标签:
利用Singular Value Decomposition 奇异值分解,我们能够用小得多的数据集来表示原始数据集,可以理解为了去除噪音以及冗余信息。假设A是一个m*n的矩阵,通过SVD分解可以把A分解为以下三个矩阵:
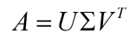
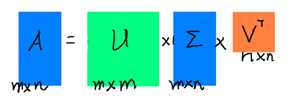
其中U为m*m矩阵,里面的向量是正交的,U里面的向量称为左奇异向量,Σ是一个m*n对角矩阵,对角线以外的因素都是0,对角线都是奇异值,按照大到小排序,而VT(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量)。那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵A的转置 AT * A,将会得到 ATA 是一个方阵,我们用这个方阵求特征值可以得到:
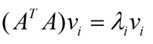
这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
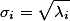
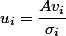
这里的σi 就是就是上面说的奇异值,ui就是上面说的左奇异向量。常见的做法是将奇异值由大而小排列。如此Σ便能由M唯一确定了。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
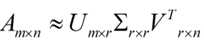
r是一个远小于m、n的数,这样矩阵的乘法看起来像是下面的样子:
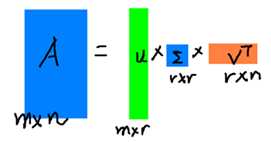
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
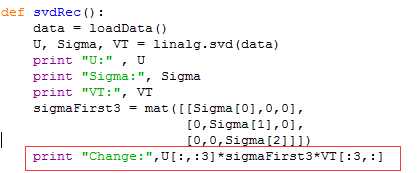
下面演示python上svd相关的一些应用:
1.numpy里面的linalg工具箱可以直接实现SVD分解:
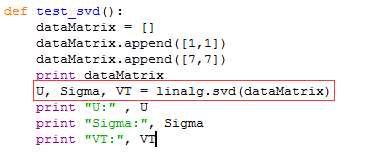
其中Sigma为了节省空间,返回的是一个向量而不是矩阵(只有对角线)。
下面这个例子说明取贡献值top的奇异值来表示原始矩阵基本上是无损失的
2,SVD在推荐系统中的利用
推荐系统有很多种方法,而协同过滤Collaborative Filtering是主流的一种算法,而该算法有两种方式,一种是基于物品的推荐,一种是基于用户的推荐。基于物品的推荐中,假设我们知道了所有电影的相似度,而用户没有看过另外一部电影,就可以通过相似度最高的来推荐给用户;基于用户推荐也是类似的,假设我们知道所有用户的相似度,某个用户A看过的电影,而与他相似度很高的用户B没有看过,则可以推荐给B;这个里面采用的相似度算法一般是欧式距离,皮尔逊系数或者余弦相似度。
假设建立一个矩阵A,是m*n的矩阵,行是所有用户,n是所有物品,矩阵的每个元素代表用户对物品的评分,那么基于物品或者基于用户的推荐就是计算所有列或者所有行的相似度。在现实生活中,这个矩阵是很稀疏的。
课题:推荐用户购买TOPN物品
矩阵C为M*N矩阵,每一行表示每一个用户,每一列表示某一类物品,那么C的第(i,j)个元素表示用户i针对物品j的评分,假设用户user对某物品items(向量)还没有评分过,那么如何像该用户推荐某些物品(其实就是预测该玩家针对没有评分过的物品的评分,求出topN),核心算法就是找出user用户评分过的物品js(向量)的评分,然后找出全网中同时评分过j以及item的用户,根据用户的评分形成两个向量(分别表示用户针对物品j以及item的评分列表,这个里面用到了原始的很大的稀疏矩阵),然后求出这两个向量的相似度p,最终加权预测user针对item的评分:score_pre=p1*score_user_j1+p2*score_user_j2+........
假设把原始的稀疏矩阵变成了下面的(注意与原始的不同Um*m*Sigmam*m*VTm*n):
XformedItem = dataMat.T * U[:,:4] * Sig4.I, 即m*n矩阵变成了(n*m)*(m*4)*(4*4) = n*4 矩阵
标签:
原文地址:http://www.cnblogs.com/crespohust/p/5894076.html