标签:
逻辑回归是线性模型Y=f(x)=b0+b1*x的延伸,一般用来做2分类问题,输出标记C={0,1},C就是classification的意思,通俗的讲,就要建立Y和C之间的关系,Y是多少的时候,C是0,Y是多少的时候,C是1,传统的线性回归输出的y是实数,在负无穷到正无穷之间,而C是0,1两种,使用Sigmoid函数就可以把y从负无穷到正无穷之间转换到0,1之间,该函数为:y=1/(1+e-z),其中z=wTX,x为自变量,w为权重。P记为发生1的概率,即P=Y。
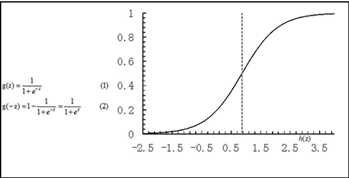
对数几率(发生1与发生0的比值的对数)Ln(p/(1-p))=ln((1/(1+e-z))/(1-(1/(1+e-z))))=lnez=z= wTX,实际上P=1/(1+e-z)=ez/(1+ez)。
也就是说我们根据权重向量WT来计算对数几率,然后在计算P概率(0-1之间)。
使用最大似然估计来求解,对于训练数据集,特征数据x={x 1 , x 2 , … , x m }和对应的分类数据y={y 1 , y 2 , … , y m }。构建逻辑回归模型f(θ),首先,对于单个样本,其后验概率为:
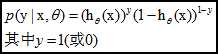
那么,极大似然函数为:
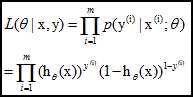
log似然是:
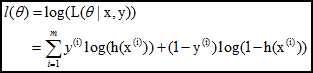
求逻辑回归模型f(θ),等价于:
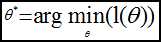
采用梯度下降法:
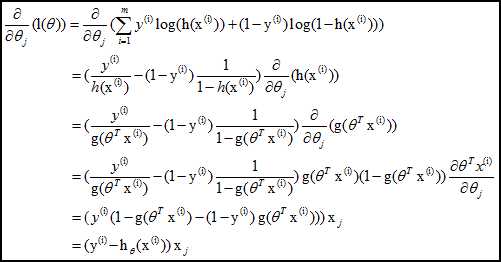
从而迭代θ至收敛即可:
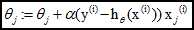
梯度是函数上升最快的方向,沿着梯度方向可以很快找到极值点,假设梯度记为T,梯度上升(下降)的算法迭代公式如下:
Weights = weights+alpha*T,其中alpha称为步长,weights其实就是我们要求的权重矩阵,也就是回归系数矩阵,可以这样理解,如果alpha足够小,我们每次按照alpha距离,按照上升最快的方向(T)走,那么最终会很快的到达极值点,其实就是不断的迭代,知道某个停止条件,比如迭代次数,或者到达某个指定值。
下面使用python演示一个求解案例:
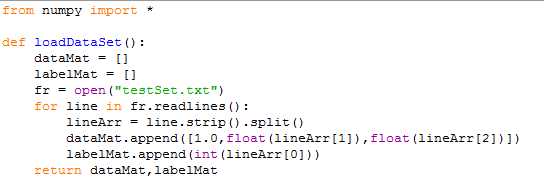
1,首先是load训练数据以及标签进来,以matrix的形式存在
2,定义sigmoid函数
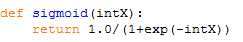
3,梯度上升法

上面的停止条件就是需要迭代500次,而梯度其实就是每次迭代之后真实的label与预测的label之间的差值,然后根据这个差值来不断修正回归系数,值得注意的是上面一开始的时候把初始系数设置为1,然后不断修正。
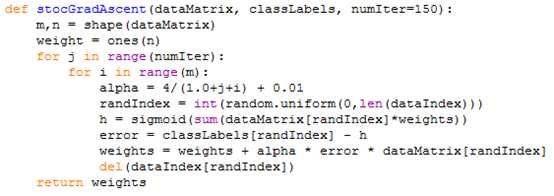
上面迭代了500次,并且每次迭代都是计算了所有的矩阵数据,在样本比较少的时候还比较ok,但是如果样本很大,训练起来的开销是较大的,有一些改进的方法就是在每次迭代的时候不需要计算所有的矩阵数据,而是随机的挑选某行,后者某几行来进行计算,同时也可以不断的修改alpha步长(第一种算法alpha是固定的),有时在分类效果不变甚至更好的情况下训练的成本大大减少,如以下例子:
标签:
原文地址:http://www.cnblogs.com/crespohust/p/5894058.html