标签:
一、背景
在线上系统中,如果我们发现存放数据库文件的磁盘空间不够,我们应该怎么办呢?新买一个硬盘挂载上去可以嘛?(linux下可以直接挂载硬盘进行扩容),但是我们的SQL Server是运行在Windows下的,有什么办法可以解决这燃眉之急呢?
有两种方法可以解决上面的问题:第一种就是把数据库磁盘转换为【动态磁盘】,新增新的磁盘就可以解决了;第二种就是我今天要讲述的,使用SQL Server在其它磁盘(或者逻辑分区)中添加新的文件,添加完成后,SQL Server马上就能进新的数据了。
上面两种方法的区别就是,第二种方法的响应速度会更快,而且也更符合一般的应用场景,因为我们一般对磁盘分区的时候会划分几个逻辑分区,常常会出现某些逻辑分区剩余的空间会比较大,刚刚好用于放置新的文件。
二、知识准备
在讲解如何磁盘扩容之前,我先讲讲一些关于表分区的一些知识,这对理解磁盘扩容很有帮助。
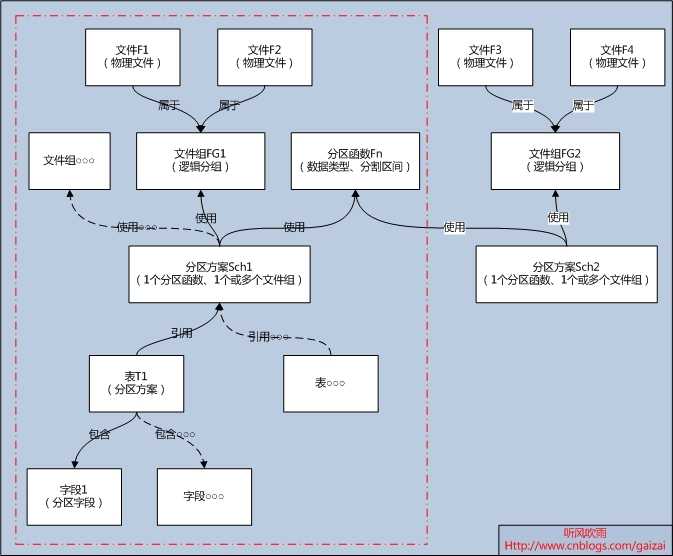
(Figure1:分区逻辑关系图)
Figure1分区逻辑关系图解析:
1) 文件组只是一个逻辑上的存在;
2) 一个文件组下面可以包含多个文件;(文件组FG1包含了文件F1和文件F2)
3) 分区方案包括了一个分区函数和一个或者多个文件组;(分区方案Sch1使用了分区函数Fn和文件组FG1和n个其它文件组)
4) 一个分区方案可以被多张表引用;
5) 两个分区方案可以使用同一个分区函数;(分区方案Sch1与分区方案Sch2使用了同一个分区函数Fn)
在使用SSMS生成创建表的SQL语句的时候,我们经常看到SQL中包含ON [PRIMARY]的字样,这就说明我们平时创建的表都是创建在主文件组(在没有指定分区方案的情况下)的,而默认情况下,主文件组中就只包含一个mdf,所以当数据不断增长的时候,发现mdf文件也会在不断的增长(考虑文件自动增长设置的值,不是每次进数据都会增长mdf文件的)。
综上所述:在出现数据库磁盘空间不够的情况下,我们在PRIMARY文件组中添加一个ndf文件,这就相当于我们表分区有类似效果(数据分散),区别就是我们没有使用分区函数规则哪些数据应该存在哪些文件组中。想要了解更多表分区的实战可以参考:SQL Server 表分区实战系列(文章索引)
三、测试过程
(一) 模拟磁盘不够用的情况:
1) 创建一个数据库,在创建过程中设置ldf文件的初始大小,尽量占用完磁盘空间,mdf文件的初始大小尽量小,方便测试;
2) 插入一定量的数据占用剩余的磁盘,插到一定量的时候就会发生不够用而报错;
3) 接下来我们在主文件组PRIMARY中创建一个位于其它逻辑分区的ndf文件;
4) 继续插入数据,查看数据的插入情况;
(二) 测试脚本及效果图:
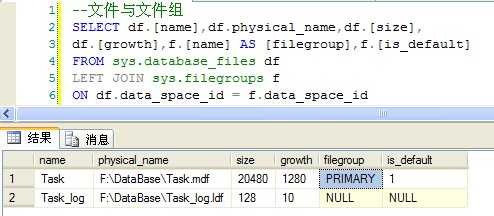
1) 使用下面的SQL查询Task数据库的文件与文件组的信息:
--文件与文件组 SELECT df.[name],df.physical_name,df.[size], df.[growth],f.[name] AS [filegroup],f.[is_default] FROM sys.database_files df LEFT JOIN sys.filegroups f ON df.data_space_id = f.data_space_id
2) 使用下面的SQL查询Task数据库的文件剩余空间的信息:
--当前数据库,数据文件占用与剩余空间 SELECT DB_NAME() AS DbName, name AS FileName, size/128.0 AS CurrentSizeMB, size/128.0 - CAST(FILEPROPERTY(name, ‘SpaceUsed‘) AS INT)/128.0 AS FreeSpaceMB FROM sys.database_files;
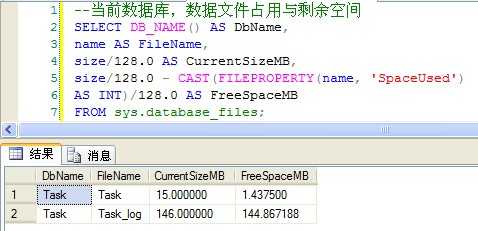
(Figure3:文件剩余空间)
3) 查看F盘的使用情况:

(Figure4:磁盘信息)
4) 在Task数据库中执行下面的SQL语句(笛卡尔值):
--生成测试数据 select top 2000000 identity(int, 1,1) as id, 0 as usered into TempA from syscolumns a,syscolumns b
执行上面的SQL,会产生下面的错误信息:
消息1101,级别17,状态12,第2 行
由于文件组‘PRIMARY 中的磁盘空间不足,无法为数据库‘Task‘ 分配新页。请删除文件组中的对象、将其他文件添加到文件组或者为文件组中的现有文件启用自动增长,以便增加必要的空间。
5) 上面我们已经成功模拟了磁盘无法分配空间的环境,现在我们就来创建一个存储于PRIMARY主文件的ndf文件:
--创建ndf文件 ALTER DATABASE [Task] ADD FILE (NAME = N‘Primary_data‘,FILENAME = N‘E:\DataBase\Primary_data.ndf‘,SIZE = 20MB, FILEGROWTH = 10MB ) TO FILEGROUP [Primary];
6) 再次执行步骤4的SQL,数据已经可以插入了,现在我们来看看效果:
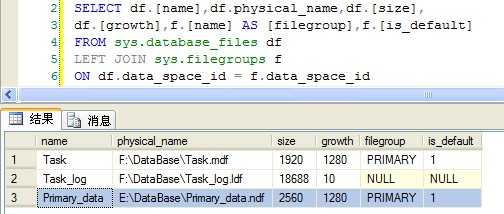
(Figure5:文件与文件组)
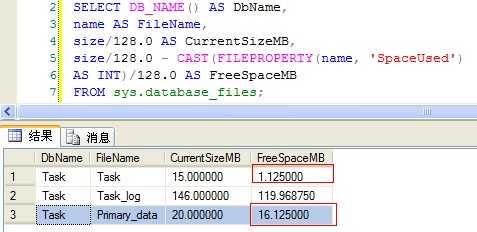
(Figure6:文件剩余空间)
Figure5中可以看到在E盘中已经添加新的文件:Primary_data.ndf,数据已经成功插入,并且Primary_data.ndf文件的可用空间减少了(Figure6),说明我们已经成功进行磁盘扩容了。
有一点需要注意,如果你猜想可能还需要在这个数据库创建未分区的新表或者索引,那么你需要设置一下文件组的默认值选项。
四、知识点
1. SQL Server的文件类型可以分为mdf、ndf、ldf,我们通常创建数据库的时候一般只创建了mdf和ldf文件。
2. 主要数据文件包含数据库的启动信息,并指向数据库中的其他文件。用户数据和对象可存储在此文件中,也可以存储在次要数据文件中。每个数据库有一个主要数据文件。主要数据文件的建议文件扩展名是.mdf。
3. 次要数据文件是可选的,由用户定义并存储用户数据。通过将每个文件放在不同的磁盘驱动器上,次要文件可用于将数据分散到多个磁盘上。另外,如果数据库超过了单个Windows 文件的最大大小,可以使用次要数据文件,这样数据库就能继续增长。次要数据文件的建议文件扩展名是.ndf。
4. 事务日志文件保存用于恢复数据库的日志信息。每个数据库必须至少有一个日志文件。事务日志的建议文件扩展名是.ldf。
5. 每个数据库有一个主要文件组。此文件组包含主要数据文件和未放入其他文件组的所有次要文件。可以创建用户定义的文件组,用于将数据文件集合起来,以便于管理、数据分配和放置。
6. 如果在数据库中创建对象时没有指定对象所属的文件组,对象将被分配给默认文件组。不管何时,只能将一个文件组指定为默认文件组。默认文件组中的文件必须足够大,能够容纳未分配给其他文件组的所有新对象。
7. PRIMARY 文件组是默认文件组,除非使用ALTER DATABASE 语句进行了更改。但系统对象和表仍然分配给 PRIMARY 文件组,而不是新的默认文件组。
8. 针对Figure1中描述的:分区方案Sch1(1个分区函数、1个或多个文件组),下面是对这个说法的验证SQL:
--1.创建分区函数 CREATE PARTITION FUNCTION [Fun_Archive_Id](INT) AS RANGE RIGHT FOR VALUES(200000000) --2.创建分区方案 CREATE PARTITION SCHEME [Sch_Archive_Id] AS PARTITION [Fun_Archive_Id] TO([Primary],[Primary])
9. 针对Figure6中显示,Task.mdf和Primary_data.ndf都同时出现空间减少的情况?我给了我们什么提示呢?
10. SQL SERVER会根据每个文件设置的初始大小和增长量会自动分配新加入的空间,假设在同一文件组中的文件A设置的大小为文件B的两倍,新增一个数据占用三页(Page),则按比例将2页分配到文件A中,1页分配到文件B中?
11. 在SQL SERVER 2008之后,还新增了文件流数据文件和全文索引文件?
12. 如果一个表是存在物理上的多个文件中时,则表的数据页的组织为N(N为具体的几个文件)个B树.而不是一个对象为一个B树?
原文:http://www.cnblogs.com/gaizai/archive/2012/11/27/2790251.html
标签:
原文地址:http://www.cnblogs.com/datazhang/p/5909158.html