标签:
前辈在代码中使用了HashTable,由于我用的比较少,不能理解,为什么不用Dictionary?看了源码以及查阅资料,总结如下:
首先看看它们的继承体系:
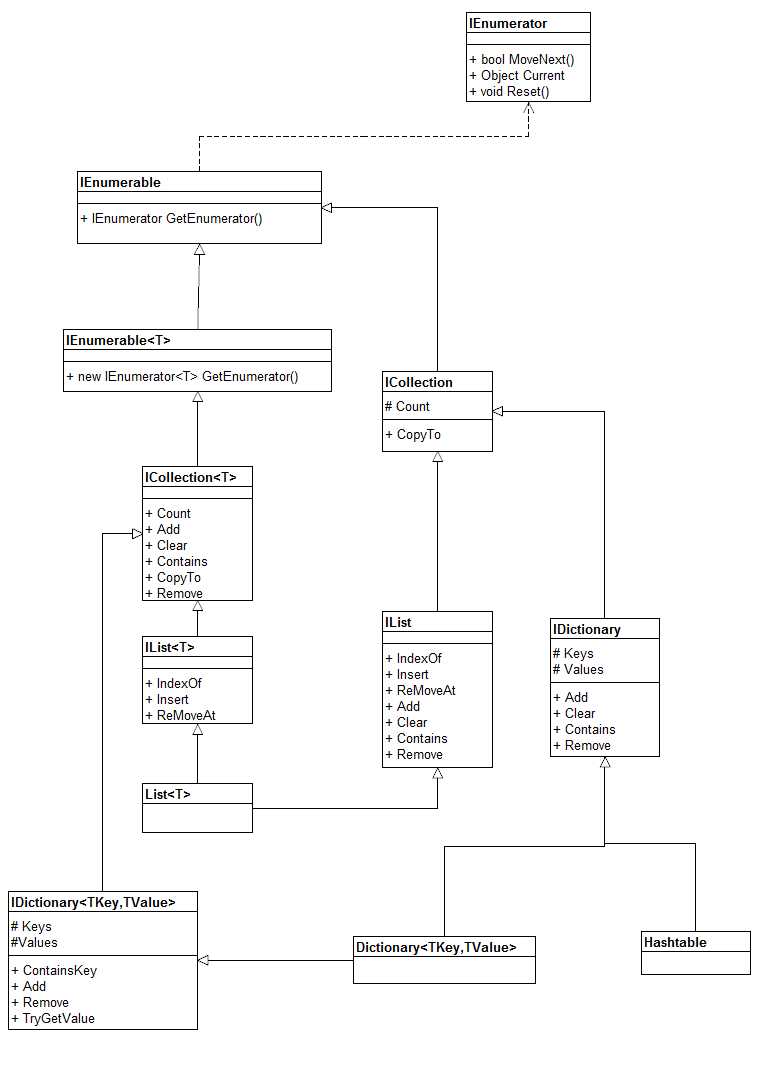
我把list<T>的继承体系也一并画出来,因为c#集合中List<T>和Dictionary<T>这两种数据结构实在太常用了。从上图中可以看到Dictionary和HashTable都继承于IDictionary。既然父辈都相同,那么注定会有很多相似的地方。那么它们又会有哪些不同呢?
这个还得研究源码,先看看HashTable:
1 private struct bucket { 2 public Object key; 3 public Object val; 4 public int hash_coll; // Store hash code; sign bit means there was a collision. 5 } 6 7 private bucket[] buckets;
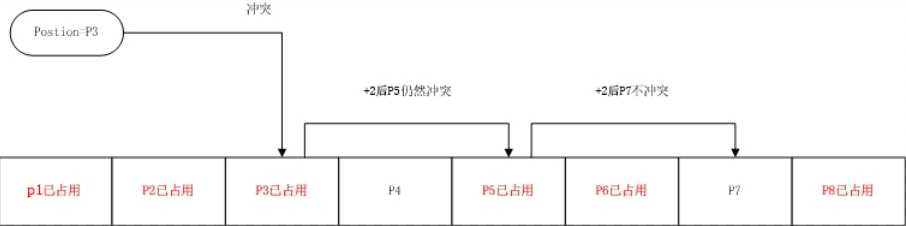
HashTable 定义了一个结构体数组,hash_coll里面存储了hash code。那么hash code又是什么东西呢?hash code其实类似于索引。还记得int[],按顺序存储,我们必须知道它确切的存储位置,即在数组中的索引。在HashTable中,Key的类型是object,所以理论上可以是任意类型,但是我们实际上最常用的是Int和String类型。因此,HashTable是可以按字符串索引的。归根结底,微软扩展了数组,自定义了一个数组。这就带来了一个问题。什么问题?存储问题。以前的数组存储,我们按数字索引存储。现在呢,我们按key存储,如何按key存储?这就需要一个方法,把key映射到数组的不同位置上,并且不能重复。我们把这个映射方法称为散列函数GetHashCode。如果hash code出现重复了,我们称为哈希碰撞或者哈希冲突。产生冲突当然需要解决了。解决这一冲突的简单办法,便是不断地尝试其它位置,直到冲突解决。想想我们中午去饭店吃饭的时候,总要找个座位,这个座位必须是空的才行,如果发现这个座位有人,那么我们再去寻找其它的座位。如果所有的座位都满了,我们只能等待别人让出座位。程序若发现数组中的大部分位置都被占了,那么会扩展这个数组,否则会影响性能,总不能把时间花在找座位上。如下图所示:
Dictionary的内部存储结构:
1 private struct Entry { 2 public int hashCode; // Lower 31 bits of hash code, -1 if unused 3 public int next; // Index of next entry, -1 if last 4 public TKey key; // Key of entry 5 public TValue value; // Value of entry 6 } 7 8 private int[] buckets; 9 private Entry[] entries;
从结构体的定义中,我们可以看出,Dictionary比HashTable多了一个next字段。那么这个next字段是做什么用的?
Dictionary处理哈希冲突的方法,是把具有相同的哈希值的元素放到一个逻辑链表里面。那么next字段正是指向下一个元素的索引。这种处理冲突的方法跟化学当中的同位素还是有点相似的。我们把不同的元素放到数组中,每个元素的同位素放到自己的逻辑链表里。具体如何实现,我们看源码:
1 private void Insert(TKey key, TValue value, bool add) { 2 3 if( key == null ) { 4 ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); 5 } 6 7 if (buckets == null) Initialize(0); 8 int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; 9 int targetBucket = hashCode % buckets.Length; 10 int index; 11 if (freeCount > 0) { 12 index = freeList; 13 freeList = entries[index].next; 14 freeCount--; 15 } 16 else { 17 if (count == entries.Length) 18 { 19 Resize(); 20 targetBucket = hashCode % buckets.Length; 21 } 22 index = count; 23 count++; 24 } 25 26 entries[index].hashCode = hashCode; 27 entries[index].next = buckets[targetBucket]; 28 entries[index].key = key; 29 entries[index].value = value; 30 buckets[targetBucket] = index; 31 version++; 32
我把插入字典的核心代码贴出来。这段代码,不画图不太好理解。首先解释一下,entries是存放元素的数组,buckets也是数组,记录entries数组的索引。假设我们数组大小为5,hashcode的取值范围在1-30之间。
图1为数组的初始状态:buckets一开始全部为-1,entries为空数组

图1
图2:插入hashcode为9的元素
9%5=4,所以buckets[4]=0,记录第一元素的索引值。

图2
图3:插入第二个元素,hashcode=26,26%5=1,所以buckets[1]=1

图3
图4:插入第三个元素,hashcode=25,25%5=0,所以buckets[0]=2

图5:插入第四个元素,hashcode=10, 10%5=0,所以buckets[0]=3

注意:第三个元素指向了第二个元素,因为buckets[0]同时记录了元素2和元素3,所以发生了冲突,此时用到了元素的链表来记录所有冲突的元素。
图6:插入第五个元素,hashcode=5,5%5=0,所以buckets[0]=4

发现了吗?如果发生冲突,新的元素,总是指向前一任。所谓的元素的链表,不是真实的链表结构存储的,而是逻辑上,用Next记录前任元素的索引值罢了,还是用的同一个数组。
好了,Dictionary和HashTable是同源,它们实现了自己的哈希算法。至于两者之间的效率,那得具体看情况了。对于含有大量装箱拆箱的操作,那当然了用泛型字典合适。对于数据量比较小的字符串处理,用HashTable反倒效率可能高一些。具体情况,再具体研究吧,没有一概而论。
c# 图解泛型List<T>, HashTable和Dictionary<TKey,TValue>
标签:
原文地址:http://www.cnblogs.com/wangqiang3311/p/5910254.html