标签:
首先正则表达式是什么?
正则表达式是一个自定义规则的表达式,用来匹配符合定义的规则的字符串。什么意思?比如这是一个正则表达式:/\d/,\d的意思就是任意一个数字,所以这个正则表达式的意思就是匹配一个任意数字。大概明白了吧!
下面我们来看看正则表达式都由些什么东西组成。
| 字符 | 含义 |
| 字母和数字字符 | 自身 |
| \t | 匹配一个水平制表符 |
| \v | 匹配一个垂直制表符 |
| \n | 匹配一个换行符 |
| \f | 匹配一个换页符 |
| \r | 匹配一个回车符 |
| 字符 | 含义 |
| - | 例如a-z表示a-z的26个字母 |
| {n,m} | 匹配前一项n到m次 |
| {n,} | 匹配前一项n次或者更多次 |
| {n} | 匹配前一项n次 |
| * | 匹配前一项任意次 |
| + | 匹配前一项至少一次 |
| ? | 匹配前一项0次或1次 |
什么意思?举个栗子:/[a-z]3{1,3}5+/这个表达式,意思是,任意一个英文字母出现一次,然后出现一到三次数字3,然后数字5至少出现一次。
下面我们在chrome调试工具中用test()方法试一下:
注:test()方法用来检验一个字符串是否匹配某个正则表达式,接收一个参数,即目标字符串,如匹配则返回true,否则返回false
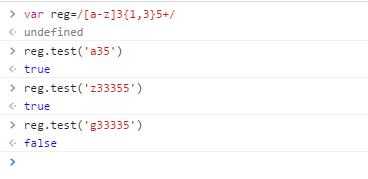
| 字符 | 含义 |
| [...] | 匹配方括号内任意字符 |
| [^...] | 匹配除方括号内字符的其他任意字符 |
| . | 除换行符和行终止符之外的任意字符 |
| \w | 任意单词和下划线,等价于[a-zA-Z0-9_] |
| \W | \w的否定,等价于[^a-zA-Z0-9_] |
| \s | 匹配任意一个空白符 |
| \S | 匹配任意一个非空白符 |
| \d | 任意一个数字,等价于[0-9] |
| \D | 任意一个非数字,等价于[^0-9] |
| [\b] | 退格直接量 |
什么东西,宝宝看不懂啊!让我们看个例子:/[abc]\w\d{2}/,这个表达式的意思是,匹配abc中任意一个,接下来是一个单词([a-zA-Z0-9])或者下划线,然后是两个数字。看图!
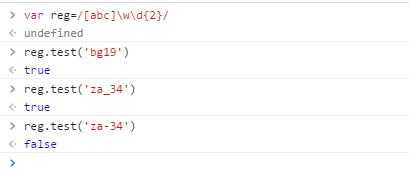
| 字符 | 含义 |
| ^ | 表示以……开头,如^a表示字符串的开头是a字母 |
| $ | 表示以……结尾,如b$表示字符串的结尾是b字母 |
| \b | 单词边界,如/\bis\b/匹配is而不匹配this |
| \B | 非单词边界,如/\Bis\b/可匹配this |
这里说一下^,表示以……开头,我们看个例子:
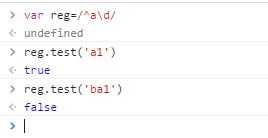
作为对比,这里表达式中没有^
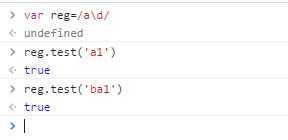
$原理跟^一样,这里不再赘述,只是需要注意一点,$需要写在表达式的最后面。
| 字符 | 含义 |
| g | 全局匹配,即找到所有匹配,而不是找到第一个就停止 |
| i | 不区分大小写 |
| m | 多行匹配 |
在没有g修饰符的情况下,正则表达式匹配到第一项即停止匹配,当有g修饰符时,会找到所有匹配项。我们学习一个正则表达式的新方法replace():
注:replace()方法作用是替换字符串中规定的字符,接收两个参数,第一个参数是一个正则表达式,表示你要替换的内容,第二个参数是一个字符串,表示你要 替换成 的内容。看下面例子!
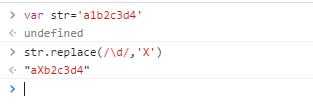
只替换了第一个数字,再看下有g修饰符的情况:
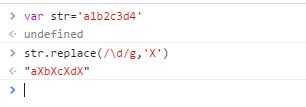
全部数字都被替换了,明白g是干嘛的了吧。
再说i,i修饰符就很简单了,表示不区分大小写,看下面例子:
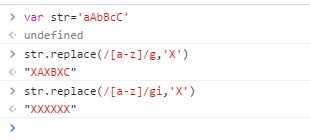
加了i之后,不管大小写字母都被替换了!
最后m表示多行搜索,比如要匹配以字母a开头的字符串,在有m修饰符的情况下,换行后以a开头的行也会被匹配。限于篇幅这里不贴图了。
正则表达式中用圆括号()表示分组,每个()表示一个分组。而分组中的内容用$1、$2……表示,仍然看例子:
比如日期有这两种表示法:月-日-年和年/月/日,怎么把月-日-年换成年/月/日呢?我们看看

在这个例子中,我们给月、日和年分了组,然后再利用$反向引用,于是实现了日期格式的转换。
关于正则表达式的零零碎碎的东西基本讲完了,下面我们开始学习在正则表达式中用到的方法!有两类,一类是正则表达式对象方法,一类是字符串对象方法。
有两个,test()和exec()。test()方法我们学过了,现在讲讲exec()方法。
exec()方法返回一个数组,数组的第一个元素是匹配的文本,第二个元素是匹配文本的第一个子文本,第三个元素是匹配文本的第二个子文本……以此类推。这样很抽象,看下面例子就懂了!
exec()的调用又分两种情况:非全局调用和全局调用。
看下图例子
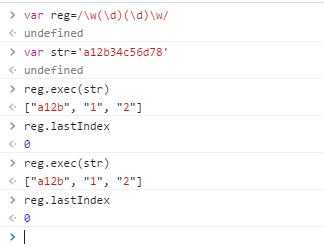
这里我们看到,第一次匹配了"a12b",后面两个元素分别是第一个分组"1"和第二个分组"2"。可是第二次执行exec()方法,匹配的依然是"a12b",这是意料之外的。按理说第二次匹配的应该是"c56d",可是为什么还是"a12b"呢?原因就在lastIndex属性上。lastIndex属性表示上次匹配结果的最后一个字符的下一个字符,但是这属性只在全局调用时(即表达式中加了g修饰符的情况)生效,非全局调用时始终为0。作为对比,我们看看全局调用情况!
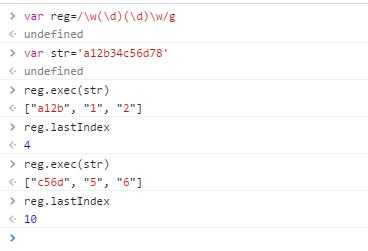
可以看到,第一次执行exec()返回了"a12b",lastIndex为4,即为字符串str中数字3的位置;第二次返回了"c56d",lastIndex为10,即为字符串str中数字7的位置。这时lastIndex起作用了,所以两次执行结果都在意料之中。
字符串对象方法有:search()、replace()、match()、split()。
search()方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。如果匹配到,则返回第一个匹配结果的index,没匹配到则返回-1。接收一个参数,这个参数可以是字符串,也可以是正则表达式。这个方法每次都从字符串的开头开始匹配。我们看下面例子:
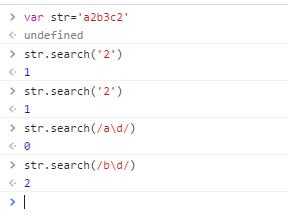
两次搜索数字2返回的index都是1,而不会是第二个数字2的index5。第三和第四次搜索传入一个正则表达式,都返回了相对应的index。
这个方法前面已经学过,这里继续。有这几种形式:replace(str,replaceStr)、replace(RegExp,replaceStr)、replace(RegExp,function)。前面两种比较简单,看个例子就懂了:
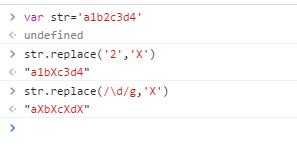
第一次传入字符串,把数字2替换成X,第二次传入正则表达式,把全部数字替换成X。
replace(RegExp,function)方法第二个参数是一个函数,这个方法适用于比较复杂的字符替换,大家有兴趣可以自己找学习资源,这里不作介绍。
match()方法传入一个参数:正则表达式,用来查找字符串中与传入的正则表达式相匹配的文本,如找不到则返回null,如果找到,返回一个数组,这个数组在非全局调用和全局调用时是不一样的,下面分开说。
在非全局调用时,返回的数组是这样的:第一个元素是匹配的文本,第二个元素是匹配文本的第一个子文本,第三个元素是匹配文本的第二个子文本……以此类推。是不是有似曾相识的感觉?没错,这一点和exec()方法一模一样。
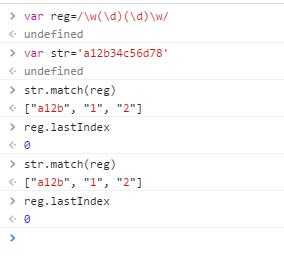
非全局调用时每次查找依然从字符串的开头开始,下面看看全局调用!
在全局调用(即正则表达式中有g修饰符)时,返回的数组是这样的:数组的每一项都是匹配的文本,不再有匹配文本的子文本了。
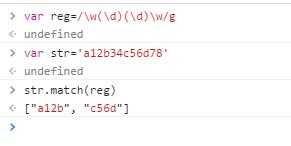
和正则表达式相匹配的"a12b"和"c56d"都出现在数组里了。其实match()方法和exec()方法作用都是一样的,只不过一个由字符串调用,一个由正则表达式调用而已。
split()方法用于把字符串分割成数组,什么意思呢?看下面例子:
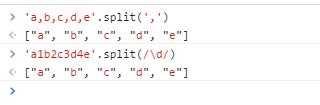
split()方法接收的参数可以是字符串,也可以是正则表达式。从例子可以看到,参数传什么,就在字符串中去掉什么,然后分割成数组。
正则表达式在字符串处理中用的非常频繁,希望大家都能学会并在开发中自如运用,今天就讲到这里,欢迎交流,欢迎指正!
原创文章,转载请注明出处!
标签:
原文地址:http://www.cnblogs.com/cme-kai/p/5942633.html