标签:
说实话我从没有在实际项目中使用过索引,仅知道索引是一个相当重要的技术点,因此我也看了不少文章知道了索引的区别、分类、优缺点以及如何使用索引。但关于索引它最本质的是什么笔者一直没明白,本文是笔者带着这些问题研究msdn的一点小结以及一大堆疑惑。
1.表结构
当开发者在数据库中创建一个表时,此时默认为这个表创建了一个分区,注意是一个分区。分区是一种数据组织单元,在这个分区中可存在2种结构,分别是堆结构或B树结构(索引结构),也就是说一个分区里要么是堆结构要么是B树结构。为了在某些方面提高性能以及便于管理, 我们可以自己创建分区,将数据以水平方式,也就是以行为单位进行数据行的分区移动。虽然进行分区将数据行组划分到不同的地方,但是进行查询或其他操作时仍将这个表看成是单个的逻辑实体。分区中包含由页组成的堆结构或B树结构,可能刚开始你会对堆和B树结构有点懵,不过没关系先了解整个表的结构然后再深入细节。对于堆结构或B树结构中的数据页,为了更高效的存储它们,又分了3种存储单元,本质其实就是页的类型,它们也是一种数据组织单元。这三种页类型分别是IN_ROW_DATA、LOB_DATA、ROW_OVERLLOW_DATA。页类型的官方叫法是分配单元,它之所以存在,是因为数据页中存在占空间小的数据类型和占空间比较大的数据类型,对于像varchar(max)这样的数据列就要分配大型存储单元,对于普通的数据列当然就要分配小型存储单元,就好比int类型为4字节,bit类型为1字节一样。到这里关于一张表的构成也就介绍完了,如下图所示。
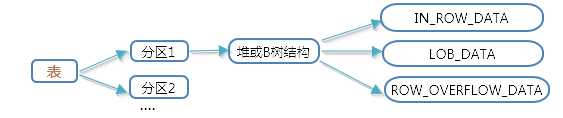
2.页类型
现在你或许很好奇这3种页类型到底是怎样的类型,从上面为什么要分类的介绍中可以看出它们分类的依据是占用空间的大小。IN_ROW_DATA是最基本的页类型,包含除LOB数据以外的所有数据行和索引行,页的类型为Data或Index。LOB_DATA页类型,用来存储大型数据对象,包括以下数据列text、ntext、varchar(max)、nvarchar(max)、image、varbinary(max)、xml、CLR UDT,页的类型是Text或Image。ROW_OVERFLOW_DATA页类型,当IN_ROW_DATA页类型中的这一行数据超过8060时,将把这个页上占用空间最大的列移动到溢出页中,原始页上将维护一个指向溢出页的指针。溢出页类型和大对象页类型管理页的方式相同,都是使用IAM页链来进行管理,注意又出现了一个新名词IAM页链,用一句话来描述IAM的话就是IAM用来跟踪表的指定分配单元。现在我们仍继续深入这3种页类型,更深刻的理解还是需要sql实例。如下我创建了student表。
use testDb create table student( studentId int, studentName nvarchar(3600), studentAddress nvarchar(3600), studentDescription nvarchar(max) ) --查看创建的页信息,最后一个1表示显示所有分页的信息,包括IAM分页,数据分页,所有存在的LOB分页和行溢出页,索引分页 dbcc ind(‘testDb‘,‘student‘,1) --此时什么都没有 insert into student values(1,‘李四‘,‘湖北‘,‘学生‘) dbcc ind(‘testDb‘,‘student‘,1)
在插入一条数据后再执行dbcc ind,它可得到各个类型的页面分布和它们的所在的文件号和页号,此时不再什么都没有而是出现了下面的结果。

PageFID和PagePID分别指页面Id和页面编号,IAMFID指管理该页面的IAM页所在的文件ID,IAMPID指管理该页面的IAM页所在的文件编号。ObjectID指的是student这个表的对象Id,PartitionNumber表示表或索引所在的分区号,PartitionId表示分区id。接下来要介绍的这4个列要格外注意了。
iam_chain_type表示的正是页类型,现在我们可以看到全IN_ROW_DATA类型的,此外还可以是溢出类型和大对象数据类型。
PageType也相当重要,它表示分页类型,1表示数据页,2是索引页面,3是Lob_mixed_page,4是Lob_tree_page,10是IAM页面。
IndexID表示索引ID,0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引,大于250的是text或image字段。
IndexLevel表示索引层级,0 代表叶级别分页 ,大于0 代表非叶级别层次,NULL 代表IAM分页。
从结果中我们看到当插入这条数据后新增了一个数据页和IAM页,那IAM页和数据页到底是什么关系呢?带着这个问题继续新增数据。
--新增数据以致溢出,并且插入大数据对象 insert into student values(2,REPLICATE(‘小王‘,1700),REPLICATE(‘湖北‘,1700),REPLICATE(‘哈‘,80000)) dbcc ind(‘testDb‘,‘student‘,1)

现在又新增了5个页,数据页又增加了一个114,溢出页为93和其相应的IAM页,大对象数据增加了109和IAM页。产生溢出数据的原因正是我新增的这一行除大对象数据外占用空间超过了8060字节,大数据对象则是因为插入了80000个字符‘哈‘,另外这些数据全都使用的是堆结构。现在再来理解IAM,前面说了IAM用来跟踪每一个分配单元,这个跟踪的意思其实就是记录这些页的顺序以便将这些页链接起来。如果一个IAM页面存储的这个分配单元页信息超过了它本身的大小,那么会再创建新的IAM页,这样IAM页和IAM页一起来记录分配单元页的信息,将这些IAM页称为IAM页链。
3.堆结构与B树结构
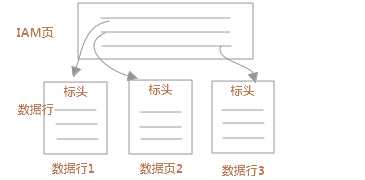
有了上面的一个铺垫,现在要来探索的便是堆和B树了。堆结构是不含聚集索引的数据结构,每个堆中的每个分区至少有一个 IN_ROW_DATA 分配单元。如果堆包含大型对象 (LOB) 列,则该堆的每个分区还将有一个 LOB_DATA 分配单元。如果堆包含超过 8,060 字节行大小限制的可变长度列,则该堆的每个分区还将有一个 ROW_OVERFLOW_DATA 分配单元。堆中的数据页和行没有任何特定的顺序且没有链接在一起,IAM页内的信息记录了数据页之间唯一的逻辑链接。sys.system_internals_allocation_units系统视图中的列 first_iam_page指向管理特定分区中堆的分配空间的一系列 IAM 页的第一页,具体的结构图如下图。
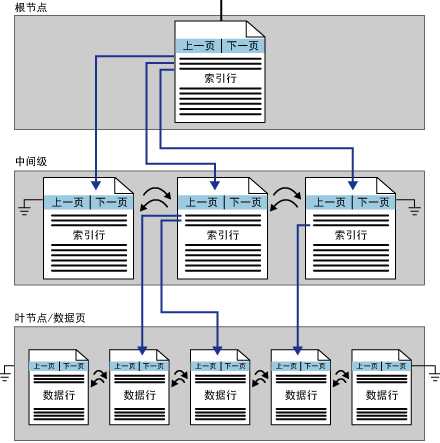
接下来就是本文的重点,聚集索引和非聚集索引的结构。关于聚集索引与非聚集索引区别的经典说法是索引就像字典的目录,聚集索引好比按拼音查找,非聚集索引好比按偏旁来查找。索引是按B树结构组织的,所以我们现在要将这种具体的实例与B树关联起来。对于聚集索引,其B树结构的顶点称为根节点,根节点与叶节点之间的任何索引层级都被认为是中间级,其中最核心的是叶节点包含基础表的数据页,其余节点(根节点和中间级节点)包含的是索引页,索引页中存在索引行,每一个索引行包含一个键值对和一个指针。键值对的内容是索引顺序和该行所链接的下级节点中最小的值。比如2个键值对5-100和6-200,第一个表示这个索引行是第5个,那它的下级节点中最小的就是100,范围是100~200,索引行中的指针则是指向了下一个索引页或叶节点中的数据行。再看看我从msdn上截的聚集索引结构图就能够很清楚地理解使用索引加快速度的本质原因了。
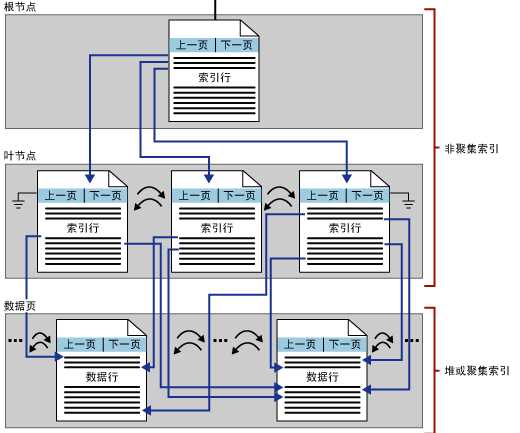
对于非聚集索引,它与聚集索引最本质的两个区别是"表中的数据行不按非聚集键的顺序排序和存储"和"非聚集索引的叶子节点不是数据页而是索引页"。也就是说非聚集索引并没有真正的对数据在物理上进行排序,只是在数据表外建立了一个索引B树结构,它根据非聚集索引列进行了排序并在每个索引节点中有指向数据表中数据行的指针。非聚集索引中的索引行包含非聚集键值对和行定位符,其实也就是指针,但是有时候是在存在聚集索引的情况下去创建非聚集索引,有时候是在堆结构中创建非聚集索引,因此这个行定位符即可能是指向聚集索引中的索引键,又可能是指向堆中的数据行。这里还有一个问题要注意,索引的目的是进行排序,而在聚集索引的基础上创建非聚集索引时,有可能这个聚集索引是非唯一聚集索引,这样将有可能造成排序错误,因此SQL Server 将在内部生成一个唯一键以使所有重复键唯一,此四字节的值对于用户是不可见的,仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值,SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。
4.索引疑惑
以前阅读索引的文章时知道索引这个工具适用于查询量很大的列,不适用于需要很多更新的列,那为什么会这样呢?当在一个列上创建聚集索引时,由于聚集索引中直接让索引页指向了数据页,因此聚集索引的查询速度几乎总是比非聚集索引的查询速度快。对于更新操作,它降低索引查询速度的最本质原因就是索引碎片。索引碎片可分为外部碎片和内部碎片,博客园上有很多关于这方面的文章。笔者学习的过程可以用理解-不理解-理解-不理解这样的感觉来形容, 我最初的理解是这样的。
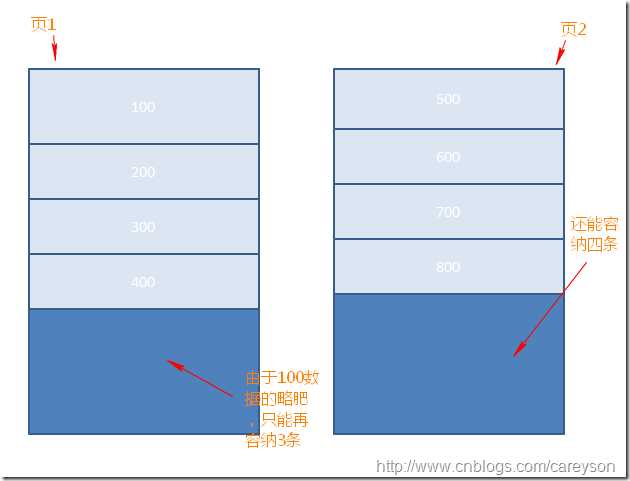
当创建好聚集索引后,此时是一个B树结构,假如每个索引页(8060字节)中有5条数据。那如果进行一个删除操作造成很多页中的索引条数不再是5条,这样索引页中不就有很多剩余部分了吗,这就是内部碎片。我查阅的资料里出现内部碎片大概是2种情况,一是新增数据导致分页从而出现剩余空间,一是删除原有数据页中的部分数据导致出现剩余空间。
如果进行一个新增操作,假如有3页数据,现在有一个新增一条数据的操作。按照顺序应该放在第一页,可是现在第一页空间无法容纳。这会导致创建一个新的页,但是,这个页并不像逻辑顺序那样在第一页和第二页之间,最终结果是在物理上与第一页不连续,这就是外部碎片。出现外部碎片最关键的是要在物理上造成分离而不是连续。
本来我以为我理解了索引碎片,可是我又发现有些随笔里关于索引碎片举例中,内部碎片是新增数据导致索引分页,外部碎片则是新增数据导致分页。如下面这2张图,左边是内部碎片示例图,右边是外部碎片示例图。这又让我感到不理解了,从表面上看内部碎片和外部碎片都是新增数据导致分页,难道内部碎片与外部碎片之间仅仅只是描述的角度不同,实际上本质是一样的。后来仔细阅读前辈的文章才知道还是有区别的,不仅分页且在物理上导致新增页与原来的页不连续才是外部碎片。很快我的理解又变成不理解了,或许是我有点钻牛角尖,但是这个地方好多随笔都很模糊。我不明白到底这个新增的页,是如何分配物理空间的。什么时候会与原来的页连续造成内部碎片,什么时候会与原来的页不连续造成外部碎片?
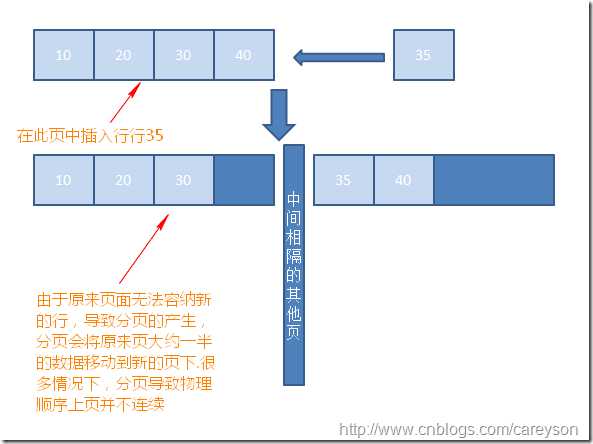
再来思考出现碎片的这种情况下,为什么会变慢。在内部碎片中,索引页里一个页有很多剩余空间,这是让我认为变慢的现象。我在网上查阅资料来解释为什么变慢发现大概都是这样的说法:明明只有10页的数据结果却要在20页中查询,这增加了I/O而且还导致页命中率下降,存储上也必须消耗更多的空间。假设现在是这样一种情况,我有10页数据,进行删除操作后每页中的数据减少了,这样造成了内部碎片。按照一般的想法现在速度变慢了,的确这些数据可能已经不需要10页来存储,可能5页就足够。可是我原来是有10页数据,现在依旧是10页数据,为什么相对于以前完整的10页数据来说现在变慢了?我越来越想知道到底这种内部的操作的是什么样子的,如果有大牛阅读到这里还请您指点一下。我也不知道我为什么会出现这种奇怪的疑问,现在我可以做的就是在进行删除操作导致页数据减少,从而产生内部碎片的情况下查询速度是否真的变慢了呢?sql如下所示,在测试过程中又出现了3个疑惑。
use testDb create table student( studentId int, studentName char(500), studentAddress char(500) ) declare @i int set @i=0 while(@i<3200) begin insert into student values(@i,‘wangwu‘,‘hubei‘) set @i=@i+1 end select index_type_desc, --索引类型说明:HEAP、CLUSTERED INDEX、NONCLUSTERED INDEX、XML INDEX、PRIMARY XML INDEX、SPATIAL INDEX index_depth, --索引级别数:堆 或 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元 page_count, --索引或数据页的总数,对于索引表示IN_ROW_DATA中B树的当前级别中索引页总数,对于堆表示IN_ROW_DATA分配单元中的数据页总数 record_count, --总记录数 fragment_count, --IN_ROW_DATA 分配单元的叶级别中的碎片数。 avg_record_size_in_bytes, --平均记录大小(字节) avg_fragment_size_in_pages, --IN_ROW_DATA 分配单元的叶级别中的一个碎片的平均页数。 avg_fragmentation_in_percent, --索引的逻辑碎片,或 IN_ROW_DATA 分配单元中堆的区碎片。 avg_page_space_used_in_percent --所有页中使用的可用数据存储空间的平均百分比。 from sys.dm_db_index_physical_stats(DB_ID(‘testDb‘),OBJECT_ID(‘student‘),NULL,NULL,‘sampled‘)

create clustered index index_studentId on student(studentId) select index_type_desc, --索引类型说明:HEAP、CLUSTERED INDEX、NONCLUSTERED INDEX、XML INDEX、 PRIMARY XML INDEX、SPATIAL INDEX index_depth, --索引级别数:1是堆 或 LOB_DATA 或 ROW_OVERFLOW_DATA 分配单元 page_count, --索引或数据页的总数,对于索引表示IN_ROW_DATA中B树的当前级别中索引页总数,对于堆表示IN_ROW_DATA分配单元中的数据页总数 record_count, --总记录数 fragment_count, --IN_ROW_DATA 分配单元的叶级别中的碎片数。 avg_record_size_in_bytes, --平均记录大小(字节) avg_fragment_size_in_pages, --IN_ROW_DATA 分配单元的叶级别中的一个碎片的平均页数。 avg_fragmentation_in_percent, --索引的逻辑碎片,或 IN_ROW_DATA 分配单元中堆的区碎片。 avg_page_space_used_in_percent --所有页中使用的可用数据存储空间的平均百分比。 from sys.dm_db_index_physical_stats(DB_ID(‘testDb‘),OBJECT_ID(‘student‘),NULL,NULL,‘sampled‘)

(1)按理说一行数据为1004个字节,一页可以存放8条数据,3200条应该是400行,但结果却是464页,这是第一个让我很疑惑的地方。
(2)在创建索引后页数page_count为458,页数相比原来的464反而还变小了,这是第二个让我很疑惑的地方。
declare @i int set @i=6 while(@i<3200) begin delete from student where studentId=@i set @i=@i+8 end go

(3)结果中avg_fragmentation_in_persent为0,这说明根本就没有产生碎片,我不知道是我误解这篇随笔的意思还是这篇随笔关于内部碎片的地方写错了。
本人数据库菜鸟一枚,如您有想法欢迎交流。
标签:
原文地址:http://www.cnblogs.com/fangyz/p/5856182.html