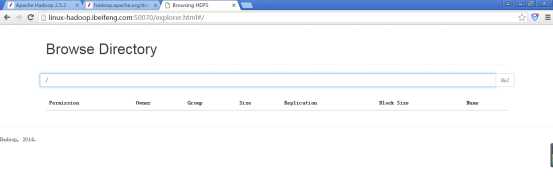
14.在HDFS上新建文件夹

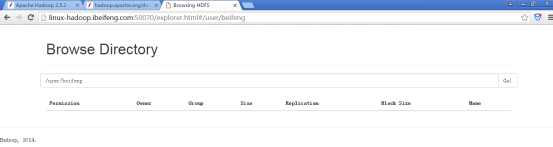
15.在HDFS上上传文件

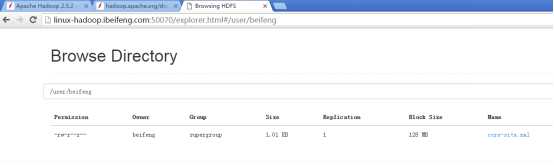
16.在HDFS上读取wenjian
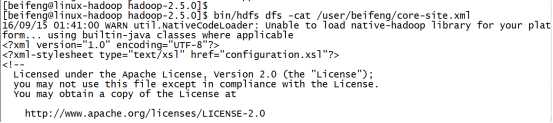
17.在HDFS上下载文件到本地

18.配置yarn-site.xml
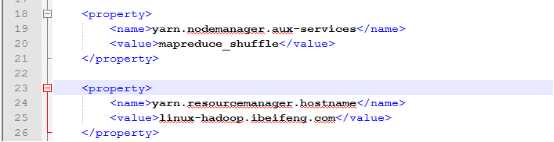
19.启动resourcemanager与nodemanager

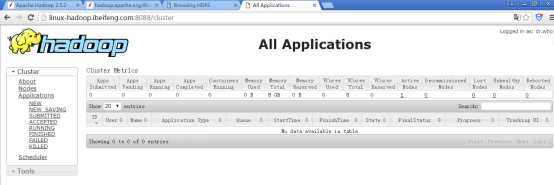
20.在浏览器上运行yarn,方便管理
21..新建将要测试的文件
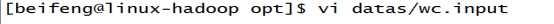

22.在HDFS上新建文件目录

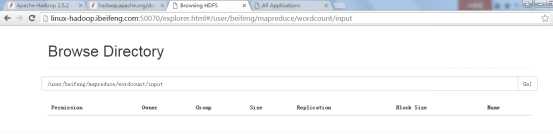
23.上传本地的wc.input文件进刚刚新建的目录


24.在yarn上运行计算

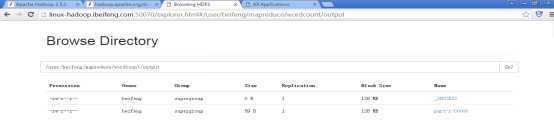
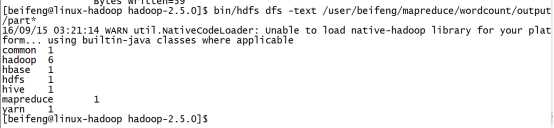
25.查看结果
三:细节
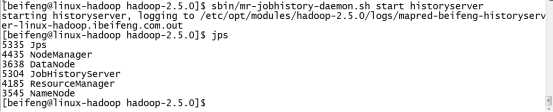
1.配置历史服务器,修改mapred-xite.xml
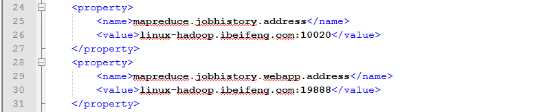
2.启动服务器
标签:
原文地址:http://www.cnblogs.com/juncaoit/p/5874568.html