标签:
基本术语定义
1.系统栈(system stack)是一个内存区,位于进程地址空间的末端。
2.在将数据压栈时,栈是自顶向下增长的,该内存区用于函数的局部变量提供内存。它也支持在调用函数时传递参数。
3.如果调用了嵌套的过程,栈会自上而下增长,并接受新的活动记录(activation record)来保存一个过程所需的所有数据。
4.当前执行过程的活动记录,由标记顶部位置的帧指针(frame point)和标记底部位置的栈指针(stack point)定义。
5.在过程执行时,虽然其顶部的限制是固定的,但底部的限制是可以扩展的(在需要更多内存空间时)。
分析栈帧(分析如下)
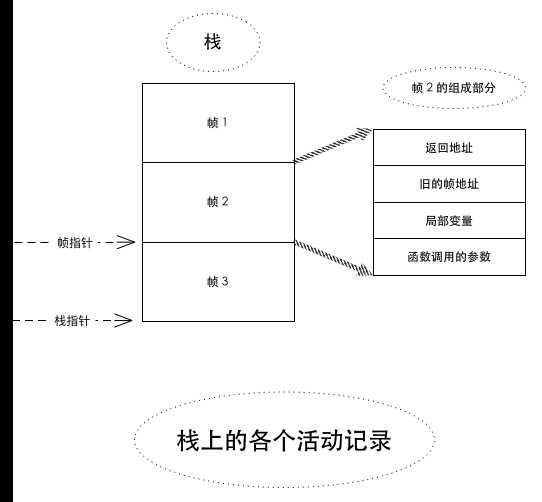
上图第2个栈帧的分析如下:
1、在栈帧顶部是返回地址,以及保存的旧的帧指针。返回地址指定了当前过程结束时代码的控制流转向的内存地址,而保存的旧的帧指针则是前一个活动记录的帧指针。在当前过程结束后,该帧指针的值可用于重建调用过程的栈帧,在试图调试调用栈回溯时,这一点很重要。
2、活动记录的主要部分是为过程调用局部变量分配的内存空间。在C中,这种变量也称为自动变量(automatic variable)。
3、在函数调用时,以参数形式传递到函数的值,存储在栈的底部。
4、所有常见的计算机体系结构都提供了以下两个栈操作指令:
push指令将一个值放置在栈上,并将栈指针esp减去该值所占用的内存字节数。栈的末端下移到更低的地址;
pop指令从栈中弹出一个值,并相应增加栈指针esp的值,也就是说,栈的末端上移了。
5、一般体系结构另外提供两个指令,用于调用和退出函数(自动返回到调用过程),它们也会自动操作栈:
call指令将指令指针的当前值压栈,跳转到被调用函数的起始地址。 call 指令 :在AT&T汇编中,call foo(foo是一个标号)等效于以下汇编指令: pushl %eip ,movl f, %eip ;
return指令从栈上弹出返回地址,并跳转到该地址。过程的实现必须将rerurn作为最后一条指令,由call放置在栈上的返回地址位于栈的底部(实际上是上一个活动记录的底部,当前活动记录的顶部)。 ret指令: 在AT&T汇编中,ret等效于以下汇编指令: popl %eip
过程调用两个组成步骤
1、在栈中建立参数列表。传递到被调用函数的第一个参数最后入栈(从右到左)。这使得C中可以传递可变数目的参数,然后将其从栈上逐一弹出(pop)。
2、调用call,这将指令指针的当前值(call之后的下一条指令)压栈,代码的控制流转向被调用的函数。被调用的过程负责管理帧指针ebp,需要执行下列步骤:
前一个帧指针压栈,因而栈指针下移。
将栈指针的当前值copy给帧指针,标记当前执行函数的栈区的起始位置。
执行当前函数的代码。
在函数结束时,存储的旧帧指针位于栈的底部。其值从栈弹出到帧指针寄存器(ebp),使之指向前一个函数的栈区起始位置。现在,对当前函数执行call指令时压栈的返回地址位于栈低。
调用return,将返回地址从栈弹出。cpu转移到返回地址,代码的控制流也返回到调用函数。
具体C 语言例子分析
初看起来,这种方法似乎有些混乱,因此,我们先看一个简单的C语言例子:
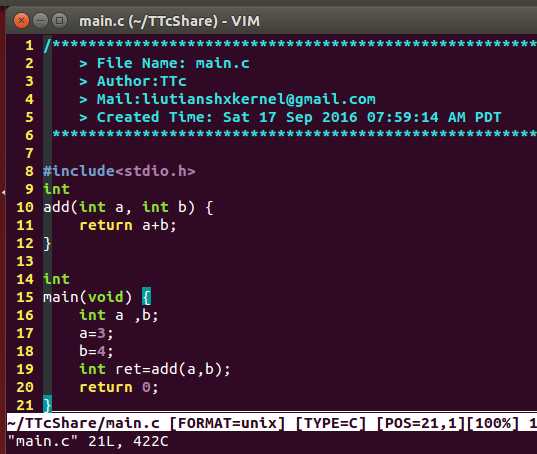
在IA-32系统上,汇编代码本身必须是AT&T表示法给出。
AT&T汇编语法总结为以下5条规则,就足够了。
1.寄存器通过在名称前加百分号(%)前缀引用。example:为使用eax寄存器,汇编代码中将使用%eax。(如果在C中内联汇编的话,C代码必须指定两个百分号,才能在转给汇编器的输出中形成一个百分号)。
2.源寄存器总是在目的寄存器之前指定。 example,在mov语句中,这意味着 mov a,b 将 寄存器a中的值 内容copy到寄存器b中。
3.操作数的长度由汇编语句的后缀指定。b代步byte,w代表word,l代表long。在IA-32上,将一个长整型从eax寄存器移动到ebx寄存器中,需要指定movl %eax,%ebx。
4.间接内存引用(指针反引用)需要将寄存器包含在括号中,example:movl(%eax),%ebx 将寄存器eax的值指向的内存地址中的长整型copy到ebx寄存器中。
5.offset(register)指定寄存器值与一个偏移量联用,将偏移量加到寄存器的实际值上。example: 8(%eax)指定将eax+8用作一个操作数。该表示法主要用于内存访问,例如指定与栈指针或帧指针的偏移量,以访问某些局部变量。
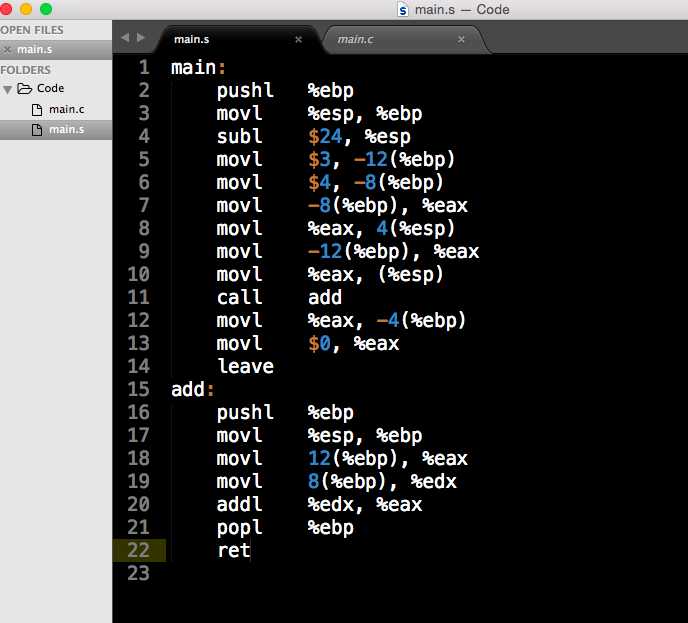
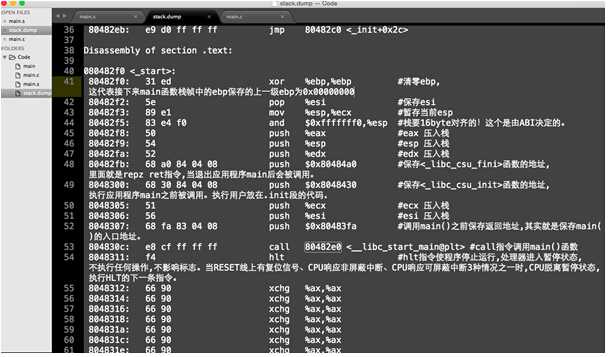
我们来分析一下 main.s 汇编代码:
1.从main 主函数开始分析. 在IA-32系统中,ebp寄存器用于帧指针(栈顶),pushl %ebp 将该ebp寄存器中的值压入系统栈上最低位置,这导致栈顶指针向下移动4byte,这是因为IA-32系统上需要4byte来表示一个指针(pushl中的后缀l,在AT&T汇编中表示一个long型)。
2.第3行,movl %esp, %ebp 将esp(栈指针)寄存器 的值 copy到ebp(帧指针)寄存器中;把当前的栈指针作为本函数的帧指针。
3.第4行,subl $24,%esp 从栈指针减去0x18 byte,使得栈指针下移,将栈的空间增大了0x18=24byte;
调整栈指针,为局部变量保留空间。局部变量必须放置在栈上,在C代码中,a与b两个局部变量,两者都是整型变量,在内存中都需要4个byte。
因为栈的前4个byte保存了 帧指针的旧值(上一个活动记录),编译器将接下来的两个 4byte内存分配给了这两个局部变量。
ebp - 0xC 存着局部变量a的值 3 ; ebp - 0x8 存着局部变量b的值 4 (这里可以看到参数是从右到左 压入栈的)。
4.第5行 ,第6行 movl $0x3, -0xC(%ebp) movl $0x4, -0x8(%ebp) : 为了向分配的内存空间设置初始值(对应C中 局部变量的初始化),编译器使用了处理器的指针反引用选项。 这两天指令通知编译器,引用“帧指针减12”得到的值 在内存中指向的位置。使用mov指令将值3 写入该位置。
编译器接下来用同样的方法处理第2个局部变量,其在栈的位置稍低,ebp - 0x8 (ebp - 8byte) 位置 ,值为4。
5.第7行,第8行设置第2个参数(b),第9行,第10行负责设置第1个参数(a)。 movl -8(%ebp), %eax ; movl %eax, 4(%esp) ; movl -12(%ebp), %eax; movl %eax, (%esp)
局部变量a和b必须用作即将调用的add过程调用的参数。编译器通过将适当的值放置在栈的末端来建立参数列表。
如前所述,第一个参数在最低部。栈指针用于查找栈的末尾。
内存中对应的位置通过指针反引用确定。将栈上的两个局部变量的值分别读入eax寄存器,然后将eax的值写入参数列表中对应的位置。(一般情况)
6.上图描述了 add()函数调用前后,栈的状态。现在可以使用call 指令调用add()函数。call指令 将eip(指令指针寄存器)压入栈,代码控制流在add例程的开始处恢复执行。
根据调用约定,例程首先将此前的帧指针(ebp)压入栈,并将栈指针(esp)赋值给 帧指针(ebp)。
过程的参数可以根据帧指针(ebp)查找。编译器知道参数就在调用函数的活动记录末尾,而在当前活动记录开始处又存储了两个4byte的值(返回地址,旧帧指针)。因此参数可以通过反引用ebp+8和ebp+12访问。
add 指令用于 加法,而eax寄存器用作工作空间。结果值就保存在该寄存器中,使它可以传递给调用函数(这里是main())。
为了返回到调用函数,需要执行以下两个操作: <a>使用pop将存储的帧指针(ebp)从栈弹出到ebp寄存器。栈帧的顶端重新恢复到main()的设置;<b>ret将返回地址从栈弹出到 eip(指令指针)寄存器,控制流转向该地址。
7.因为main()中还使用了另一个局部变量(ret)来存储add()函数的返回值,返回后需要将eax寄存器的值 copy 到ret在栈上的位置。
总结
关于AT&T汇编
enter指令
在AT&T汇编中,enter等效于以下汇编指令:
pushl %ebp # 将%ebp压栈
movl %esp %ebp # 将%esp保存到%ebp, 这两步是函数的标准开头
leave指令
在AT&T汇编中,leave等效于以下汇编指令:
movl %ebp, %esp
popl %ebp
call指令
在AT&T汇编中,call foo(foo是一个标号)等效于以下汇编指令:
pushl %eip
movl f, %eip
ret指令
在AT&T汇编中,ret等效于以下汇编指令:
popl %eip
(个人理解)汇编可以用一句话概括:汇编就是在(寄存器和寄存器)或 (寄存器和内存)之间来回move 数据;就是指:数据在内存和寄存器间来回流动,流动的越频繁就代表程序越复杂,比如office这样的大型软件。
从C语言层面分析:
EBP-xx 一般 是局部变量
EBP+xx 一般都是参数
EBP+4 返回地址 ,制高点, 很多攻击都是攻击这里, 杀毒软件,这里是重点会扫描。
C函数堆栈中分配的空间,并不会清零,所以在写C代码的时候,局部变量一定要初始化赋值。
参数的传递形式、传递顺序已经栈平衡并不是固定的(不同的函数调用约定)。
关于 寄存器 与内存的区别:
寄存器位于cpu内部,执行速度快,但比较贵。
内存速度相对较慢,成本低,所以容量能做很大。
寄存器和内存没有本质区别,都是用于存储数据的容器,都是定宽的。
寄存器常用的8个通用寄存器 :EAX,ECX,EDX,EBX, ESP, EBP, ESI, EDI.
计算机中的几个常用计量单位:BYTE, WORD, DWORD :BYTE(字节) = 8bit ; WORD (字 ) = 16bit ; DWORD (双字)=32bit;
内存的数量特别庞大,无法每个内存单元都命名一个名字,所以用编号来替代。
我们称计算机CPU是32bit或者64bit,有很多书上说之所以叫32bit计算机是因为寄存器的宽度是32bit,这是不准确的,因为还有很多寄存器是大于32bit的。
原文链接:http://blog.tingyun.com/web/article/detail/1132
标签:
原文地址:http://www.cnblogs.com/TingyunAPM/p/5888788.html