标签:style blog http color strong 文件 2014 问题
初学Python,本身就在一些语句处有些迷惑,如 a = u‘你好‘,不知加上这个Unicode参数有何作用。一直到做爬虫抓取新闻时,在cmd的输出上总是出现错误。经过检索相关知识后,对一些编码问题做个小总结,其中参杂个人猜测,难免会有错误,以后再慢慢修改了。
1.一定要声明#coding=XXX吗?
首先.py文件中,编码默认是ASCII的,一旦py文件中出现了中文类似编码,IDE就会提示
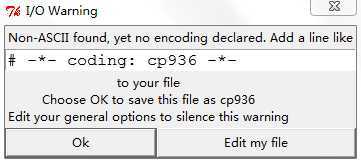
也就是提示文中出现了非ASCII,建议在文件开始制定编码,当然我们常用的是#coding:utf8 (貌似用那个带好多花花的,或者utf-8写法都无所谓)
2.Unicode编码是做什么的?
产生历史什么的就不提了,在python中有两种字符串类型,unicode和str ,简单来说Unicode是python内部表示字符串的方法,同时很多终端也是可以识别这个,而str的编码格式就是文件其实#coding:指定的。写个例子
: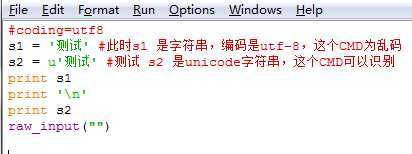 这个直接在windows下执行的话显示:
这个直接在windows下执行的话显示: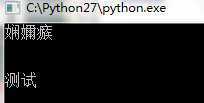 。
。
3.如何进行编码转换
想要解决2中的问题,很明显,需要将s1按照utf-8解码成为原始模式(unicode)模式OK,如s3 = s1.decode(‘utf8‘) 然后print s3 即可。可以这么总结:在读取一个内容时,或者说从网上抓取内容时,Python会将其保存在str中,如果说想要转换成其他的类型,需要先进性相应的decode,然后再encode改变格式。举个例子:
#coding=utf8 s1 = ‘哈哈‘ s2 = u‘哈哈‘ uni_s1 = s1.decode(‘utf8‘) assert(uni_s1 == s2) #如果不相等抛出异常 str_s2 = s2.encode(‘utf8‘) assert(str_s2 == s1) raw_input("")
这个直接运行显示无错。也比较好理解了。
最近在抓取一个网页上的内容时,在cmd中显示出来总是乱码,现在发现了问题,原来是utf8的格式,现在在内容显示时候加上.decode(‘utf8‘).encode(‘gbk‘)便能正常显示中文了。或者说,在read网页时候,直接解码为unicode也可!
标签:style blog http color strong 文件 2014 问题
原文地址:http://www.cnblogs.com/hi-net/p/3907688.html