标签:
可见性: 一个线程对共享变量的修改,能够及时被其它线程看到
共享变量: 如果一个变量在多个线程的工作内存中都存在副本,那么这个变量就是这几个线程的共享变量
Java内存模型(JMM): 描述了Java程序中各种线程共享变量的访问规则,以及在JVM中将线程共享变量存储到内存和从内存中读取出线程共享变量这样的底层细节
上面这些规则都是针对线程的共享变量的,JMM的细节会在以后的博客里面写。 本篇只需要知道
下面使用一张图来表示主内存,工作内存(也叫做本地内存),线程,共享变量之间的关系
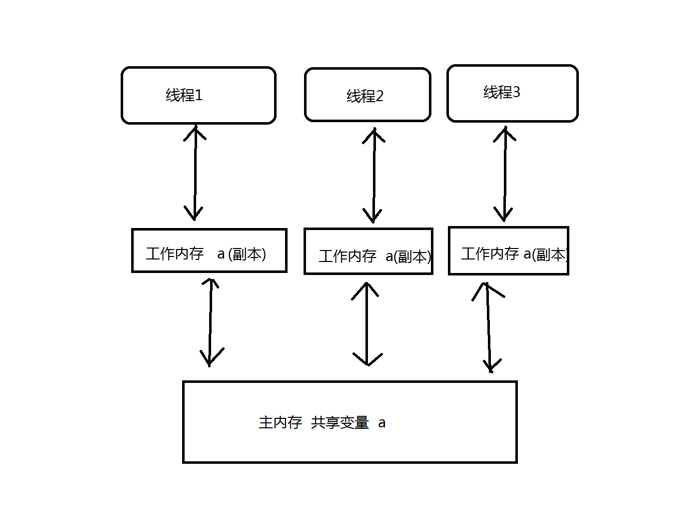
由上图可知:
1 每个线程都有自己的工作线程
2 每个线程只能操作自己的工作内存,不能直接操作主内存
3 每个线程都有一个主内存中的变量a的一个副本,所以,变量a就叫做这三个线程的共享变量
在讲变量在内存中的可见性之前,先看下JMM(JAVA内存模型)中的两条规定
1 线程对共享变量的所有的操作都必须在自己的工作内存中进行,不能直接从主内存中读写
2 不同线程之间无法直接访问其它线程工作内存中的变量,线程间变量的传递需要通过主内存来完成
这两条规定也可以从上面的图中可以看出来。
共享变量可见性实现的原理
问:线程1对共享变量的修改如何被线程2及时的看到? 主要经过以下2个步骤
经过了上面两个步骤后,线程1对共享变量的修改,及时的更新到主内存中
线程2将主内存中的最新的共享变量的值,刷新到自己的工作内存中
线程1 和 线程2 中,a的值就一样了,都是最新的,这时候就说共享变量a在线程1和线程2中是可见的。
由于上面的JMM的两条规定,线程都是在自己的工作线程中操作变量,线程不能直接和主内存进行交互,线程之间必须通过主内存进行交互
在多线程编程中,就会出现下面这两种情况:
由此产生了共享变量a在线程1和线程2中是不可见的,理想的情况下,我们想要实现的是共享变量对所有访问它的线程都是可见的。
不可见往往会导致很多严重的问题,导致数据的不一致性。多线程编程中,要保证线程间的可见性
如何实现共享变量的可见性?要实现共享变量的可见性,必须保证两点:
JAVA在语言层面支持的可见性实现方式有哪些?
1 synchronized实现可见性。
synchronized 的两个作用:
1 原子性(同步)
2 可见性
很多同学对第一种synchronized同步比较了解,都知道。也经常用,其实synchronized还能实现内存的可见性的。
JMM关于synchronized的两条规定:
以上两条规定保证了 线程解锁前对共享变量的修改在下次加锁时对其它线程可见
synchronized线程执行互斥锁代码的过程如下:
1 在synchronized的入口处,获得互斥锁
2 获得互斥锁后,清空工作内存
3 从主内存中拷贝变量的最新值到工作内存
4 执行代码
5 执行完代码后,共享变量的值有可能发生变化,这时会将共享变量的值刷新到主内存中
6 释放锁
在演示代码前,先了解一个事件
问:程序的执行顺序一定是按照代码的书写的顺序执行的吗?
答:答案是 否是的。即不一定是按照代码的书写顺序执行的,主要是因为编译器或者处理器做了优化,即指令重排序
问:为什么要有重排序?重排序有什么好处?
答:编译器或者处理器为了提高程序的性能而做的优化,更加符合处理器执行效率。
问:指令重排序不会打乱了程序的逻辑吗?
答:不会,因为JMM有一条规定,as-if-serial原则,即保证在单线程里面,指令重排序前和重排序后,执行的结果是一致的。
如下面的例子,a,b的赋值顺序不同,但不会影响sum的值,注:是在单线程里面。
重排序前: 重排序后:
a = 1 b = 1
b = 1 a = 1
sum = a + b sum = a + b
指令重排序:代码书写的顺序与实际执行的顺序不同,指令重排序是编译器或者处理器为了提高程序性能而做的优化
as-if-serial原则:单线程里,无论怎么重排序,程序的执行结果是一致的
如上面的例子,无论前面两句怎么排序,最后一句sum = a + b 是不能排序的。这样就保证了程序的结果一致性
结论:
1 重排序不会给单线程带来内存可见性问题
2 多线程程序交错执行时,重排序可能会造成内存可见性问题
今天就先写到这里,下一篇会有代码来讲演示上面的理论
标签:
原文地址:http://www.cnblogs.com/start1225/p/5879798.html