标签:
集合也称容器:从大的类别分成两类:Collection和Map,也即:单列和双列列表。
java编程思想中一张图说明该体系的整体结构:其中黑色着重的类是经常使用的类。
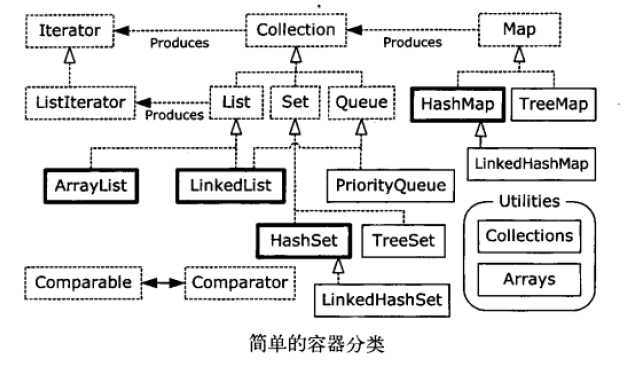
1 Collection
Collection:作为单列集合的根接口。该类集合的继承体系如下:
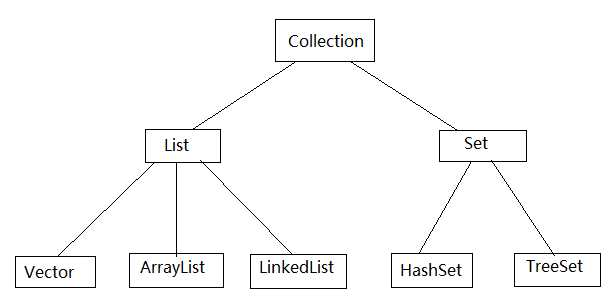
Collection分为两大类:List和Set
1)List:
特点:有序的 collection(也称为序列);列表通常允许重复的元素。
List 接口提供了特殊的迭代器,称为 ListIterator,除了允许 Iterator 接口提供的正常操作外,该迭代器还允许元素插入和替换,以及双向访问。
常用子类实现:Vector/ArrayList/LinkedList
三者之间的区别:
ArrayList:底层结构是数组,查询快,增删慢,实现是不同步的,线程不安全,效率高。
LinkedList:底层是链表,查询慢,增删快,实现不同步,线程不安全,效率高。
Vector:底层数据结构是数组,查询快,增删慢,实现同步,线程安全,效率低(即使是线程安全的也不怎么使用,因为Collections集合工具类提供方法可使线程不安全的集合实现线程安全,此类经常由ArrayList集合取代)
2)Set:
特点:无序,列表中不允许重复的元素(无序:是指存储集合和从集合中取出的顺序是不一致的)
常用子类实现:HashSet和TreeSet
HashSet:
特点:
底层实现不是同步的,线程不安全。
通过查看源码:HashMap底层就是HashMap(即底层数据结构是哈希表),只是进行了包装。
而哈希表结构底层依赖于hashCode()和equals()方法保证元素的唯一性。
实现唯一性:
对于基本包装类型:基本类型对象的包装类已经实现了equals()和hashCode()方法,故可以保证元素的唯一性。
String类:重写了equals()和hashCode()方法,也可以保证唯一性。
自定义类:需要重写Object类中equals()方法和hashCode()方法
其常用子类:
LinkedHashSet:
特点:具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。此实现非同步。
此实现与 HashSet 的不同之外在于,后者维护着一个运行于所有条目的双重链接列表。
此链接列表定义了迭代顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。
其数据结构是哈希表和链表结合,既保证唯一性同时又可以有序。(哈希表保证元素唯一性;链表保证有序)
再次强调这里的有序是存取的顺序一致。。。。
TreeSet:
特点:
底层实现是非同步的,线程不安全。
查看源码,其底层是包装了TreeMap集合,数据结构是红黑树即平衡二叉树。
而平衡二叉树的特点:能够对元素进行排序,排序方式:自然排序和比较器排序
此处的排序(存储元素的位置排序)是和上面讲的有序(插入和取出的顺序一致)不是一个概念。
实现排序:
自然排序:在创建集合时,使用不带比较器的构造函数,一般使用无参构造。
对于自定义存储元素对象,要想实现自然排序,应该实现Comparable<T>接口,实现其唯一的方法:int compareTo(T o)。
而对于基本类型装箱对象(比如Integer/Character等),因为其本身已经实现了该接口,所以直接可以使用就能实现自然排序。
String类:其已经实现了Comparable接口,也实现了其compareTo方法,故可以直接存取,即可实现自然排序。
比较器排序:如果要使用比较器排序,需要使用带参构造,往构造函数中传入一个比较器Comparator子类对象。一般有两种方式:
内部类方式:在创建集合对象时,使用内部类实现一个比较器对象,后面会有实例。
外部类方式:新建一个类,实现Comparator<T>接口,并且实现其中的方法:int compare(T o1,T o2),在创建集合之前创建这个类的实例,传入集合带参构造。
Colllection集合的遍历一般有三种方式:
1)迭代器
2)增强for
3)普通for
2 Map
特点:
存放键值对,依赖于键
一个映射不能包含重复的键;每个键最多只能映射到一个值(键唯一,值可重复)
其实现子类有的允许null键和null值,有的不允许null键和null值
常用子类:
HashMap TreeMap LinkedHashMap ConcurrentHashMap(比较流行在多线程) Hashtable(已经不怎么用了)
HashMap: 集数组和链表(即哈希表)的一种集合,底层实现依赖于key的hashcode()以及key的equals()方法
插入一个键值也即一个Entry,首先计算h=h(key.hashcode())即key的hashcode的散列函数,然后根据h值在数组中找到对应的索引。
如果该位置已经有元素,则需要和该索引处的链表的每一个元素进行比较。
Hashtable:
出现在JDK1.0,早于集合,后被修改实现Map接口正式加入集合。
此类实现了哈希表,底层实现是同步的,故线程安全,不过效率低。
已经有HashMap取代,一般不用。
ConcurrentHashMap:
位于java.util.concurrent包下,很明显用于多线程。
虽然该类也是同步的,但是其锁的密度和哈希表不同,其效率比哈希表高,当然和HashMap相比效率有所下降,但是在高并发情况下,其保证了安全性。
其底层同步源码实现也是其一大亮点。
HashMap和Hashtable的区别:
HashMap用来替代Hashtable。除了下面两点不同,其余差不多
1)Hashtable是同步的,线程安全,效率低。而HashMap线程不安全,效率高。
2)HashMap允许null键和null值,而Hashtable不允许null键和null值
遍历方式:
由键找值:
1)获取键的集合:Set<T> keySet()
2)遍历该键的Set集合,根据键查找对应的值:V get(Object K)
获取键值对集合:
1)获取键值对Set集合:Set<Map.Entry<K,V>> entrySet()
2)遍历该Set集合:其元素类型是 Map.Entry<K,V> ,集合中的每一个元素类型都是Map.Entry<K,V>。
3)根据这个类中的:K getKey() 和 V getValue()方法分别获取键和对应的值。
标签:
原文地址:http://www.cnblogs.com/zwbg/p/5904060.html