标签:des style blog http color java 使用 os
目录
1. Linux通信机制分类简介 2. Inter-Process Communication (IPC) mechanisms: 进程间通信机制 3. 多线程并行中的阻塞和同步 4. Ring3和Ring0的通信机制 5. 远程网络通信
1. Linux通信机制简介
在开始学习Linux下的通信机制之前,我们先来给通信机制下一个定义,即明白什么是通信机制?为什么要存在通信机制?
0x1: Linux通信目的
1. 数据传输: 一个进程需要将它的数据发送给另一个进程,发送的数据量在一个字节到几兆字节之间 2. 共享数据: 多个进程想要操作共享数据,一个进程对共享数据的修改,别的进程应该立刻看到 3. 通知事件: 一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程),从广义上讲,事件也是一种数据(数据量很小的数据),只不过这段数据的目的在于标识另一个事件的发生,
而不是自身的意义 4. 资源共享: 多个进程之间共享同样的资源。为了作到这一点,需要内核提供锁和同步机制 5. 进程控制: 有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变,为了实现进程互斥同步控制,进程间往往会发送一些信号量,从本质上
理解,这些信号量同样也是数据(即你也可以将它们理解为数据传输),差别在于这些数据量往往很小(甚至只有1bit),仅仅用于通知某种条件的达成与否而存在的
0x2: 通信机制的分类
Linux下的通信机制是一个大的概念,我们可以理解为任何需要和别的模块进行交互、协作的模块组件都会涉及到通信机制,就像我们生活中一样,我们需要和各种人和机构进行"通信",Linux系统中也一样,总体来说,我们在操纵系统这个层面上所谈的通信机制包含以下方面
1. 进程间通信机制 2. 多线程并行中的阻塞和同步 3. Ring3和Ring0的通信 4. 远程网络通信
值得注意的是,
1. 这4个方面是Linux下通信机制的4个不同方面,而要实现这些机制需要有对应的技术,每种机制都会有多个技术方案的支持,同样,单个技术方案也可能同时支持多种机制,我们在学习操作系统原理的时候,一定要明白机制和技术的
关系 2. 我们可能在学习编程技术的(例如C#、JAVA..)时会看到很多的进程间通信的API、类库、函数等等,我们必须明白的是编程语言所使用到的技术都是基于操作系统提供的特性实现的。也就是说,C#/JAVA中的很多延时触发、异步通
信技术的底层原理都是操作系统的通信机制,我们在学习的时候要注意理解它们之间的从属关系,不要混淆了
2. Inter-Process Communication (IPC) mechanisms: 进程间通信机制
进程间通信(Inter-Process Communication (IPC) mechanisms)中涉及到的技术主要包括
1. 信号量(Signals) 2. 管道(Pipes) 1)普通管道: PIPE 对于普通管道,我们要注意它通常有两个限制: 1.1) 单工,只能单向传输 1.2) 只能在父子或者兄弟进程间使用 2)流管道: s_pipe 2.1) 半双工的管道,可以双向传输 2.2) 但同样只能在父子或者兄弟进程间使用 3)命名管道: name_pipe 3.1) 单工,只能单向传输 3.2) 可以在许多并不相关的进程之间进行通讯 3. 套接字(Sockets) 4. System V通信机制(System V IPC Mechanisms) 1) 共享内存(Shared Memory) 2) 信号量(Semaphores) 3) 消息队列(Message Queues)
0x1: 信号量(Signals)
信号是在软件层次上对中断机制的一种模拟,在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。信号是异步的,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。值得注意的是:
信号是进程间通信机制中"唯一"的"异步通信机制",可以看作是异步通知,通知接收信号的进程有哪些事情发生了
信号事件的发生有两个来源
1. 硬件来源 1) 比如我们按下了键盘 2) 其它硬件故障 2. 软件来源 最常用发送信号的系统函数是 1) kill 2) raise 3) alarm 4) setitimer 5) sigqueue函数 6) 非法运算等操作
Linux下存在的信号有:
kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX
我们在编程中,如果需要使用异步通信机制的信号技术,就需要借助相应的API来得以实现
1. 信号的安装(设置信号关联动作)
如果进程要处理某一信号,那么就要在进程中安装该信号。安装信号的目的主要有两个
1. 确定信号值: 进程将要处理哪个信号 2. 确定进程针对该信号值的动作之间的映射关系: 该信号被传递给进程时,将执行何种操作
linux主要有两个函数实现信号的安装:
1. signal() #include <signal.h> void (*signal(int signum, void (*handler))(int)))(int); 1) signum: 指定信号的值 2) *handler: 指定针对前面信号值的处理 2.1) 忽略该信号(参数设为SIG_IGN) 2.2) 采用系统默认方式处理信号(参数设为SIG_DFL) 2.3) 自己实现处理方式(参数指定一个函数地址) 如果signal()调用成功,返回最后一次为安装信号signum而调用signal()时的handler值;失败则返回SIG_ERR 2. sigaction() #include <signal.h> int sigaction(int signum, const struct sigaction *act,struct sigaction *oldact)); sigaction函数用于改变进程接收到特定信号后的行为 1) signum: 信号的值,可以为除SIGKILL及SIGSTOP外的任何一个特定有效的信号(为这两个信号定义自己的处理函数,将导致信号安装错误) 2) *act 向结构sigaction的一个实例的指针,在结构sigaction的实例中,指定了对特定信号的处理,可以为空,进程会以缺省方式对信号处理 3) *oldact 指向的对象用来保存原来对相应信号的处理,可指定oldact为NULL。如果把第二、第三个参数都设为NULL,那么该函数可用于检查信号的有效性 在实际的编程中,sigaction()比传统的signal()能发挥更大的作用,对于sigaction()来说,第二个参数*act最为重要,其中包含了对指定信号的处理、信号所传递的信息、信号处理函数执行过程中应屏蔽掉哪些函数等等 sigaction结构定义如下: struct sigaction { /* 指定信号关联函数 除了可以是用户自定义的处理函数外,还可以为SIG_DFL(采用缺省的处理方式),也可以为SIG_IGN(忽略信号) */ union { /* 由_sa_handler指定的处理函数只有一个参数,即信号值,所以信号不能传递除信号值之外的任何信息 */ __sighandler_t _sa_handler; /* 由_sa_sigaction是指定的信号处理函数带有三个参数,是为实时信号而设的(当然同样支持非实时信号),它指定一个3参数信号处理函数 1) 信号值 2) 指向siginfo_t结构的指针 结构中包含信号携带的数据值,参数所指向的结构如下: siginfo_t { int si_signo; /* 信号值,对所有信号有意义*/ int si_errno; /* errno值,对所有信号有意义*/ int si_code; /* 信号产生的原因,对所有信号有意义*/ union {/* 联合数据结构,不同成员适应不同信号 */ //确保分配足够大的存储空间 int _pad[SI_PAD_SIZE]; //对SIGKILL有意义的结构 struct { ... } ... //对SIGILL, SIGFPE, SIGSEGV, SIGBUS有意义的结构 struct { ... } ... } } 3) 第三个参数没有使用(posix没有规范使用该参数的标准) */ void (*_sa_sigaction)(int,struct siginfo *, void *); }_u /* sa_mask 指定在信号处理程序执行过程中,哪些信号应当被阻塞。缺省情况下当前信号本身被阻塞,防止信号的嵌套发送,除非指定SA_NODEFER或者SA_NOMASK标志位 */ sigset_t sa_mask; /* sa_flags 包含了许多标志位,包括 1) A_NODEFER 2) SA_NOMASK 3) SA_SIGINFO: 当设定了该标志位时,表示信号附带的参数可以被传递到信号处理函数中,因此,应该为sigaction结构中的sa_sigaction指定处理函数,而不应该为sa_handler指定信号处理函数,否则,设置该标志变得毫无意义。即
使为sa_sigaction指定了信号处理函数,如果不设置SA_SIGINFO,信号处理函数同样不能得到信号传递过来的数据,在信号处理函数中对这些信息的访问都将导致段错误(Segmentation fault) */ unsigned long sa_flags; void (*sa_restorer)(void); //已过时,POSIX不支持它,不应再被使用 }
2. 信号的发送(触发信号机制)
发送信号的主要函数有:
1. kill() #include <sys/types.h> #include <signal.h> int kill(pid_t pid,int signo) 1) pid: 信号的接收进程 1.1) pid>0: 进程ID为pid的进程 1.2) pid=0: 同一个进程组的进程 1.3) pid<0 pid!=-1: 进程组ID为"-pid"的所有进程 1.4) pid=-1: 除发送进程自身外,所有进程ID大于1的进程 2) Sinno: 信号值 2.1) 0: 即空信号 实际不发送任何信号,但照常进行错误检查,因此,可用于检查目标进程是否存在,以及当前进程是否具有向目标发送信号的2.2) 非0: 发送"kill -l"中列出的信号量 权限(root权限的进程可以向任何进程发送信号,非root权限的进程只能向属于同一个session或者同一个用户的进程发送信号) 2. raise() #include <signal.h> int raise(int signo) 向进程本身发送信号,参数为即将发送的信号值。调用成功返回0、否则,返回 -1 3. sigqueue() #include <sys/types.h> #include <signal.h> int sigqueue(pid_t pid, int sig, const union sigval val) sigqueue()是比较新的发送信号系统调用,主要是针对实时信号提出的(当然也支持前32种),支持信号带有参数,与函数sigaction()配合使用。 1) pid 指定接收信号的进程ID 2) sig 确定即将发送的信号 3) val 是一个联合数据结构union sigval,指定了信号传递的参数,即通常所说的4字节值 typedef union sigval { int sival_int; void *sival_ptr; }sigval_t; sigqueue()比kill()传递了更多的附加信息,但sigqueue()只能向一个进程发送信号,而不能发送信号给一个进程组。如果signo=0,将会执行错误检查,但实际上不发送任何信号,0值信号可用于检查pid的有效性以及当前进程是
否有权限向目标进程发送信号 4. alarm() #include <unistd.h> unsigned int alarm(unsigned int seconds) 专门为SIGALRM信号而设,在指定的时间seconds秒后,将向进程本身发送SIGALRM信号,又称为闹钟时间 1) 进程调用alarm后,任何以前的alarm()调用都将无效 2) 如果参数seconds为零,那么进程内将不再包含任何闹钟时间 返回值,如果调用alarm()前,进程中已经设置了闹钟时间,则返回上一个闹钟时间的剩余时间,否则返回0 5. setitimer() #include <sys/time.h> int setitimer(int which, const struct itimerval *value, struct itimerval *ovalue)); 1) which setitimer()比alarm功能强大,支持3种类型的定时器: 1.1) ITIMER_REAL: 设定绝对时间;经过指定的时间后,内核将发送SIGALRM信号给本进程 1.2) ITIMER_VIRTUAL: 设定程序执行时间;经过指定的时间后,内核将发送SIGVTALRM信号给本进程 1.3) ITIMER_PROF: 设定进程执行以及内核因本进程而消耗的时间和,经过指定的时间后,内核将发送ITIMER_VIRTUAL信号给本进程 2) *value 结构itimerval的一个实例 3) *ovalue 可不做处理 6. abort() #include <stdlib.h> void abort(void); 向进程发送SIGABORT信号,默认情况下进程会异常退出,当然可定义自己的信号处理函数。即使SIGABORT被进程设置为阻塞信号,调用abort()后,SIGABORT仍然能被进程接收。该函数无返回值
3. 信号集及信号集操作API
信号集被定义为一种数据类型: typedef struct { unsigned long sig[_NSIG_WORDS]; } sigset_t 信号集用来描述信号的集合,linux所支持的所有信号可以全部或部分的出现在信号集中,信号集需要和信号阻塞相关函数配合使用。下面是为信号集操作定义的相关函数: #include <signal.h> int sigemptyset(sigset_t *set); int sigfillset(sigset_t *set); int sigaddset(sigset_t *set, int signum); int sigdelset(sigset_t *set, int signum); int sigismember(const sigset_t *set, int signum); sigemptyset(sigset_t *set); //初始化由set指定的信号集,信号集里面的所有信号被清空 sigfillset(sigset_t *set); //调用该函数后,set指向的信号集中将包含linux支持的64种信号 sigaddset(sigset_t *set, int signum); //在set指向的信号集中加入signum信号 sigdelset(sigset_t *set, int signum); //在set指向的信号集中删除signum信号 sigismember(const sigset_t *set, int signum); //判定信号signum是否在set指向的信号集中
4. 信号阻塞与信号未决
我们已经知道了如何在进程中安装信号、在其他进程中发送信号、如何操作信号量,但是在信号机子好的实际运行中,还必须考虑到信号的阻塞与未决问题,即信号发送者即使发出了信号,接受者也未必能立刻接收并响应
每个进程都有一个用来描述哪些信号递送到进程时将被阻塞的信号集,该信号集中的所有信号在递送到进程后都将被阻塞。下面是与信号阻塞相关的几个函数
#include <signal.h> 1. int sigprocmask(int how, const sigset_t *set, sigset_t *oldset)); sigprocmask()函数能够根据参数how来实现对信号集的操作,操作主要有三种 1) SIG_BLOCK: 在进程当前阻塞信号集中添加set指向信号集中的信号 2) SIG_UNBLOCK: 如果进程阻塞信号集中包含set指向信号集中的信号,则解除对该信号的阻塞 3) SIG_SETMASK: 更新进程阻塞信号集为set指向的信号集 2. int sigpending(sigset_t *set)); sigpending(sigset_t *set))获得当前已递送到进程,却被阻塞的所有信号,在set指向的信号集中返回结果 3. int sigsuspend(const sigset_t *mask)); sigsuspend(const sigset_t *mask))用于在接收到某个信号之前, 临时用mask替换进程的信号掩码, 并暂停进程执行,直到收到信号为止 sigsuspend 返回后将恢复调用之前的信号掩码。信号处理函数完成后,进程将继续执行。该系统调用始终返回-1,并将errno设置为EINTR
5. 信号生命周期

1. 信号"诞生" 信号的诞生指的是触发信号的事件发生(如检测到硬件异常、定时器超时以及调用信号发送函数kill()或sigqueue()等) 信号在目标进程中"注册";进程的task_struct结构中有关于本进程中未决信号的数据成员: struct sigpending pending; struct sigpending { /* 分别指向一个sigqueue类型的结构链(称之为"未决信号信息链")的首尾,信息链中的每个sigqueue结构刻画一个特定信号所携带的信息,并指向下一个sigqueue结构: struct sigqueue { struct sigqueue *next; siginfo_t info; } */ struct sigqueue *head, **tail; //进程中所有未决信号集 sigset_t signal; }; 2. 信号在进程中注册 指的就是信号值加入到进程的未决信号集中(sigpending结构的第二个成员sigset_t signal),并且信号所携带的信息被保留到未决信号信息链的某个sigqueue结构中。只要信号在进程的未决信号集中,表明进程已经知道这些信号的
存在,但还没来得及处理,或者该信号被进程阻塞 注: 当一个实时信号发送给一个进程时,不管该信号是否已经在进程中注册,都会被再注册一次,因此,信号不会丢失,因此,实时信号又叫做"可靠信号"。这意味着同一个实时信号可以在同一个进程的未决信号信息链中占有多个sigqueue
结构(进程每收到一个实时信号,都会为它分配一个结构来登记该信号信息,并把该结构添加在未决信号链尾,即所有诞生的实时信号都会在目标进程中注册); 当一个非实时信号发送给一个进程时,如果该信号已经在进程中注册,则该信号将被丢弃,造成信号丢失。因此,非实时信号又叫做"不可靠信号"。这意味着同一个非实时信号在进程的未决信号信息链中,至多占有一个sigqueue结构
(一个非实时信号诞生后,(1)、如果发现相同的信号已经在目标结构中注册,则不再注册,对于进程来说,相当于不知道本次信号发生,信号丢失;(2)、如果进程的未决信号中没有相同信号,则在进程中注册自己)。 3. 信号在进程中的注销 在目标进程执行过程中,会检测是否有信号等待处理(每次从系统空间返回到用户空间时都做这样的检查)。如果存在未决信号等待处理且该信号没有被进程阻塞,则在运行相应的信号处理函数前,进程会把信号在未决信号链中占有的结构
卸掉。是否将信号从进程未决信号集中删除对于实时与非实时信号是不同的。 1) 对于非实时信号来说,由于在未决信号信息链中最多只占用一个sigqueue结构,因此该结构被释放后,应该把信号在进程未决信号集中删除(信号注销完毕) 2) 对于实时信号来说,可能在未决信号信息链中占用多个sigqueue结构,因此应该针对占用sigqueue结构的数目区别对待:如果只占用一个sigqueue结构(进程只收到该信号一次),则应该把信号在进程的未决信号集中删除
(信号注销完毕)。否则,不应该在进程的未决信号集中删除该信号(信号注销完毕) 进程在执行信号相应处理函数之前,首先要把信号在进程中注销。 4. 信号生命终止 进程注销信号后,立即执行相应的信号处理函数,执行完毕后,信号的本次发送对进程的影响彻底结束。
6. 利用操作系统提供的原生系统调用进行信号机制编程
从总体框架上来说,linux下的信号的编程需要完成3件事
1. 安装信号(推荐使用sigaction()) 2. 实现三参数信号处理函数,handler(int signal,struct siginfo *info, void *); 3. 发送信号,推荐使用sigqueue()
code:
#include <signal.h> #include <sys/types.h> #include <unistd.h> #include <stdio.h> void new_op(int,siginfo_t*,void*); int main(int argc,char**argv) { struct sigaction act; int sig; sig=atoi(argv[1]); sigemptyset(&act.sa_mask); act.sa_flags=SA_SIGINFO; act.sa_sigaction=new_op; if(sigaction(sig,&act,NULL) < 0) { printf("install sigal error\n"); } while(1) { sleep(2); printf("wait for the signal\n"); } } void new_op(int signum,siginfo_t *info,void *myact) { printf("receive signal %d", signum); sleep(5); }
Relevant Link:
http://www.tldp.org/LDP/tlk/ipc/ipc.html http://www.ibm.com/developerworks/cn/linux/l-ipc/part2/index1.html http://www.ibm.com/developerworks/cn/linux/l-ipc/part2/index2.html
0x2: 管道(Pipes)
进程间通信(IPC)的另一种技术是管道(pipes)技术,要完全理解linux系统下的管道机制并不容易,因为我们可能会发现,在程序编程和shell指令中,我们都可以见到管道的身影,从本质上来说,它们都是调用了linux底层的文件系统pipefs来进行实现的,我们需要先了解几个基本概念
1. pipe是单向的 2. pipe没有对应的disk image,只有inode,当创建一个pipe时,实际上是创建了一个inode和两个file object 1) pipe属于pipefs文件系统 2) 两个file object分别对应于读端、和写端 3. pipefs这个特殊的文件系统在VFS的目录中是没有的,用户不可见,它是在kernel初始化时进行创建并且挂载到VFS上的
管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候(只要有一个存在,管道就不会消失),管道也自动消失
值得注意的是,在Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的
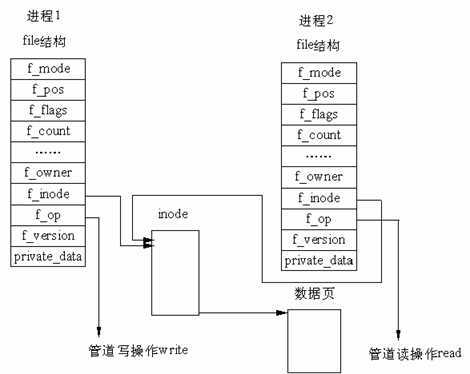
关于fiel、inode的详细数据结构,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html 搜索: "文件系统相关数据结构"
从上面这张图我们可以看到,有两个 file 数据结构,但它们定义文件操作例程地址是不同的,其中一个是向管道中写入数据的例程地址,而另一个是从管道中读出数据的例程地址。这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊操作
管道实现的源代码在fs/pipe.c中,在pipe.c中有很多函数,其中有两个函数比较重要,即管道读函数pipe_read()和管道写函数pipe_wrtie()
linux-2.6.32.63\fs\pipe.c
1. static ssize_t pipe_write(struct kiocb *iocb, const struct iovec *_iov, unsigned long nr_segs, loff_t ppos) 管道写函数通过将字节复制到VFS索引节点指向的物理内存而写入数据,当然,内核必须利用一定的机制同步对管道的访问,为此,内核使用了锁、等待队列和信号。 当写进程向管道中写入时,它利用标准的库函数write(),系统根据库函数传递的文件描述符,可找到该文件的file结构。file结构中指定了用来进行写操作的函数(file_operations->...)地址,于是,内核调用该函数完成写操作。
写入函数在向内存中写入数据之前,必须首先检查VFS索引节点中的信息,同时满足如下条件时,才能进行实际的内存复制工作: 1) 内存中有足够的空间可容纳所有要写入的数据 2) 内存没有被读程序锁定(pipe会阻塞的主要原因) 如果同时满足上述条件,将开始执行管道的读写草走 1) 写入函数首先锁定内存 2) 然后从写进程的地址空间中复制数据到内存。否则,写入进程就休眠在VFS索引节点的等待队列中 3) 接下来,内核将调用调度程序,而调度程序会选择其他进程运行。写入进程实际处于可中断的等待状态 4) 当内存中有足够的空间可以容纳写入数据,或内存被解锁时,读取进程会唤醒写入进程 5) 这时,写入进程将接收到信号 6) 当数据写入内存之后,内存被解锁,而所有休眠在索引节点的读取进程会被唤醒 2. static ssize_t pipe_read(struct kiocb *iocb, const struct iovec *_iov, unsigned long nr_segs, loff_t pos) 管道读函数则通过复制VFS索引节点指向的物理内存中的的字节而读出数据,当然,内核必须利用一定的机制同步对管道的访问,为此,内核使用了锁、等待队列和信号 管道的读取过程和写入过程类似。但是,进程可以在没有数据或内存被锁定时立即返回错误信息,而不是阻塞该进程,这依赖于文件或管道的打开模式。反之,进程可以休眠在索引节点的等待队列中等待写入进程写入数据。当所有的进程
完成了管道操作之后,管道的索引节点被丢弃,而共享数据页也被释放
1. Bash命令下的管道命令执行过程
ls | more
1. shell创建一个pipe,linux系统为其创建了: 1) 1个inode: pipe在底层创建了VFS上的一个inode,这是特殊的文件系统 2) 2个file descriptor 2.1) 3: 负责读端的file descriptor 2.2) 4: 负责写端的file descriptor 2. shell fork出两个子进程 1) ls进程 2) more进程 这两个子进程同时继承了父进程的文件描述符,也就是说,他们同样有3和4 3. 第一个子进程(ls)调用dup2(4, 1)进行句柄复制,将原本ls的输出"1: 标准输出"替换为了"4: pipe file descriptor 管道写端",简单来说就是进程ls的输出被重定向到了管道pipe的写端中 4. 子进程(shell执行fork得到的ls子进程)执行execve(),由于execve也是用的同一个文件描述符表,所以此时ls的输出实际上是pipe的写端 5. 第二个子进程(more)调用dup2(3, 0)进行句柄复制,将原本more的输入"0: 标准输入"替换为了"3: pipe file descriptor 管道读端",简单来说就似乎进程more的输入被重定向到了管道pipe的读端中 6. 子进程(shell执行fork得到的more子进程)执行execve(),由于execve也是用的同一个文件描述符表,more的输入实际上是pipe的读端 7. 于是,ls的输出就顺利的重定向到more的输入了
管道命令"|"将一个进程的输出用作另一个进程的输入,管道负责数据的传输。管道是用于交换数据的连接,一个进程向管道的一端供给数据,另一个在管道另一端取出数据(这个过程只能是单向的),通过管道机制,可见将一系列的进程连接起来
2. 编程中的管道执行过程
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <errno.h> #include <sys/types.h> #include <sys/wait.h> #define BUFFER 255 int main(int argc, char **argv) { char buffer[BUFFER + 1]; int fd[2]; if (argc != 2) { fprintf(stderr, "Usage:%s string\n\a", argv[0]); exit(1); } if (pipe(fd) != 0) { fprintf(stderr, "Pipe Error:%s\n\a", strerror(errno)); exit(1); } //父进程向管道写入 if (fork() == 0) { close(fd[0]); printf("Child[%d] Write to pipe\n\a", getpid()); snprintf(buffer, BUFFER, "%s", argv[1]); write(fd[1], buffer, strlen(buffer)); printf("Child[%d] Quit\n\a", getpid()); exit(0); } //子进程从管道中读取 else { close(fd[1]); printf("Parent[%d] Read from pipe\n\a", getpid()); memset(buffer, ‘\0‘, BUFFER + 1); read(fd[0], buffer, BUFFER); printf("Parent[%d] Read:%s\n", getpid(), buffer); exit(1); } }

Relevant Link:
http://my.oschina.net/u/158589/blog/54705
http://my.oschina.net/u/158589/blog/69047 http://my.oschina.net/u/158589/blog/55051 http://www.cnblogs.com/biyeymyhjob/archive/2012/11/03/2751593.html http://lobert.iteye.com/blog/1707450 http://www.cnblogs.com/sinohenu/archive/2012/11/22/2783279.html http://www.linuxidc.com/Linux/2008-10/16334p6.htm http://bbs.ednchina.com/BLOG_ARTICLE_1969989.HTM
0x3: 套接字(Sockets)
套接字对象在内核中初始化时返回一个文件描述符(file dicriptor),因此可以像普通文件一样处理套接字(这就是抽象和封装机制带来的好处)(unix的哲学思想: 一切皆文件),和管道不同的是,,套接字的使用范围更广
1. 套接字可以双向使用 2. 套接字还可以用于于通过网络连接的远程系统通信 3. 套接字可以支持本地系统上两个进程之间的通信(mysql就支持socket套接字连接)
也正是因为这些方便的特性,使得套接字的实现成为内核中相当复杂的一部分,因为需要大量抽象机制来隐藏通信的细节,从用户的角度来看,同一个系统上两个本地进程之间的通信、和分别处于两个不同位置的两台计算机上运行的应用程序之间的通信没有太大的区别,就目前而言,几乎所有的应用程序都是采用socket,包括openssl的实现、mysql的通信、主流浏览器的实现都是基于socket的,所以说socket在系统通信领域的应用十分广泛(一切皆socket)
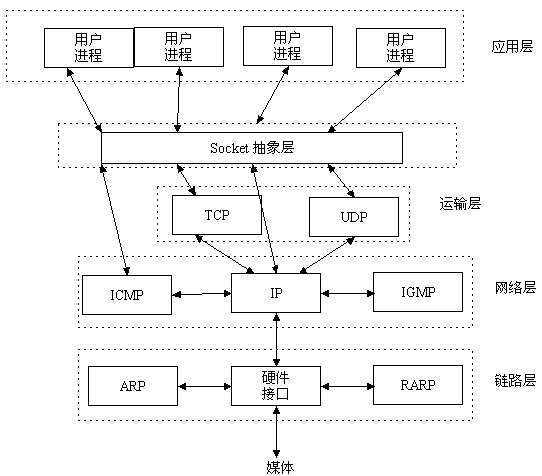
接下来,我们将从tcp socket通信、dp socket通信、本机进程间socket通信这3个方面来学习一下socket的用法、以及相关数据结构,这里不涉及socket的系统调用原理,关于socekt的内核机制原理,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3875451.html
1. TCP SOCKET通信
server.c
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #define MAXLINE 4096 int main(int argc, char** argv) { int listenfd, connfd; /* 1. sockaddr_in: 用来指明地址信息 \linux-2.6.32.63\include\linux\in.h struct sockaddr_in { 1. sin_family指代协议族 1) AF_UNIX, AF_LOCAL: Local communication: unix 2) AF_INET: IPv4 Internet protocols: ip(大多数情况下都是IPV4的socket,所以大多数情况下都是AF_INET) 3) AF_INET6: IPv6 Internet protocols: ipv6 4) AF_IPX: IPX: Novell protocols 5) AF_NETLINK: Kernel user interface device: netlink 6) AF_X25: ITU-T X.25 / ISO-8208 protocol: x25 7) AF_AX25: Amateur radio AX.25 protocol 8) AF_ATMPVC: Access to raw ATM PVCs 9) AF_APPLETALK: Appletalk: ddp 10) AF_PACKET: Low level packet interface: packet sa_family_t sin_family; //2. sin_port存储端口号(需要使用网络字节顺序的数值对齐进行赋值) __be16 sin_port; /* 3. sin_addr存储IP地址(需要使用网络字节顺序的数值对齐进行赋值),使用in_addr这个数据结构 struct in_addr { __be32 s_addr; }; */ struct in_addr sin_addr; /* 4. __pad是为了让sockaddr与sockaddr_in两个数据结构保持大小相同而保留的空字节
\linux-2.6.32.63\include\linux\socket.h
struct sockaddr
{
sa_family_t sa_family;
char sa_data[14];
}; */ unsigned char __pad[__SOCK_SIZE__ - sizeof(short int) - izeof(unsigned short int) - sizeof(struct in_addr)]; }; /**/ struct sockaddr_in servaddr; char buff[4096]; int n; /* int socket(int domain, int type, int protocol); 1. domain 指定socket通信的域,和sockaddr_in.sin_family的意义是一样的 1) AF_UNIX, AF_LOCAL: Local communication: unix(进程间socket通信就是用这个domain) 2) AF_INET: IPv4 Internet protocols: ip(大多数情况下都是IPV4的socket,所以大多数情况下都是AF_INET) 3) AF_INET6: IPv6 Internet protocols: ipv6 4) AF_IPX: IPX: Novell protocols 5) AF_NETLINK: Kernel user interface device: netlink 6) AF_X25: ITU-T X.25 / ISO-8208 protocol: x25 7) AF_AX25: Amateur radio AX.25 protocol 8) AF_ATMPVC: Access to raw ATM PVCs 9) AF_APPLETALK: Appletalk: ddp 10) AF_PACKET: Low level packet interface: packet 2. type 指定通信方式 1) SOCK_STREAM(TCP使用) Provides sequenced, reliable, two-way, connection-based byte streams. An out-of-band data transmission mechanism may be supported. 2) SOCK_DGRAM(UDP使用) Supports datagrams (connectionless, unreliable messages of a fixed maximum length). 3) SOCK_SEQPACKET Provides a sequenced, reliable, two-way connection-based data transmission path for datagrams of fixed maximum length; a consumer is required to read an entire packet with
each input system call. 4) SOCK_RAW Provides raw network protocol access. 5) SOCK_RDM Provides a reliable datagram layer that does not guarantee ordering. 6) SOCK_PACKET Obsolete and should not be used in new programs 3. protocol 大多数情况每种domain下只有一种支持的协议protocol,所以这个字段大多数情况下是0 */ if( (listenfd = socket(AF_INET, SOCK_STREAM, 0)) == -1 ) { printf("create socket error: %s(errno: %d)/n",strerror(errno),errno); exit(0); } memset(&servaddr, 0, sizeof(servaddr)); //sin_family指代协议族,在socket编程中只能是AF_INET servaddr.sin_family = AF_INET; /* 在设置IP、PORT的时候需要注意将"主机字节序"转换为可以在网络上传输的"网络字节序" 字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序,一个字节的数据没有顺序的意义 1. 主机字节序(Little-Endian 小端字节序) 低位字节排放在内存的低地址端,高位字节排放在内存的高地址端 2. 网络字节序(Big-Endian 大端字节序) 高位字节排放在内存的低地址端,低位字节排放在内存的高地址端 4个字节的32 bit值以下面的次序传输:首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit 为了进行转换 bsd socket 提供了转换的函数 有下面四个API 1. htons: 把unsigned short类型从主机序转换到网络序 2. htonl: 把unsigned long类型从主机序转换到网络序 3. ntohs: 把unsigned short类型从网络序转换到主机序 4. ntohl: 把unsigned long类型从网络序转换到主机序 (在使用little endian的系统中 这些函数会把字节序进行转换、在使用big endian类型的系统中 这些函数会定义成空宏) */ /* 在设置网络IP的时候需要调用htonl()将"主机字节顺序(小端字节序 little-endian)"转换为"网络字节顺序(大端字节序 big-endian)" 有以下几种设置IP地址的方式 1. 将字符串点数格式地址转化成NBO inet_aton("132.241.5.10", &myaddr.sin_addr); 2. 将字符串点数格式地址转化成无符号长整型(unsigned long s_addr s_addr;) myaddr.sin_addr.s_addr = inet_addr("132.241.5.10"); 3. htons、htonl(Host to Network Short/Long) myaddr.sin_addr.s_addr = htons(INADDR_ANY); myaddr.sin_addr.s_addr = htonl(INADDR_ANY); myaddr.sin_addr.s_addr = INADDR_ANY; 注意!! 1. htons/l和ntohs/l等数字转换都不能用于地址转换,因为地址都是点数格式 2. 地址只能采用数字/字符串转换如inet_aton,inet_ntoa; 3. 唯一可以用于地址转换的htons是针对INADDR_ANY */ servaddr.sin_addr.s_addr = htonl(INADDR_ANY); //在设置端口的时候需要调用htons()将"主机字节顺序(小端字节序 little-endian)"转换为"网络字节顺序(大端字节序 big-endian)" servaddr.sin_port = htons(6666); /* sockaddr和sockaddr_in的相互关系 一般先把sockaddr_in变量赋值后,强制类型转换后传入用sockaddr做参数的函数 1. sockaddr_in用于socket定义和赋值 2. sockaddr用于函数参数 */ /* int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen); bind()函数的作用是把一个地址族中的特定地址赋给socket(可以理解为将设置好的"sockaddr结构体"和设置好的"socket描述符"连接起来) 1. sockfd: socket描述符 2. sockaddr: 设置好的地址信息结构体 3. addrlen: sockaddr的字节数 通常服务器在启动的时候都会绑定一个众所周知的地址(如ip地址+端口号),用于提供服务,客户就可以通过它来接连服务器;而客户端就不用指定,有系统自动分配一个端口号和自身的ip地址组合。这就是为什么通常服务器端在
listen之前会调用bind(),而客户端就不会调用,而是在connect()时由系统随机生成一个 */ if( bind(listenfd, (struct sockaddr*)&servaddr, sizeof(servaddr)) == -1) { printf("bind socket error: %s(errno: %d)/n",strerror(errno),errno); exit(0); } /* int listen(int sockfd, int backlog); 1. sockfd 要监听的socket描述字 2. backlog 设置相应socket可以排队的最大连接个数 socket()函数创建的socket默认是一个主动类型的(要去向别人发起连接的),listen函数将socket变为被动类型的,等待客户的连接请求 */ if( listen(listenfd, 10) == -1) { printf("listen socket error: %s(errno: %d)/n",strerror(errno),errno); exit(0); } printf("======waiting for client‘s request======/n"); while(1) { /* int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); 1. sockfd sockfd为服务器的socket描述字,是服务器开始调用socket()函数生成的,称为监听socket描述字,一个服务器通常通常仅仅只创建一个监听socket描述字 2. addr 指向struct sockaddr *的指针,用于返回客户端的协议地址 3. addrlen 协议地址的长度 如果accpet成功,那么其返回值是由内核自动生成的一个全新的描述字,代表与返回客户的TCP连接。它在该服务器的生命周期内一直存在,内核为每个由服务器进程接受的客户连接创建了一个已连接socket描述字,当服务
器完成了对某个客户的服务,相应的已连接socket描述字就被关闭 */ if( (connfd = accept(listenfd, (struct sockaddr*)NULL, NULL)) == -1) { printf("accept socket error: %s(errno: %d)",strerror(errno),errno); continue; } /* 当服务器与客户已经建立好连接之后。可以调用网络I/O进行读写操作了,即实现了网咯中不同进程之间的通信 我们知道,linux下所有的东西都是文件,同样,对socket的操作就是对文件的操作,网络I/O操作有下面几组: 1. read()/write() 1) ssize_t read(int fd, void *buf, size_t count); 2) ssize_t write(int fd, const void *buf, size_t count); 2. recv()/send() 1) ssize_t send(int sockfd, const void *buf, size_t len, int flags); 2) ssize_t recv(int sockfd, void *buf, size_t len, int flags); 3. readv()/writev():TCP常用 1) ssize_t readv(int fd, const struct iovec *iov, int iovcnt); 2) ssize_t writev(int fd, const struct iovec *iov, int iovcnt); 4. recvmsg()/sendmsg() 1) ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags); 2) ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags); 5. recvfrom()/sendto(): UDP常用 1) ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen); 2) ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen); */ n = recv(connfd, buff, MAXLINE, 0); buff[n] = ‘/0‘; printf("recv msg from client: %s/n", buff); close(connfd); } close(listenfd); }
client.c
#include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <arpa/inet.h> #include <netdb.h> #include <unistd.h> //以下头文件是为了使样例程序正常运行 #include <string.h> #include <stdio.h> #include <stdlib.h> int main(int argc, char const *argv[]) { struct sockaddr_in pin; /* struct hostent { char *h_name; //official name of host char **h_aliases; //alias list int h_addrtype; //host address type int h_length; //length of address char **h_addr_list; //list of addresses } #define h_addr h_addr_list[0] //for backward compatibility */ struct hostent *nlp_host; int sd; char host_name[256]; int port; /* 初始化主机名和端口。主机名可以是IP,也可以是可被解析的名称 1. strcpy(host_name,"115.239.210.27"); //strcpy(host_name,"www.baidu.com"); strcpy(host_name,"1945096731"); */ strcpy(host_name, "127.0.0.1"); port = 8000; /* 有以下几种设置IP地址的方式 1. 将字符串点数格式地址转化成NBO inet_aton("132.241.5.10", &myaddr.sin_addr); 2. 将字符串点数格式地址转化成无符号长整型(unsigned long s_addr s_addr;) myaddr.sin_addr.s_addr = inet_addr("132.241.5.10"); 3. htons、htonl(Host to Network Short/Long) myaddr.sin_addr.s_addr = htons(INADDR_ANY); myaddr.sin_addr.s_addr = htonl(INADDR_ANY); myaddr.sin_addr.s_addr = INADDR_ANY; 4. 使用gethostbyname进行IP设置 使用gethostbyname(),可以针对各种不同的畸形域名、IP、进行统一的赋值,在gethostbyname()中会自动对输入值进行智能判断 http://lcx.cc/?i=4409 struct hostent *nlp_host; name == IP地址、域名、10进制/16进制的IP地址 nlp_host = gethostbyname(host_name); myaddr.sin_addr.s_addr = ((struct in_addr *)(nlp_host->h_addr))->s_addr; */ while ((nlp_host = gethostbyname(host_name))==0) { printf("Resolve Error!\n"); } bzero(&pin,sizeof(pin)); pin.sin_family = AF_INET; //AF_INET表示使用IPv4 pin.sin_addr.s_addr = ((struct in_addr *)(nlp_host->h_addr))->s_addr; pin.sin_port = htons(port); /* 建立tcp socket连接 */ sd = socket(AF_INET, SOCK_STREAM ,0); /* 建立连接 int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen); 建立tcp socket 1. sockfd 要监听的socket描述字 2. addr 待连接目标server的信息 3. addrlen 相应的addr的字节数 客户端通过调用connect函数来建立与TCP服务器的连接 */ while (connect(sd,(struct sockaddr*)&pin,sizeof(pin))==-1) { printf("Connect Error!\n"); } return 0; }
2. UDP SOCKET通信
server.c
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <errno.h> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <string.h> #define ERR_EXIT(m) do { perror(m); exit(EXIT_FAILURE); } while (0) void echo_ser(int sock) { char recvbuf[1024] = {0}; struct sockaddr_in peeraddr; socklen_t peerlen; int n; while (1) { peerlen = sizeof(peeraddr); memset(recvbuf, 0, sizeof(recvbuf)); //ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen); n = recvfrom(sock, recvbuf, sizeof(recvbuf), 0, (struct sockaddr *)&peeraddr, &peerlen); if (n == -1) { if (errno == EINTR) { continue; } ERR_EXIT("recvfrom error"); } else if(n > 0) { fputs(recvbuf, stdout); //ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen); sendto(sock, recvbuf, n, 0, (struct sockaddr *)&peeraddr, peerlen); } } close(sock); } int main(void) { int sock; if ((sock = socket(AF_INET, SOCK_DGRAM, 0)) < 0) { ERR_EXIT("socket error"); } struct sockaddr_in servaddr; memset(&servaddr, 0, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_port = htons(5188); servaddr.sin_addr.s_addr = htonl(INADDR_ANY); //对于UDP的server来说,bind将指定的ip/port绑定之后,就相当于监听这个端口了(因为UDP是无连接协议) if (bind(sock, (struct sockaddr *)&servaddr, sizeof(servaddr)) < 0) { ERR_EXIT("bind error"); } echo_ser(sock); return 0; }
client.c
#include <unistd.h> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <stdlib.h> #include <stdio.h> #include <errno.h> #include <string.h> #define ERR_EXIT(m) do { perror(m); exit(EXIT_FAILURE); } while(0) void echo_cli(int sock) { struct sockaddr_in servaddr; memset(&servaddr, 0, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_port = htons(5188); /* 有以下几种设置IP地址的方式 1. 将字符串点数格式地址转化成NBO inet_aton("132.241.5.10", &myaddr.sin_addr); 2. 将字符串点数格式地址转化成无符号长整型(unsigned long s_addr s_addr;) myaddr.sin_addr.s_addr = inet_addr("132.241.5.10"); 3. htons、htonl(Host to Network Short/Long) myaddr.sin_addr.s_addr = htons(INADDR_ANY); myaddr.sin_addr.s_addr = htonl(INADDR_ANY); myaddr.sin_addr.s_addr = INADDR_ANY; 4. 使用gethostbyname进行IP设置 使用gethostbyname(),可以针对各种不同的畸形域名、IP、进行统一的赋值,在gethostbyname()中会自动对输入值进行智能判断 http://lcx.cc/?i=4409 struct hostent *nlp_host; name == IP地址、域名、10进制/16进制的IP地址 nlp_host = gethostbyname(host_name); myaddr.sin_addr.s_addr = ((struct in_addr *)(nlp_host->h_addr))->s_addr; */ servaddr.sin_addr.s_addr = inet_addr("127.0.0.1"); int ret; char sendbuf[1024] = {0}; char recvbuf[1024] = {0}; while (fgets(sendbuf, sizeof(sendbuf), stdin) != NULL) { //ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen); sendto(sock, sendbuf, strlen(sendbuf), 0, (struct sockaddr *)&servaddr, sizeof(servaddr)); //ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen); ret = recvfrom(sock, recvbuf, sizeof(recvbuf), 0, NULL, NULL); if (ret == -1) { if (errno == EINTR) { continue; } ERR_EXIT("recvfrom"); } fputs(recvbuf, stdout); memset(sendbuf, 0, sizeof(sendbuf)); memset(recvbuf, 0, sizeof(recvbuf)); } close(sock); } int main(void) { int sock; //建立udp socket if ((sock = socket(AF_INET, SOCK_DGRAM, 0)) < 0) { ERR_EXIT("socket"); } echo_cli(sock); return 0; }
3. 本机进程间SOCKET通信
server.c
//s_unix.c #include <stdio.h> #include <sys/types.h> #include <sys/socket.h> #include <sys/un.h> #define UNIX_DOMAIN "/tmp/UNIX.domain" int main(void) { socklen_t clt_addr_len; int listen_fd; int com_fd; int ret; int i; static char recv_buf[1024]; int len; /* 这是在使用socket进行进程间通信时会使用到的数据结构 struct sockaddr_un { // PF_UNIX或AF_UNIX sa_family_t sun_family; // 路径名 char sun_path[UNIX_PATH_MAX]; }; */ struct sockaddr_un clt_addr; struct sockaddr_un srv_addr; /* 创建一个进程间双向可靠通信socket(AF_UNIX) */ listen_fd = socket(AF_UNIX, SOCK_STREAM, 0); if(listen_fd < 0) { perror("cannot create communication socket"); return 1; } //set server addr_param srv_addr.sun_family = AF_UNIX; strncpy(srv_addr.sun_path, UNIX_DOMAIN, sizeof(srv_addr.sun_path)-1); unlink(UNIX_DOMAIN); /* bind sockfd & addr 1. struct sockaddr是通用的套接字地址 2. struct sockaddr_in则是internet环境下套接字的地址形式 3. sockaddr_un是UNIX进程间通信使用的套接字的地址形式 它们长度一样,都是16个字节。是并列结构,指向sockaddr_in结构的指针也可以指向sockaddr、sockaddr_un 4. 一般情况下,需要把sockaddr_in、sockaddr_un结构强制转换成sockaddr结构再传入系统调用函数中 */ ret = bind(listen_fd,(struct sockaddr*)&srv_addr,sizeof(srv_addr)); if(ret==-1) { perror("cannot bind server socket"); close(listen_fd); unlink(UNIX_DOMAIN); return 1; } //listen sockfd ret=listen(listen_fd,1); if(ret==-1) { perror("cannot listen the client connect request"); close(listen_fd); unlink(UNIX_DOMAIN); return 1; } //have connect request use accept len = sizeof(clt_addr); com_fd = accept(listen_fd,(struct sockaddr*)&clt_addr, &len); if(com_fd < 0) { perror("cannot accept client connect request"); close(listen_fd); unlink(UNIX_DOMAIN); return 1; } //read and printf sent client info printf("/n=====info=====/n"); for(i = 0; i < 4; i++) { memset(recv_buf,0,1024); //ssize_t read(int fd, void *buf, size_t count); int num = read(com_fd, recv_buf, sizeof(recv_buf)); printf("Message from client (%d)) :%s/n",num,recv_buf); } close(com_fd); close(listen_fd); unlink(UNIX_DOMAIN); return 0; }
client.c
//c_unix.c #include <stdio.h> #include <sys/types.h> #include <sys/socket.h> #include <sys/un.h> #define UNIX_DOMAIN "/tmp/UNIX.domain" int main(void) { int connect_fd; int ret; char snd_buf[1024]; int i; static struct sockaddr_un srv_addr; //creat unix socket for ipc communication connect_fd = socket(AF_UNIX, SOCK_STREAM, 0); if(connect_fd<0) { perror("cannot create communication socket"); return 1; } srv_addr.sun_family=AF_UNIX; strcpy(srv_addr.sun_path, UNIX_DOMAIN); //connect server ret = connect(connect_fd, (struct sockaddr*)&srv_addr, sizeof(srv_addr)); if(ret==-1) { perror("cannot connect to the server"); close(connect_fd); return 1; } memset(snd_buf, 0, 1024); strcpy(snd_buf, "message from client"); //send info server for(i=0;i<4;i++) { //ssize_t write(int fd, const void *buf, size_t count); write(connect_fd, snd_buf, sizeof(snd_buf)); } close(connect_fd); return 0; }
Relevant Link:
http://kenby.iteye.com/blog/1149534 http://linux.die.net/man/7/socket http://www.beej.us/guide/bgnet/output/html/multipage/sockaddr_inman.html http://www.gta.ufrj.br/ensino/eel878/sockets/sockaddr_inman.html http://www.cnblogs.com/skynet/archive/2010/12/12/1903949.html http://blog.sina.com.cn/s/blog_6151984a0100etj1.html http://blog.csdn.net/hguisu/article/details/7445768 http://www.ibm.com/developerworks/cn/education/linux/l-sock/l-sock.html http://www.cnblogs.com/hnrainll/archive/2011/04/24/2026432.html 《深入linux内核架构》 12章
0x4 System V通信机制(System V IPC Mechanisms)
3. 多线程并行中的阻塞和同步
未完成
4. Ring3和Ring0的通信机制
开发和维护内核是一件很繁杂的工作,因此,只有那些最重要或者与系统性能息息相关的代码才将其安排在内核中。其它程序,比如GUI,管理以及控制部分的代码,一般都会作为用户态程序。在linux系统中,把系统的某个特性分割成在内核中和在用户空间中分别实现一部分的做法是很常见的(比如linux系统的防火墙就分成了内核态的Netfilter和用户态的iptables)。进行了功能上的分工之后,就需要进行内核和用户态的通信,ring3和ring0的通信技术,大致有如下:
1. Sharing Memory Between Drivers and Applications 2. Sharing Events Between Kernel-User Mode 3. Netlink Socket
0x1: Sharing Memory Between Drivers and Applications
在驱动编程中,我们常常需要在驱动和用户程序间共享内存。可以使用的两种技术方案是:
1. 使用IOCTL共享Buffer(应用程序分配共享内存) 使用一个IOCT描述的Buffer,在驱动和用户程序间共享内存是内存共享最简单的实现形式。使用IOCTL共享的Buffer方,驱动编写者需要注意的的是对于特定的IOCTL采取哪种Buffer method 1) METHOD_XXX_DIRECT(ring3数据传给ring0驱动) 1.1) 在METHOD_XXX_DIRECT模式下,IO管理器为应用层指定的输出缓冲区(OutputBuffer)创建一个MDL锁住该应用层的缓冲区内存 1.2) 内核会检查用户Buffer将被检查是否正确存取,只有检查通过后用户Buffer才会被锁进内存 1.3) 在内核层中使用MmGetSystemAddressForMdlSafe将用户Buffer映射到内核地址空间,并获得应用层输出缓冲区所对应的(mapping)内核层地址 1.3)MDL地址被放在了Irp->MdlAddress中 这种方式的一个优点就是驱动可以在任意进程上下文、任意IRQL优先级别上存取共享内存Buffer 2) METHOD_NEITHER(从驱动返回数据给应用程序或者做双向数据交换)(METHOD_NEITHER不建议使用,还是使用直接IO好) 使用METHOD_NEITHER方式描述一个共享内存Buffer存在许多固有的限制和需要小心的地方。(基本上,在任何时候一个驱动使用这种方式都是一样的)。其中最主要的规则是驱动只能在发起请求进程的上下文中存取Buffer。这是
因为要通过Buffer的用户虚拟地址存取共享内存Buffer。这也就意味着驱动必须要在设备栈的顶端,被用户应用程序经由IO Manager直接调用。期间不能存在中间层驱动或者文件系统驱动在我们的驱动之上。在实际情况下,WDM驱动将
严格限制在其Dispatch例程中存储用户Buffer。而KMDF驱动则需要在EvtIoInCallerContext事件回调函数中使用。 另外一个重要的固有限制就是使用METHOD_NEITHER方式的驱动要存取用户Buffer必须在PASSIVE_LEVEL的IRQL级别。这是因为IO Manager没有把Buffer锁在内存中,因此驱动程序想要存取共享Buffer时,内存可能被换出去
了。如果驱动不能满足这个要求,就需要驱动创建一个mdl,然后将其共享Buffer锁进到内存中。 2. 驱动程序分配共享内存 这种方式是内核来分配内存空间 1) 使用MmAllocatePagesForMDL从主内存池中分配,返回得到一个MDL 2) 驱动为了使用该共享内存,采用MmGetSystemAddressForMdlSafe得到其内核地址 3) 内核调用MmMapLockedPagesSpecifyCache映射到应用层进程地址空间中 4) MmMapLockedPagesSpecifyCache函数返回用户层地址空间的起始地址,将其放在IOCTL中返回给用户应用程序 5) 在用户程序使用完这部分内存之后,内核调用MmFreePageFromMdl来释放内存页。并且调用IoFreeMdl来释放由MmAllocatePageForMdl(Ex)创建的MDL
code download:
http://files.cnblogs.com/LittleHann/Sharing_Memory_Between_Drivers_and_Applications.zip
0x2: Sharing Events Between Kernel-User Mode
事件机制可以和"ring3-ring0共享内存"配合使用,创建2个事件,一个用来同步内核对用户态的buffer读写、另一个用来同步用户态对内核buffer的读写
在Kernel-User的通信中使用事件通知机制的流程如下:
1. The user-mode app creates the event, and passes the handle to the event to the driver via an IOCTL; 2. The driver creates an event, and passes the handle to the event to the user mode app via an IOCTL; 3. The user-mode app creates the event with a pre-determined name, which the driver then opens; 4. The driver creates the event with a pre-determined name, which the user-mode app then opens.
code download
http://files.cnblogs.com/LittleHann/Sharing_Events_Between_Kernel-User_Mode.zip
0x3: Netlink技术: communication between kernel and user space with netlink(AF_NETLINK)
netlink socekt是一种用于在内核态和用户态进程之间进行数据传输的特殊的IPC
1. 它通过为内核模块提供一组特殊的API
2. 为用户程序提供了一组标准的socket接口的方式
netlink实现了一种全双工的通讯连接,类似于TCP/IP中使用AF_INET地址族一样,netlink socket使用地址族(socket_family)AF_NETLINK。每一个netlink socket在内核头文件"include/linux/netlink.h"中定义自己的协议类型
netlink的函数声明如下
netlink_socket = socket(AF_NETLINK, socket_type, netlink_family);
参数说明
1. AF_NETLINK netlink使用"AF_NETLINK"地址族 2. socket_type netlink是一种面向数据包的服务 1) SOCK_RAW 2) SOCK_DGRAM 3. netlink_family 当前netlink客户端(连接发起方)需要连接的内核模块/netlink组 1) NETLINK_ROUTE 用户空间的路由守护程序之间的通讯通道,比如BGP,OSPF,RIP以及内核数据转发模块。用户态的路由守护程序通过此类型的协议来更新内核中的路由表 2) NETLINK_W1 Messages from 1-wire subsystem. 3) NETLINK_USERSOCK 接收用户态的socket数据包的协议 Reserved for user-mode socket protocols. 4) NETLINK_FIREWALL 将内核态的netfilter的IPV4数据传送到用户态中所用的协议,被ip_queue这个内核模块使用 5) NETLINK_IP6_FW 将内核态的netfilter的IPV6数据传送到用户态中所用的协议,被ip6_queue这个内核模块使用 6) NETLINK_NETFILTER Netfilter subsystem. 7) NETLINK_INET_DIAG INET socket monitoring. 8) NETLINK_NFLOG 用户态的iptables管理工具和内核中的netfilter模块之间通讯的通道 9) NETLINK_ARPD 用来从用户空间管理内核中的ARP表。 10) NETLINK_XFRM 用于IPsec的通信协议 11) NETLINK_SELINUX SELinux event notifications. 12) NETLINK_ISCSI Open-iSCSI. 13) NETLINK_AUDIT Auditing(审计目的) 14) NETLINK_FIB_LOOKUP Access to FIB lookup from user space. 15) NETLINK_CONNECTOR Kernel connector 16) NETLINK_DNRTMSG DECnet routing messages. 17) NETLINK_KOBJECT_UEVENT Kernel messages to user space. 18) NETLINK_GENERIC Generic netlink family for simplified netlink usage.
下面我们来一起看看如何使用netlink进行编程,以实现kernel和user mode的通信,我们将在代码中的注释中对netlink的api所涉及到的数据结构进行解释
对于netlink的内核编程值得注意的是,一个好的编程实践是采用异步的方式进行ring0和ring3的通信,因为在很多cpu密集型的服务器上常常会在短时间内产生大量的内核事件,这个情况下串联的同步的netlink可能会导致阻塞进行kernel crash,则异步技术是一个较好的解决方案
user_client.c(用户态程序)
#include <sys/stat.h> #include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <sys/socket.h> #include <sys/types.h> #include <string.h> #include <asm/types.h> #include <linux/netlink.h> #include <linux/socket.h> #define NETLINK_TEST 17 #define MAX_PAYLOAD 1024 /* maximum payload size*/ /* 跟TCP/IP中的socket一样,netlink的bind()函数把一个本地socket地址(源socket地址)与一个打开的socket进行关联 netlink的"地址结构体"如下 struct sockaddr_nl { sa_family_t nl_family; unsigned short nl_pad; __u32 nl_pid; __u32 nl_groups; } nladdr; */ struct sockaddr_nl src_addr, dest_addr; /* linux内核的netlink部分总是认为在每个netlink消息体中已经包含了下面的消息头,所以每个应用程序在发送netlink消息之前需要提供这个头信息: struct nlmsghdr { __u32 nlmsg_len; __u16 nlmsg_type; __u16 nlmsg_flags; __u32 nlmsg_seq; __u32 nlmsg_pid; }; */ struct nlmsghdr *nlh = NULL; struct iovec iov; int sock_fd; struct msghdr msg; int main(int argc, char* argv[]) { /* 1. 使用socket()函数创建一个socket */ sock_fd = socket(PF_NETLINK, SOCK_RAW, NETLINK_TEST); /* 2. 初始化消息缓存区结构体 */ memset(&msg, 0, sizeof(msg)); memset(&src_addr, 0, sizeof(src_addr)); src_addr.nl_family = AF_NETLINK; /* sockaddr_nl的nl_pid属性的值可以设置为访问netlink socket的当前进程的PID,nl_pid作为这个netlink socket的本地地址。 应用程序应该选择一个唯一的32位整数来填充nl_pid的值。 */ src_addr.nl_pid = getpid(); /* self pid */ src_addr.nl_groups = 0; /* not in mcast groups */ /* 3. 跟TCP/IP中的socket一样,netlink的bind()函数把一个本地socket地址(源socket地址)与一个打开的socket进行关联 */ bind(sock_fd, (struct sockaddr*)&src_addr, sizeof(src_addr)); /* 4. 为了能够把一个netlink消息发送给内核或者别的用户进程,类似于UDP数据包发送的sendmsg()函数一样,我们需要另外一个结构体 struct sockaddr_nl nladdr作为目的地址。 1) 如果这个netlink消息是发往内核的话,nl_pid属性和nl_groups属性都应该设置为0。 2) 如果这个消息是发往另外一个进程的单点传输消息,nl_pid应该设置为接收者进程的PID,nl_groups应该设置为0, */ memset(&dest_addr, 0, sizeof(dest_addr)); dest_addr.nl_family = AF_NETLINK; dest_addr.nl_pid = 0; /* For Linux Kernel */ dest_addr.nl_groups = 0; /* unicast */ /* 5. netlink消息同样也需要它自身的消息头,这样做是为了给所有协议类型的netlink消息提供一个通用的背景。 由于linux内核的netlink部分总是认为在每个netlink消息体中已经包含了下面的消息头,所以每个应用程序在发送netlink消息之前需要提供这个头信息: */ nlh=(struct nlmsghdr *)malloc(NLMSG_SPACE(MAX_PAYLOAD)); /* Fill the netlink message header */ nlh->nlmsg_len = NLMSG_SPACE(MAX_PAYLOAD); nlh->nlmsg_pid = getpid(); /* self pid */ nlh->nlmsg_flags = 0; /* Fill in the netlink message payload */ strcpy(NLMSG_DATA(nlh), "Hello you!"); /* 6. nlmsg_len需要用netlink 消息体的总长度来填充,包含头信息在内,这个是netlink核心需要的信息。 mlmsg_type可以被应用程序所用,它对于netlink核心来说是一个透明的值。 Nsmsg_flags 用来该对消息体进行另外的控制,会被netlink核心代码读取并更新。 Nlmsg_seq和nlmsg_pid同样对于netlink核心部分来说是透明的,应用程序用它们来跟踪消息。 因此,一个netlink消息体由nlmsghdr和消息的payload部分组成。一旦输入一个消息,它就会进入一个被nlh指针指向的缓冲区。我们同样可以把消息发送个结构体struct msghdr msg: */ iov.iov_base = (void *)nlh; iov.iov_len = nlh->nlmsg_len; msg.msg_name = (void *)&dest_addr; msg.msg_namelen = sizeof(dest_addr); msg.msg_iov = &iov; msg.msg_iovlen = 1; /* 7. 在完成了以上步骤后,调用一次sendmsg()函数就能把netlink消息发送出去: */ sendmsg(sock_fd, &msg, 0); /* Read message from kernel memset(nlh, 0, NLMSG_SPACE(MAX_PAYLOAD)); recvmsg(sock_fd, &msg, 0); printf(" Received message payload: %s\n", NLMSG_DATA(nlh)); */ /* Close Netlink Socket */ close(sock_fd); }
kernel_server.c(内核态程序)
/* 内核空间的netlink API是由内核中的netlink核心代码支持的,在net/core/af_netlink.c中实现。 从内核的角度来说,API接口与用户空间的API是不一样的。内核模块通过这些API访问netlink socket并且与用户空间的程序进行通讯 */ #include <linux/module.h> #include <linux/init.h> #include <linux/types.h> #include <linux/sched.h> #include <net/sock.h> #include <linux/netlink.h> #define NETLINK_TEST 17 struct sock *nl_sk = NULL; /* 回调函数input()是在发送进程的系统调用sendmsg()的上下文被调用的。 如果input函数中处理消息很快的话,一切都没有问题。 但是如果处理netlink消息花费很长时间的话,我们则希望把消息的处理部分放在input()函数的外面,因为长时间的消息处理过程可能会阻止其它系统调用进入内核。取而代之,我们可以牺牲一个内核线程来完成后续的无限的的处理动
作。 */ void input(struct sk_buff *skb) { struct nlmsghdr *nlh = NULL; unsigned char *payload = NULL; /*接收数据打印到内核消息*/ nlh = (struct nlmsghdr *)skb->data; payload = NLMSG_DATA(nlh); printk("%s\n",payload); } static int __init test_netlink(void) { printk("hi,netlink\n"); /* 1. 通过socket()调用来创建一个netlink socket */ nl_sk = netlink_kernel_create(&init_net,NETLINK_TEST,0,input,0,THIS_MODULE); return 0; } static void __exit exit(void) { sock_release(nl_sk->sk_socket); printk("bye,netlink\n"); } module_init(test_netlink); module_exit(exit);
Makefile
MODULE_NAME :=kernel_server obj-m :=$(MODULE_NAME).o KERNELDIR ?= /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) all: $(MAKE) -C $(KERNELDIR) M=$(PWD) gcc -o user_client user_client.c clean: rm -fr *.ko *.o *.cmd user_client
编译并载入内核
make
insmod kernel_server.ko

Relevant Link:
http://man7.org/linux/man-pages/man7/netlink.7.html http://zh.wikipedia.org/zh/Netlink http://bbs.chinaunix.net/thread-2029813-1-1.html http://bbs.chinaunix.net/thread-4078272-1-1.html http://www.cnblogs.com/hoys/archive/2011/04/09/2010788.html http://blog.csdn.net/lovesunshine2008/article/details/4041755 http://www.osronline.com/article.cfm?article=39
5. 远程网络通信
Relevant Link:
Copyright (c) 2014 LittleHann All rights reserved
Linux Communication Mechanism Summarize(undone),布布扣,bubuko.com
Linux Communication Mechanism Summarize(undone)
标签:des style blog http color java 使用 os
原文地址:http://www.cnblogs.com/LittleHann/p/3867214.html