标签:
今天我们学习了数据表的相关操作,以下是笔记。
在数据表中添加数据有多种的语法形式
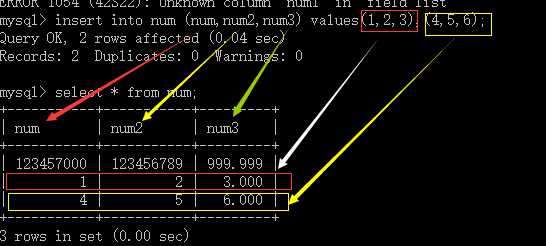
形式1:insert [into] table_name [(字段1,字段2,字段3......)] values (值1,值2,值3......),(......),(......)......;
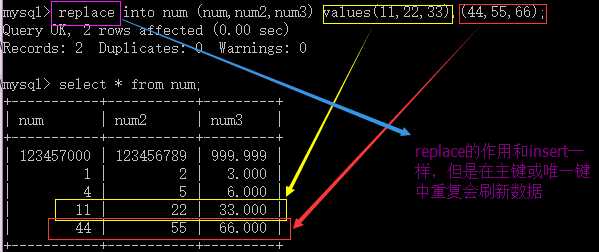
形式2:replace [into] table_name [(字段1,字段2,字段3......)] values (值1,值2,值3......),(......),(......)......;
形式3:insert [into] table_name [(字段1,字段2,字段3......)] select 字段1,字段2,字段3......from other_table_name;
形式4:insert [into] table_name set 字段1 = 值,字段2=值,......
说明:
在四中方法中,形式1是最常用的方法,其中它的值,可以是一个固定的值或者函数调用的结果,或者是变量,如果对应的字段是字符或者时间类型,则直接使用单引号。形式1和形式2的用法大体是一致的,唯一的不同就是在插入的数据的主键或者唯一键有重复的时候,形式1会报错,形式2会更改数据。形式3就是简单的将其他表查询到的数据添加到当前的表中,但必须要注意其字段列表要一一对应。形式4的比较不常用。
方式2:
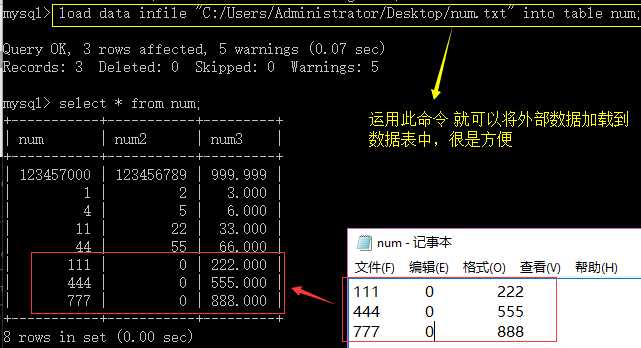
load data(载入数据)
语法形式:
load data infile“完整的数据文件路径” into table table_name;
删除数据的语法形式:
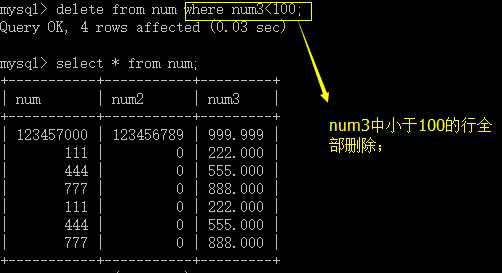
delete from table_name [where] [order by] [limit];
说明:
删除数据是以行为单位的;
要带where条件,否则会删除所有的数据;
order by 排序设置,通常与limit一同使用;
limit来限定要删除几行数据;
 》》
》》
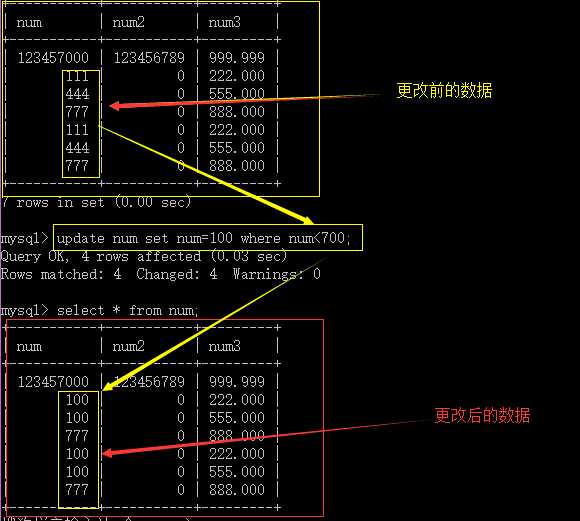
修改数据的语法:
update table_name set 字段1=值,字段2=值......[where] [order by] [limit];
说明:
修改时也与where同时用,否则修改全部数据;
值如果是字符串或时间类型,加单引号;
因为查询的内容比较多,所以查询的相关知识我们单独作为一章来记载。(下面一大章)
查询语句的基本语法形式:
select [all或distinct] 字段或表达式列表 [from子句] [where子句] [group by子句] [having子句] [order by 子句] [limit子句]
下面咱们来详细讲解每个子句的含义及用法;
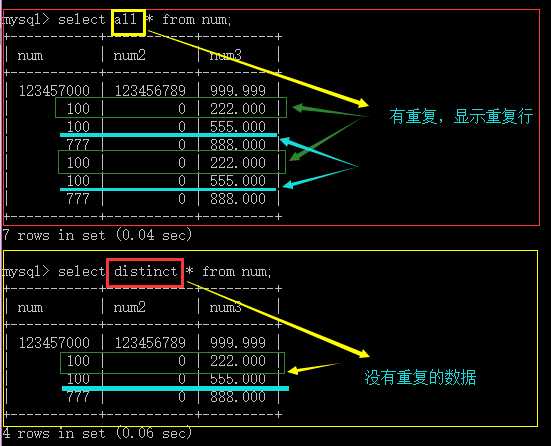
用于设定select出来的数据,是否消除重复行,可以不写,,默认为all
all:表示不消除,即表示所有都显示出来,是默认值;
distinct:消除;
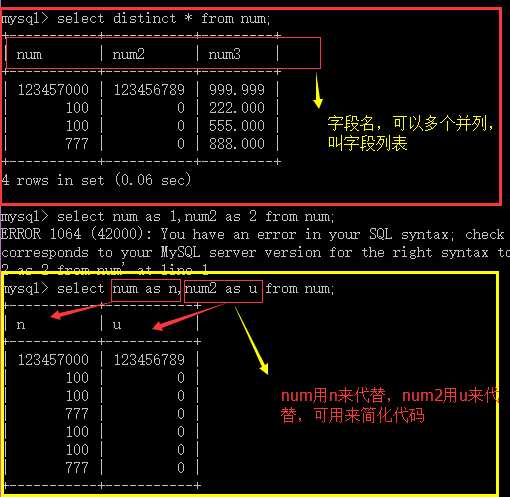
字段,就是自如来源于表的,在表刚建立的时候设置;
表达式就是类似与内容比如:1,1+2+3,或者now()等内部函数;
当然了我们每插寻出来的结果都可以用as进行别名设置;
from子句表示select 部分中取得数据的数据源---其实就是去哪个表中拿数据,其后面通常是跟表名,也可以是其他一些数据来源(连接表);其中from前面跟的字段必须是来源表中已有的字段名;
说明:
where子句就是对from子句中的数据源的数据进行条件筛选,筛选的机制就是逐行进行判断,其作用基本跟if语句一样。where依赖于from语句。
where中通常使用各种运算符:
算数运算符:+ - * / %;
比较运算符:> < = >= <= <>(不等于) == !=(不等于)
逻辑运算符:and or not
特殊运算符:is between in like
is运算符:
有四种使用的情况:
XX is null:判断某个字段是“null”
XX is not null:判断某个字段是不空;
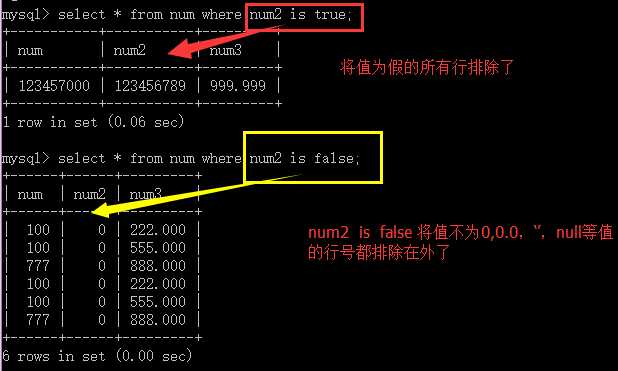
XX is true:判断某个字段是否为真;
XX is false:判断某个字段的值否为假 : 0,0.0,‘’,null
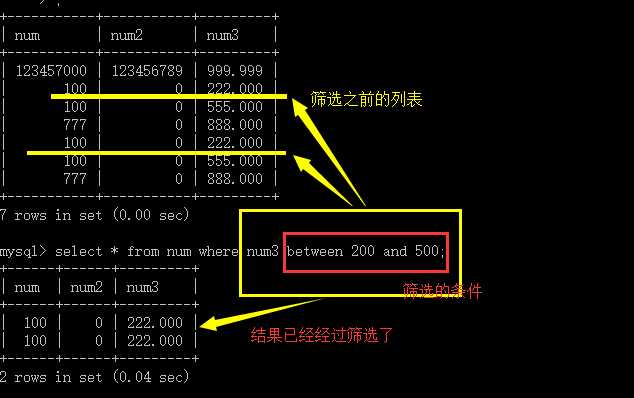
between运算符:
用于判断某个字段的数据值是否在某个给定的范围,适用于数字类型。
用法: XX between 值1 and 值2;
其用法类似于 XX>=值1 and XX<=值2;
in运算符:
其表示字段的值为所列出的这些值中的一个,就算满足条件,这些值基本上都是无规律的。
语法:XX in (值1,值2,值3......)

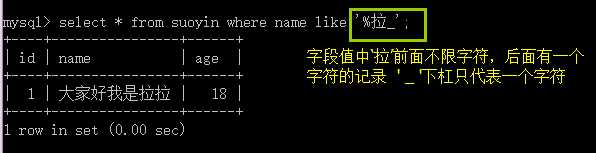
like 运算符:对字符串进行模糊查询
其作用就是实现对字符串的某种特征信息的模糊查找,依赖于下面两个特殊符号:
% :代表任何个数的任何字符;
_ :(下杠),代表一个任何字符;
其使用法:XX like “要查找的内容”


形式:
group by 字段1 [desc|asc],字段2[desc|asc]......
说明:
分组是对前述已经找出来的数据及已经经过where筛选过的数据进行某种标准进行分组;同时,该分组结果,可以同时指定“排序方式”,通常情况下分组只依据一个字段,2个以上很少。
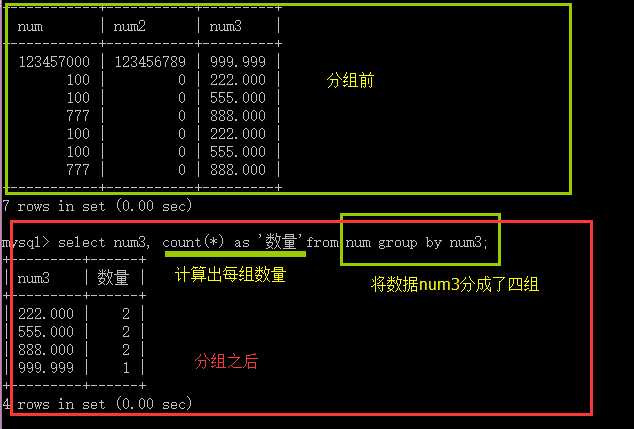
那么什么是分组呢? 就是将多行数据,以某种标准来进行分类;
特别注意的是:分组之后的结果只有一个一个的组了,其结果就是在select 语句中输出的部分只应该出现组的信息:
select 组信息1,组信息2,...from 数据源 group by字段;
在应用中,分组之后,通常有以下几种可以用的组信息(即可以出现在select中):
1.分组依据的本身信息,其实就是该分组依据的字段名;
2.每一组的数量信息是用:count(*)获得;
3.最大值:max(字段名) 最小值:min(字段名) 平均值:avg(字段名) 总和:sum(字段名)
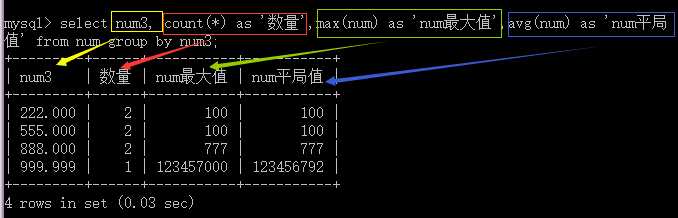
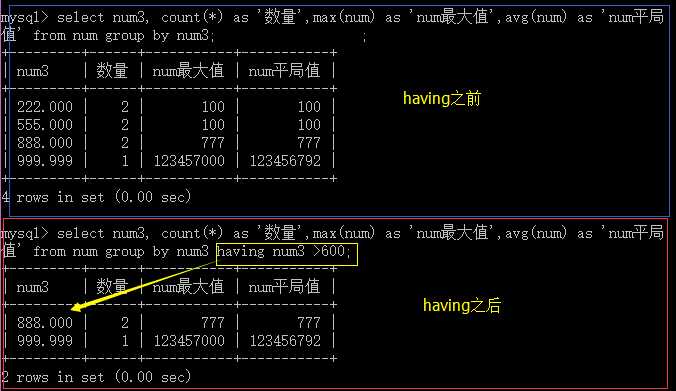
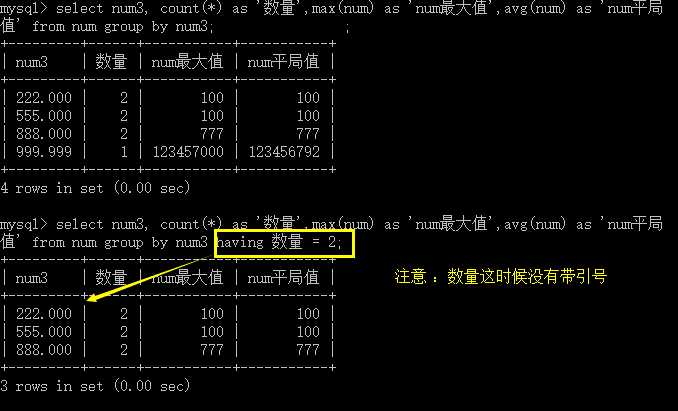
having的作用和where的作用是一样的,但是只是对分组的数据进行筛选。
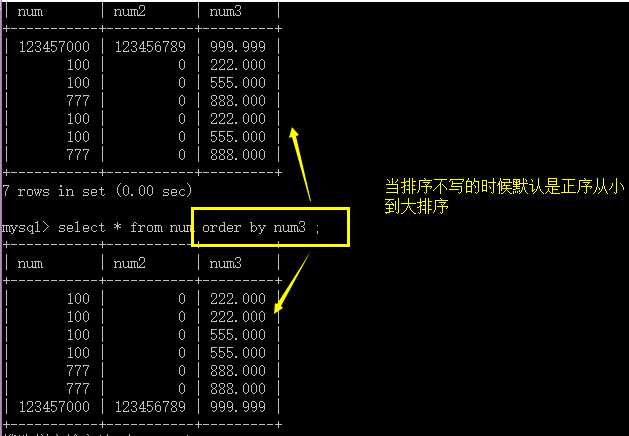
它用于将前面取得的数据以设定的标准来进行排序以输出结果。
形式:
order by 字段1 [asc|desc],字段2[asc|desc]......
说明:
对前面的结果数据指定一个或多个字段排序;
排序可以规定是正序还是倒叙;
多个字段排序都是在前一个字段 的基础上。
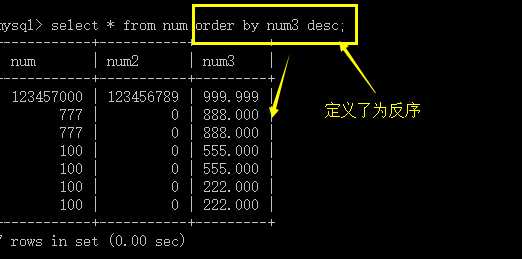
含义:
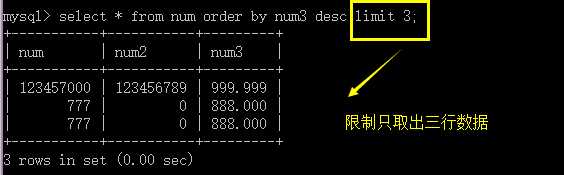
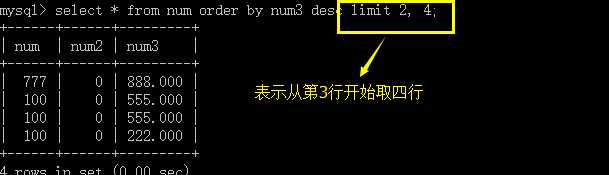
它用于将前面取出的数据按指定的行取出来:从第几行开始取出多少行;
形式:
limit 起始行号,行数;
说明:
起始行号都是从零开始;
起始行号跟数据中的任何一个字段没有关系;
要取出的行号也是数字,应该大于0;
可以有简略:limit 行数;表示从第零行开始;
标签:
原文地址:http://www.cnblogs.com/pzp-fire/p/5877811.html