标签:
Dueling Network Architectures for Deep Reinforcement Learning
ICML 2016 Best Paper
摘要:本文的贡献点主要是在 DQN 网络结构上,将卷积神经网络提出的特征,分为两路走,即:the state value function 和 the state-dependent action advantage function.
这个设计的主要特色在于 generalize learning across actions without imposing any change to the underlying reinforcement learning algorithm.
本文的结果表明,这种设计结构可以当出现许多相似值的 actions 的时候,得到更好的 策略评估(policy evaluation)。
引言:文章首先开始讲解了最近的关于 Deep Learning 网络结构上的快速发展,列举了一些成功的案例。并且提到了现有的 DRL 方面的发展,主要依赖于设计新的 RL 算法,而不是新的网络结果。本文则从网络结构方面入手,提出一种新的结构和现有的 RL 算法更好的结合在一起。
传统单流程的 Q-network 与 新提出的 dueling Q-network 的示意图如下:
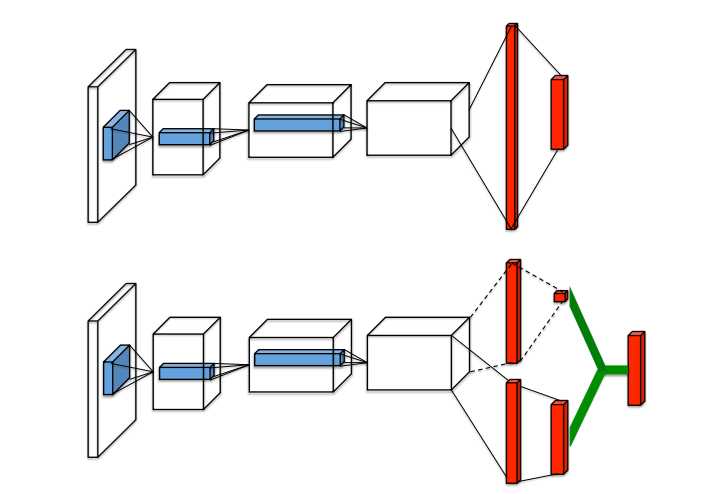
可以看出,本文提出的 dueling network 将后续的输出分为了两个分支,来分别预测 state-value 和 the advantages for each actions ; 绿色的输出模块执行 下面提到的公式(9),来组合这两个输出。两个网络结构都是输出每一个 action 的 Q-values 。
直观上看,the dueling architecture 可以学习到哪一个状态是有价值的 (which states are (or are not) valuable),而不必学习每一个 action 对每一个 state 的影响。这个对于那些 actions 不影响环境的状态下特别有效。为了说明这一点,我们可以考虑图2 所展示的显著性图。

这个图展示了两个不同时间步骤的 the value and advantage saliency maps。在一个时间步骤上,the value network steam 注意到 the road,特别是 the horizon,因为这个地方出现了新的车辆。他也注意到 score。 the advantage stream 另一方面不关心视觉输入,因为当没有车辆出现时,你可以随意的选择 action,而对环境几乎没有影响。但是第二个图可以看出,
论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
标签:
原文地址:http://www.cnblogs.com/wangxiaocvpr/p/5927777.html