标签:
数据控制语言,就是对mysql的用户及其权限进行管理的语句;
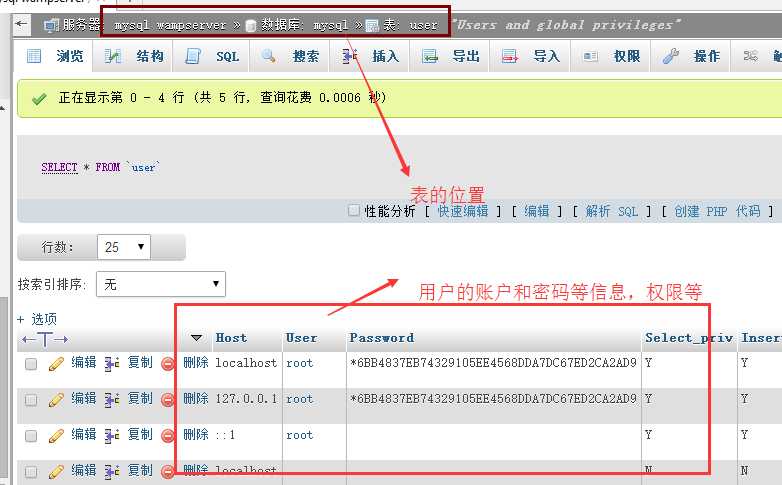
用户数据所在位置
在mysql中的所有用户,都存储在系统数据库mysql中的user表中;
创建用户
形式: create user ‘用户名’@‘允许登录的地址/服务器’ identified by ‘密码’;
说明:
1.允许登录的地址服务器就是允许该设定的位置,来使用该设定的为用户名和密码登录,其他位置不行
2.可见,mysql的安全什么验证需要三个信息。


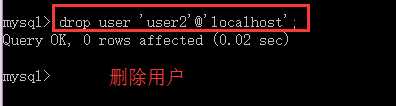
删除用户
drop user ‘用户名’@‘允许登录的地址或服务器名’;
修改用户密码
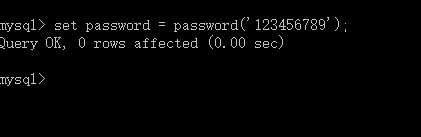
修改自己的密码:
set password = password(‘密码’);
修改他人的密码(要有权限):
set password for ‘用户名’@‘允许登录的地址’ = password(‘密码’);

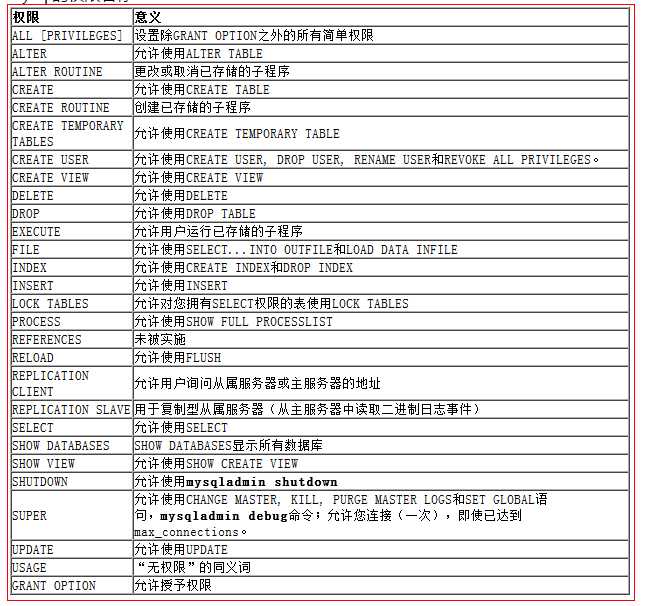
权限是什么呢?
mysql数据库,将其中所能做的所有事情,都分门别类分配到大约30个权限中去了,其中每个权限都是一个“单词”而已!比如:
select 代表可以查询数据;
update 代表可以修改的数据;
delete 代表可以删除数据;
......
其中有一个权限叫做all,其代表所有权限

另一个表现形式:
授予权限
形式:
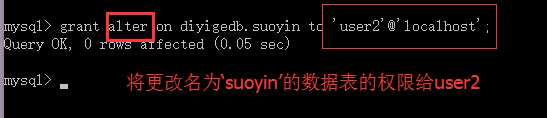
grant 权限列表 on 某库.某对象 to ‘用户名’@‘登录位置’ [identified by ‘密码‘];
说明:
1.权限列表就是多个权限的名词,相互之间逗号分开;
2.某库.某对象,表示给指定的某个数据库的某个下级单位附权;
3.identified by 可以省略,如果不省略,就可以表示赋权限的同时也去修改它的密码;但是该用户不存在,此时就是在创建一个新用户,密码就必须要设置了。

剥夺权限
形式:
revoke 权限列表 on 某库.某对象 from ‘用户名’@‘允许登录的位置’;

事物就是来保证多条增删改语句的执行的一致性:要么执行,要么不执行,只有这两种情况;
原子性:一个事物中的所有语句,应该做到:要么全做,要么一个都不做;
一致性:让数据保持逻辑上的‘合理性’,比如:在一个商品出库的时候,既让商品库中的该商品数量-1,又要让对应用户的购物车中的该商品+1;
隔离性:如果多个事物同时并发执行,但每个事物就像各自独立执行一样;
持久性:一个事物执行成功,则对数据来说应该是一个明确的硬盘数据更改(而不仅仅是内存中的变化)。
事务模式是指:
在我们的cmd命令行模式中,是否开启了“一条语句就是一个事务”的这个开关;
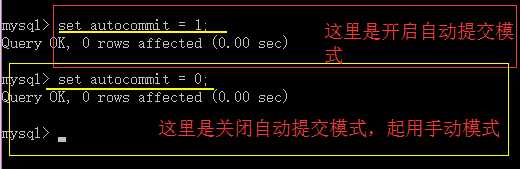
默认情况下,这个模式是开启的,称为“自动提交模式”;
set autocommit = 1;
这样之后,每条增删改语句,就会立即生效;
我们可以把它关闭,那就是‘人为提交模式’------即需要人为提交;
set autocommit = 0;
在这样更改之后,所有增删改语句,都必须使用commit时候才能生效;

1.开启一个事物
start transaction;//这里也可以写成begin
2.执行多条增删改语句;
3.判断这些语句执行的结果情况,并进行提交或回滚;
if(没有出错){
commit;//这里是提交事务;此时就是一次性完成;
}else{
rollback;//回滚事务;此时就是全部撤销;
}

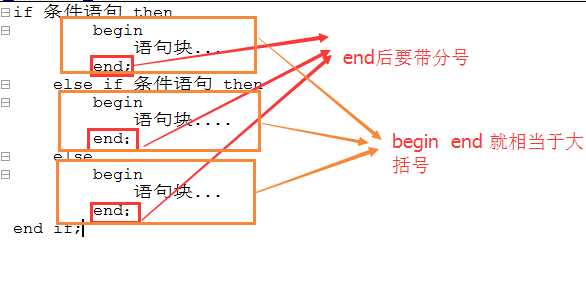
mysql语句中的语句包含符其实就相当于js或者php中的大括号;
[标示符] begin
要执行的语句.......
end [标示符]
举例: if(条件判断)
begin
//......
end;
end if;
if语句
case语句
它相当于php中的switch;

loop循环语句

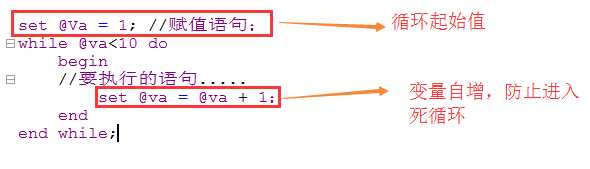
while循环
repeat 循环
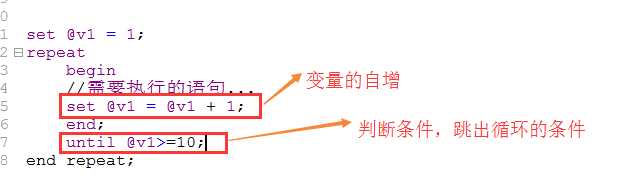
leave语句
leave 标示符;
其作用是用来退出begin...end结构或其他局有标示符的结构。
mysql中,有两种变量形式;
普通变量:不带“@”符号;
定义形式:
delare 变量 类型名 [default 默认值];//普通变量必须先这样定义;
赋值形式:
set 变量名 = 值;
取值就直接使用变量名;
使用“场所”:只能在“编程环境”中使用;
什么是编程环境?只有3个:
1.定义函数的内部;
2.定义存储过程的内部;
3.定义触发器;
会话变量:带“@”符号:
定义形式:
set @变量名 = 值; //跟php类似,无需定义,直接赋值;
基本上在任何地方都可以使用
变量赋值有如下形式:
语法1(针对普通变量)
set 变量名 = 表达式; 此语法中的变量必须先使用declare声明
语法2(针对会话变量)
set 变量名 = 表达式; 此方式无需要declare语法声明,而是直接赋值,类似php定义变量并赋值。
语法3(针对会话变量)
select @ 变量名 = 表达式;#此一举会给变量赋值,同时会作为一个select语句输出结果集;
语法4(针对会话变量)
select 表达式 into @变量名;此句虽然看起来是select语句,但其实并不输出结果集,而只是给变量赋值。

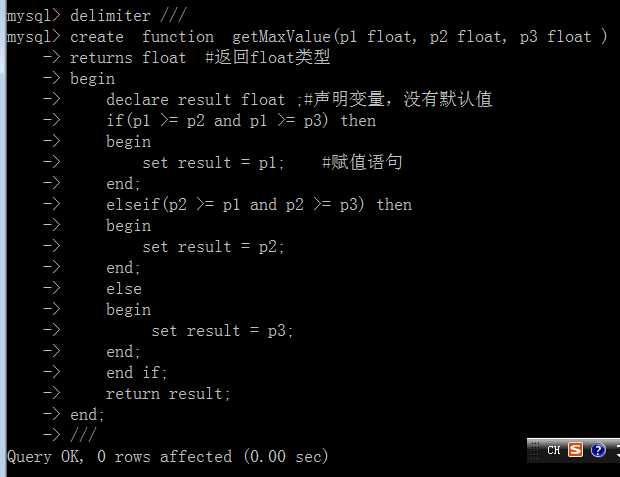
函数,也被说成“储存函数”,其实就是js或者php中所述的函数,但是其唯一的区别就是:这里的函数必须有一个返回值;
定义形式:

注意:
在函数内部,可以使用各种变量和流程控制的使用;
在函数内部,也可以有各种增删改语句;
在函数内部,不可以有select或其他“返回结果集”的查询类语句;
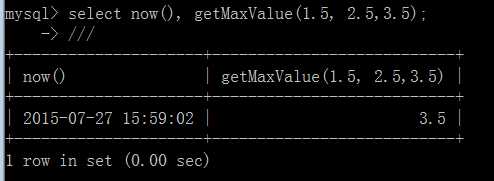
调用形式
跟调用内部函数一样,比如:
select now();
或如果在编程语句中:
删除函数
drop function 函数名;
存储过程 procedure
存储过程,其本质还是函数-----但是:不能有返回值
定义形式:

说明:
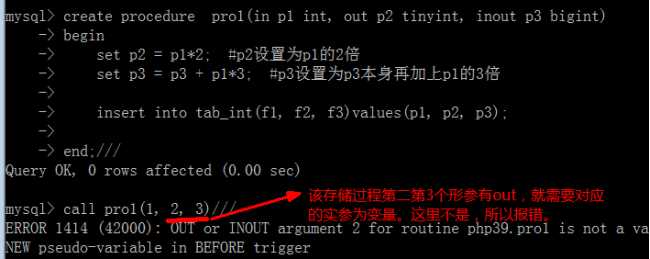
in:用于设定该变量是用来接受实参数据的,即传入数据;默认不写就是in
out:用于设定该变量是用来“存储存储过程中的数据”的,即传出,即函数中必须对他赋值;
inout:是in 和out 的结合,具有双向作用;
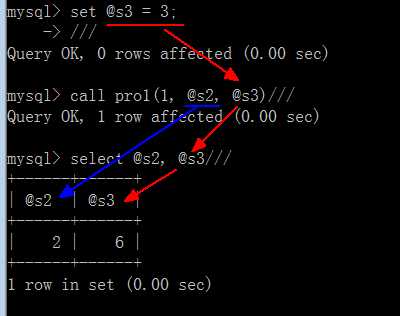
对于,out和in设定,对应的实参,就是“必须”是一个变量,因为该变量是用于“传出传入数据”;
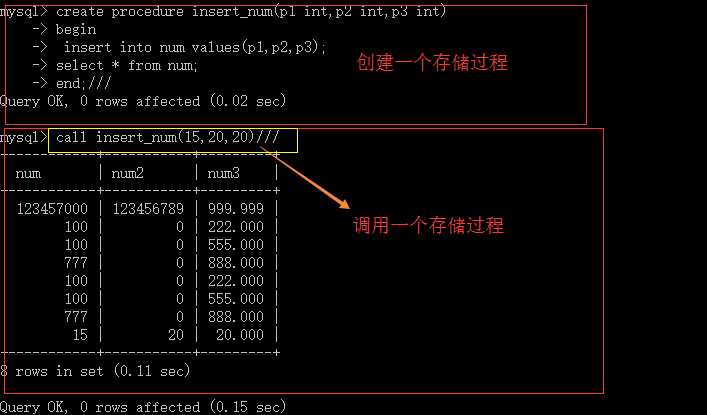
调用存储过程
call 存储过程名(实参1,实参2......)
它应该是在“非编程环境中”调用,即增删改查的场景下:
举例:
创建一个存储过程
该存储过程的目标就是将三个数据存入数据表中;并返回该表的值
举例(使用in ,out, inout)
删除存储过程
drop procedure 存储过程名;

含义
触发器,也就是预先定义好的编程代码(跟存储过程和存储函数一样),并右一个名字。它不能调用,而是在某个表发生某个事件(增删改)的时候会自动调用起来。
定义形式
create trigger 触发器名 触发时机 触发事件 on 表名 for each row as
begin
//触发的语句
end;
说明:触发时机只有两个:before ,after
触发事件,只有三个:insert,update,delete
在某个表进行insert 之前或之后,回去执行其中写好 的代码;即每个表只有6个情形会可能调用该触发器;
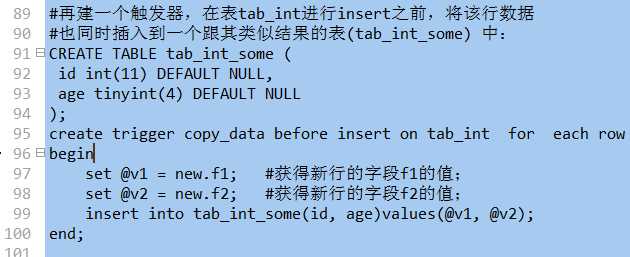
通常,触发器用于对某个表进行增删改操作的时候,需要同时去做另外一件事的情形;
在触发器的内部,有两个关键字代表某种特殊的含义,可以用于获取有关数据:
new 它代表当前正要执行的insert或update的时候的“新行”数据;通过他,可以获取这一新行数据的任意一个字段的值,形式为:
set @vq = new.id//获得该新插入获update行的id字段值
old:它代表当前正要执行的delete的时候的“旧行”数据,通过它,可以获取这一旧行数据的任意一个字段的值,形式为:
set @va = old.id //获得该新插入获update行的id字段的值(前提是有id)


标签:
原文地址:http://www.cnblogs.com/pzp-fire/p/5891168.html